 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Synthesis from a Single Image via Unsupervised learning
Oct 29, 2021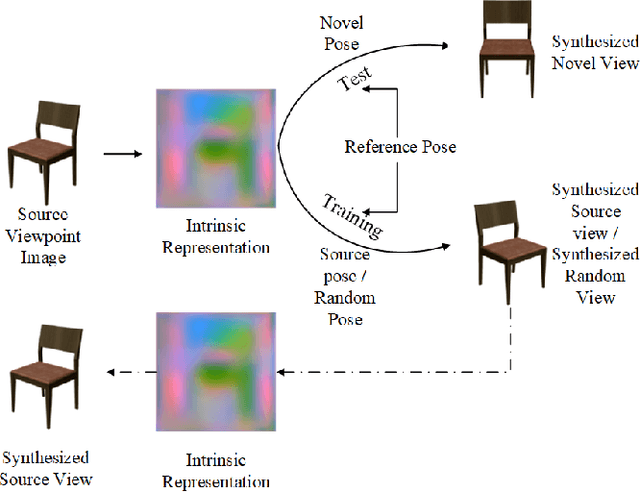
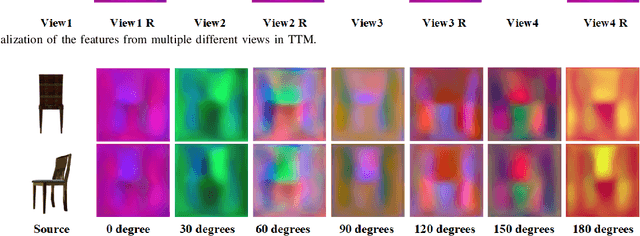
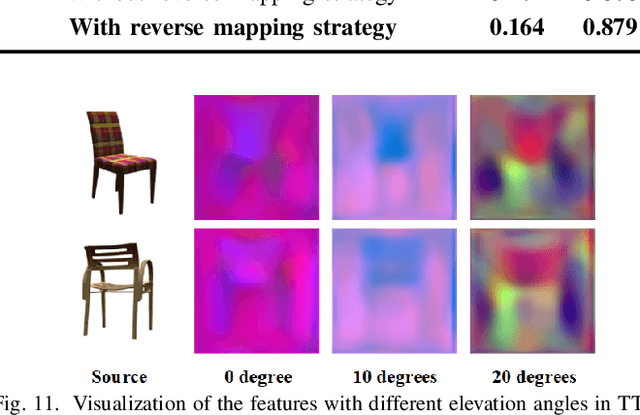

View synthesis aims to generate novel views from one or more given source views. Although existing methods have achieved promising performance, they usually require paired views of different poses to learn a pixel transformation. This paper proposes an unsupervised network to learn such a pixel transformation from a single source viewpoint. In particular, the network consists of a token transformation module (TTM) that facilities the transformation of the features extracted from a source viewpoint image into an intrinsic representation with respect to a pre-defined reference pose and a view generation module (VGM) that synthesizes an arbitrary view from the representation. The learned transformation allows us to synthesize a novel view from any single source viewpoint image of unknown pose. Experiments on the widely used view synthesis datasets have demonstrated that the proposed network is able to produce comparable results to the state-of-the-art methods despite the fact that learning is unsupervised and only a single source viewpoint image is required for generating a novel view. The code will be available soon.