 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Learning for Neural Ambisonics Encoders
Jan 26, 2026Emerging wearable devices such as smartglasses and extended reality headsets demand high-quality spatial audio capture from compact, head-worn microphone arrays. Ambisonics provides a device-agnostic spatial audio representation by mapping array signals to spherical harmonic (SH) coefficients. In practice, however, accurate encoding remains challenging. While traditional linear encoders are signal-independent and robust, they amplify low-frequency noise and suffer from high-frequency spatial aliasing. On the other hand, neural network approaches can outperform linear encoders but they often assume idealized microphones and may perform inconsistently in real-world scenarios. To leverage their complementary strengths, we introduce a residual-learning framework that refines a linear encoder with corrections from a neural network. Using measured array transfer functions from smartglasses, we compare a UNet-based encoder from the literature with a new recurrent attention model. Our analysis reveals that both neural encoders only consistently outperform the linear baseline when integrated within the residual learning framework. In the residual configuration, both neural models achieve consistent and significant improvements across all tested metrics for in-domain data and moderate gains for out-of-domain data. Yet, coherence analysis indicates that all neural encoder configurations continue to struggle with directionally accurate high-frequency encoding.
Perceptually-motivated Spatial Audio Codec for Higher-Order Ambisonics Compression
Jan 24, 2024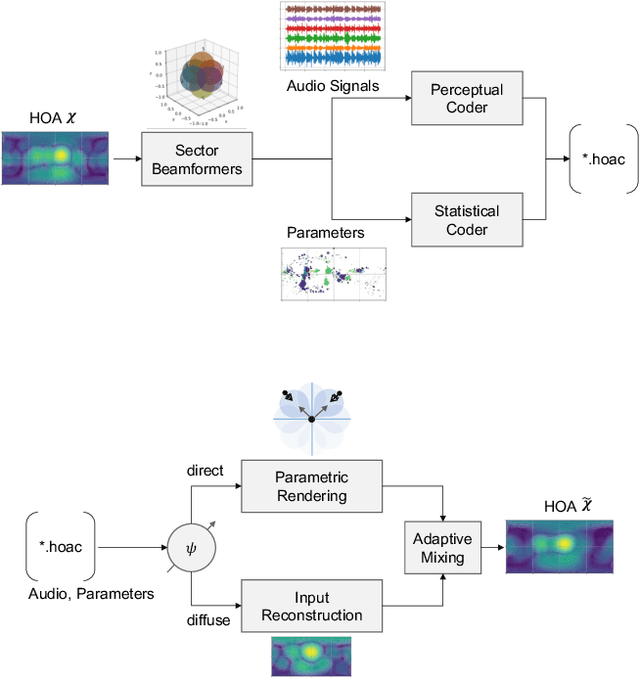
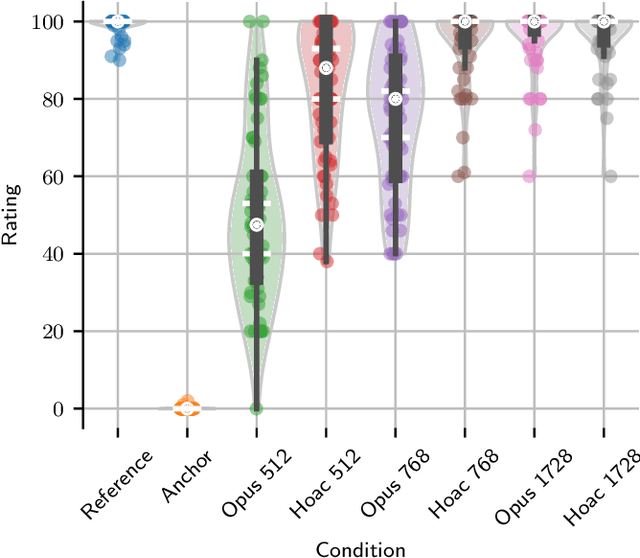
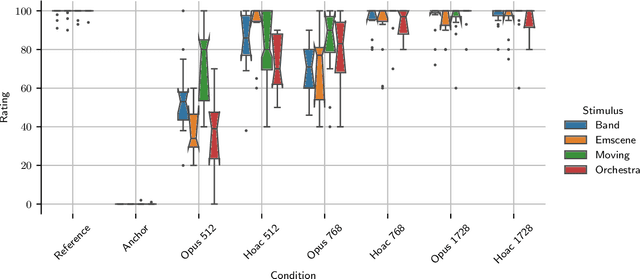
Scene-based spatial audio formats, such as Ambisonics, are playback system agnostic and may therefore be favoured for delivering immersive audio experiences to a wide range of (potentially unknown) devices. The number of channels required to deliver high spatial resolution Ambisonic audio, however, can be prohibitive for low-bandwidth applications. Therefore, this paper proposes a compression codec, which is based upon the parametric higher-order Directional Audio Coding (HO-DirAC) model. The encoder downmixes the higher-order Ambisonic (HOA) input audio into a reduced number of signals, which are accompanied by perceptually-motivated scene parameters. The downmixed audio is coded using a perceptual audio coder, whereas the parameters are grouped into perceptual bands, quantized, and downsampled. On the decoder side, low Ambisonic orders are fully recovered. Not fully recoverable HOA components are synthesized according to the parameters. The results of a listening test indicate that the proposed parametric spatial audio codec can improve the adopted perceptual audio coder, especially at low to medium-high bitrates, when applied to fifth-order HOA signals.
Dataset of Spatial Room Impulse Responses in a Variable Acoustics Room for Six Degrees-of-Freedom Rendering and Analysis
Nov 23, 2021

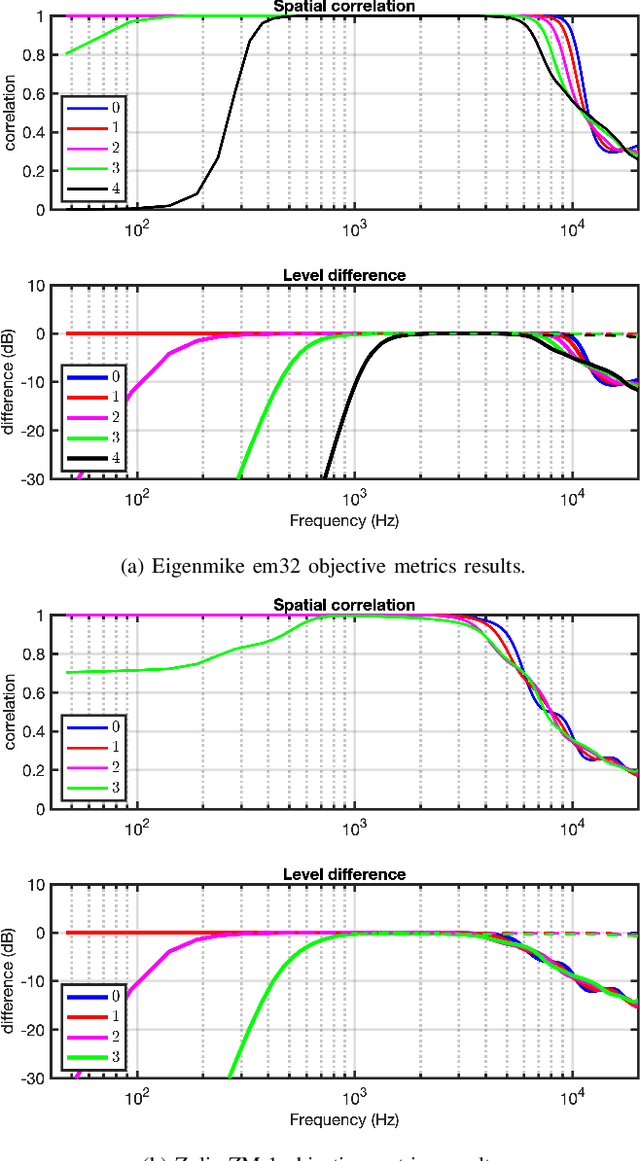
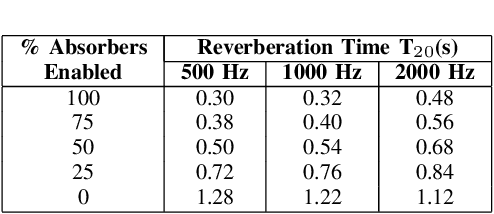
Room acoustics measurements are used in many areas of audio research, from physical acoustics modelling and speech enhancement to virtual reality applications. This paper documents the technical specifications and choices made in the measurement of a dataset of spatial room impulse responses (SRIRs) in a variable acoustics room. Two spherical microphone arrays are used: the mh Acoustics Eigenmike em32 and the Zylia ZM-1, capable of up to fourth- and third-order Ambisonic capture, respectively. The dataset consists of three source and seven receiver positions, repeated with five configurations of the room's acoustics with varying levels of reverberation. Possible applications of the dataset include six degrees-of-freedom (6DoF) analysis and rendering, SRIR interpolation methods, and spatial dereverberation techniques.