 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase Transition for Stochastic Block Model with more than $\sqrt{n}$ Communities
Sep 19, 2025Predictions from statistical physics postulate that recovery of the communities in Stochastic Block Model (SBM) is possible in polynomial time above, and only above, the Kesten-Stigum (KS) threshold. This conjecture has given rise to a rich literature, proving that non-trivial community recovery is indeed possible in SBM above the KS threshold, as long as the number $K$ of communities remains smaller than $\sqrt{n}$, where $n$ is the number of nodes in the observed graph. Failure of low-degree polynomials below the KS threshold was also proven when $K=o(\sqrt{n})$. When $K\geq \sqrt{n}$, Chin et al.(2025) recently prove that, in a sparse regime, community recovery in polynomial time is possible below the KS threshold by counting non-backtracking paths. This breakthrough result lead them to postulate a new threshold for the many communities regime $K\geq \sqrt{n}$. In this work, we provide evidences that confirm their conjecture for $K\geq \sqrt{n}$: 1- We prove that, for any density of the graph, low-degree polynomials fail to recover communities below the threshold postulated by Chin et al.(2025); 2- We prove that community recovery is possible in polynomial time above the postulated threshold, not only in the sparse regime of~Chin et al., but also in some (but not all) moderately sparse regimes by essentially counting clique occurence in the observed graph.
Low-degree lower bounds via almost orthonormal bases
Sep 11, 2025Low-degree polynomials have emerged as a powerful paradigm for providing evidence of statistical-computational gaps across a variety of high-dimensional statistical models [Wein25]. For detection problems -- where the goal is to test a planted distribution $\mathbb{P}'$ against a null distribution $\mathbb{P}$ with independent components -- the standard approach is to bound the advantage using an $\mathbb{L}^2(\mathbb{P})$-orthonormal family of polynomials. However, this method breaks down for estimation tasks or more complex testing problems where $\mathbb{P}$ has some planted structures, so that no simple $\mathbb{L}^2(\mathbb{P})$-orthogonal polynomial family is available. To address this challenge, several technical workarounds have been proposed [SW22,SW25], though their implementation can be delicate. In this work, we propose a more direct proof strategy. Focusing on random graph models, we construct a basis of polynomials that is almost orthonormal under $\mathbb{P}$, in precisely those regimes where statistical-computational gaps arise. This almost orthonormal basis not only yields a direct route to establishing low-degree lower bounds, but also allows us to explicitly identify the polynomials that optimize the low-degree criterion. This, in turn, provides insights into the design of optimal polynomial-time algorithms. We illustrate the effectiveness of our approach by recovering known low-degree lower bounds, and establishing new ones for problems such as hidden subcliques, stochastic block models, and seriation models.
Computational lower bounds in latent models: clustering, sparse-clustering, biclustering
Jun 16, 2025In many high-dimensional problems, like sparse-PCA, planted clique, or clustering, the best known algorithms with polynomial time complexity fail to reach the statistical performance provably achievable by algorithms free of computational constraints. This observation has given rise to the conjecture of the existence, for some problems, of gaps -- so called statistical-computational gaps -- between the best possible statistical performance achievable without computational constraints, and the best performance achievable with poly-time algorithms. A powerful approach to assess the best performance achievable in poly-time is to investigate the best performance achievable by polynomials with low-degree. We build on the seminal paper of Schramm and Wein (2022) and propose a new scheme to derive lower bounds on the performance of low-degree polynomials in some latent space models. By better leveraging the latent structures, we obtain new and sharper results, with simplified proofs. We then instantiate our scheme to provide computational lower bounds for the problems of clustering, sparse clustering, and biclustering. We also prove matching upper-bounds and some additional statistical results, in order to provide a comprehensive description of the statistical-computational gaps occurring in these three problems.
Active clustering with bandit feedback
Jun 17, 2024
We investigate the Active Clustering Problem (ACP). A learner interacts with an $N$-armed stochastic bandit with $d$-dimensional subGaussian feedback. There exists a hidden partition of the arms into $K$ groups, such that arms within the same group, share the same mean vector. The learner's task is to uncover this hidden partition with the smallest budget - i.e., the least number of observation - and with a probability of error smaller than a prescribed constant $\delta$. In this paper, (i) we derive a non-asymptotic lower bound for the budget, and (ii) we introduce the computationally efficient ACB algorithm, whose budget matches the lower bound in most regimes. We improve on the performance of a uniform sampling strategy. Importantly, contrary to the batch setting, we establish that there is no computation-information gap in the active setting.
Estimating the history of a random recursive tree
Mar 14, 2024This paper studies the problem of estimating the order of arrival of the vertices in a random recursive tree. Specifically, we study two fundamental models: the uniform attachment model and the linear preferential attachment model. We propose an order estimator based on the Jordan centrality measure and define a family of risk measures to quantify the quality of the ordering procedure. Moreover, we establish a minimax lower bound for this problem, and prove that the proposed estimator is nearly optimal. Finally, we numerically demonstrate that the proposed estimator outperforms degree-based and spectral ordering procedures.
Parameter-free projected gradient descent
May 31, 2023

We consider the problem of minimizing a convex function over a closed convex set, with Projected Gradient Descent (PGD). We propose a fully parameter-free version of AdaGrad, which is adaptive to the distance between the initialization and the optimum, and to the sum of the square norm of the subgradients. Our algorithm is able to handle projection steps, does not involve restarts, reweighing along the trajectory or additional gradient evaluations compared to the classical PGD. It also fulfills optimal rates of convergence for cumulative regret up to logarithmic factors. We provide an extension of our approach to stochastic optimization and conduct numerical experiments supporting the developed theory.
Small Total-Cost Constraints in Contextual Bandits with Knapsacks, with Application to Fairness
May 25, 2023
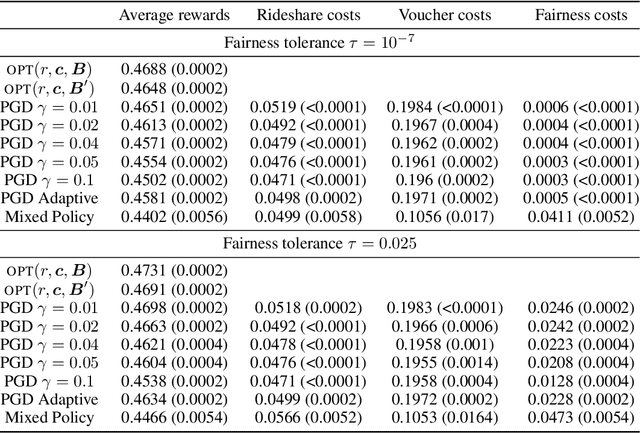
We consider contextual bandit problems with knapsacks [CBwK], a problem where at each round, a scalar reward is obtained and vector-valued costs are suffered. The learner aims to maximize the cumulative rewards while ensuring that the cumulative costs are lower than some predetermined cost constraints. We assume that contexts come from a continuous set, that costs can be signed, and that the expected reward and cost functions, while unknown, may be uniformly estimated -- a typical assumption in the literature. In this setting, total cost constraints had so far to be at least of order $T^{3/4}$, where $T$ is the number of rounds, and were even typically assumed to depend linearly on $T$. We are however motivated to use CBwK to impose a fairness constraint of equalized average costs between groups: the budget associated with the corresponding cost constraints should be as close as possible to the natural deviations, of order $\sqrt{T}$. To that end, we introduce a dual strategy based on projected-gradient-descent updates, that is able to deal with total-cost constraints of the order of $\sqrt{T}$ up to poly-logarithmic terms. This strategy is more direct and simpler than existing strategies in the literature. It relies on a careful, adaptive, tuning of the step size.
The price of unfairness in linear bandits with biased feedback
Mar 18, 2022
Artificial intelligence is increasingly used in a wide range of decision making scenarios with higher and higher stakes. At the same time, recent work has highlighted that these algorithms can be dangerously biased, and that their results often need to be corrected to avoid leading to unfair decisions. In this paper, we study the problem of sequential decision making with biased linear bandit feedback. At each round, a player selects an action described by a covariate and by a sensitive attribute. She receives a reward corresponding to the covariates of the action that she has chosen, but only observe a biased evaluation of this reward, where the bias depends on the sensitive attribute. To tackle this problem, we design a Fair Phased Elimination algorithm. We establish an upper bound on its worst-case regret, showing that it is smaller than C$\kappa$ 1/3 * log(T) 1/3 T 2/3 , where C is a numerical constant and $\kappa$ * an explicit geometrical constant characterizing the difficulty of bias estimation. The worst case regret is higher than the dT 1/2 log(T) regret rate obtained under unbiased feedback. We show that this rate cannot be improved for all instances : we obtain lower bounds on the worst-case regret for some sets of actions showing that this rate is tight up to a sub-logarithmic factor. We also obtain gap-dependent upper bounds on the regret, and establish matching lower bounds for some problem instance. Interestingly, the gap-dependent rates reveal the existence of non-trivial instances where the problem is no more difficult than its unbiased counterpart.
Training Integrable Parameterizations of Deep Neural Networks in the Infinite-Width Limit
Oct 29, 2021
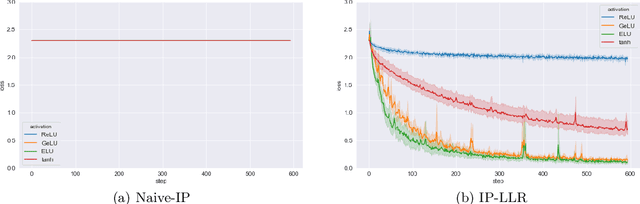

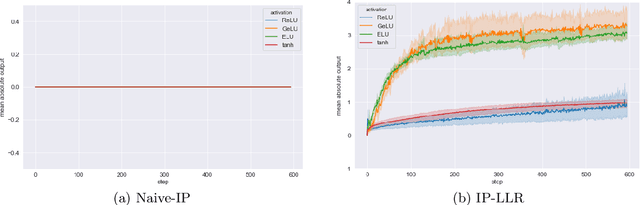
To theoretically understand the behavior of trained deep neural networks, it is necessary to study the dynamics induced by gradient methods from a random initialization. However, the nonlinear and compositional structure of these models make these dynamics difficult to analyze. To overcome these challenges, large-width asymptotics have recently emerged as a fruitful viewpoint and led to practical insights on real-world deep networks. For two-layer neural networks, it has been understood via these asymptotics that the nature of the trained model radically changes depending on the scale of the initial random weights, ranging from a kernel regime (for large initial variance) to a feature learning regime (for small initial variance). For deeper networks more regimes are possible, and in this paper we study in detail a specific choice of "small" initialization corresponding to ''mean-field'' limits of neural networks, which we call integrable parameterizations (IPs). First, we show that under standard i.i.d. zero-mean initialization, integrable parameterizations of neural networks with more than four layers start at a stationary point in the infinite-width limit and no learning occurs. We then propose various methods to avoid this trivial behavior and analyze in detail the resulting dynamics. In particular, one of these methods consists in using large initial learning rates, and we show that it is equivalent to a modification of the recently proposed maximal update parameterization $\mu$P. We confirm our results with numerical experiments on image classification tasks, which additionally show a strong difference in behavior between various choices of activation functions that is not yet captured by theory.
Localization in 1D non-parametric latent space models from pairwise affinities
Aug 06, 2021



We consider the problem of estimating latent positions in a one-dimensional torus from pairwise affinities. The observed affinity between a pair of items is modeled as a noisy observation of a function $f(x^*_{i},x^*_{j})$ of the latent positions $x^*_{i},x^*_{j}$ of the two items on the torus. The affinity function $f$ is unknown, and it is only assumed to fulfill some shape constraints ensuring that $f(x,y)$ is large when the distance between $x$ and $y$ is small, and vice-versa. This non-parametric modeling offers a good flexibility to fit data. We introduce an estimation procedure that provably localizes all the latent positions with a maximum error of the order of $\sqrt{\log(n)/n}$, with high-probability. This rate is proven to be minimax optimal. A computationally efficient variant of the procedure is also analyzed under some more restrictive assumptions. Our general results can be instantiated to the problem of statistical seriation, leading to new bounds for the maximum error in the ordering.