 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DEBS 2022 Grand Challenge: Detecting Trading Trends in Financial Tick Data
Jun 23, 2022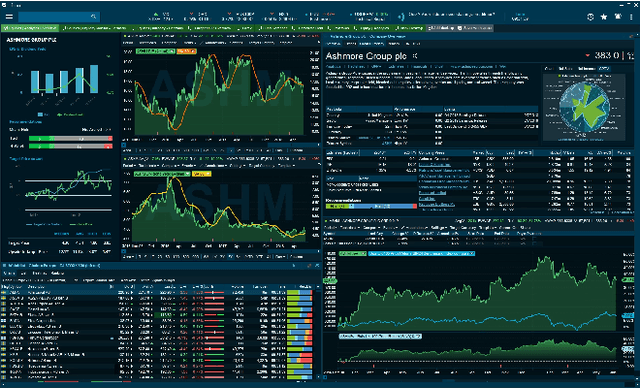
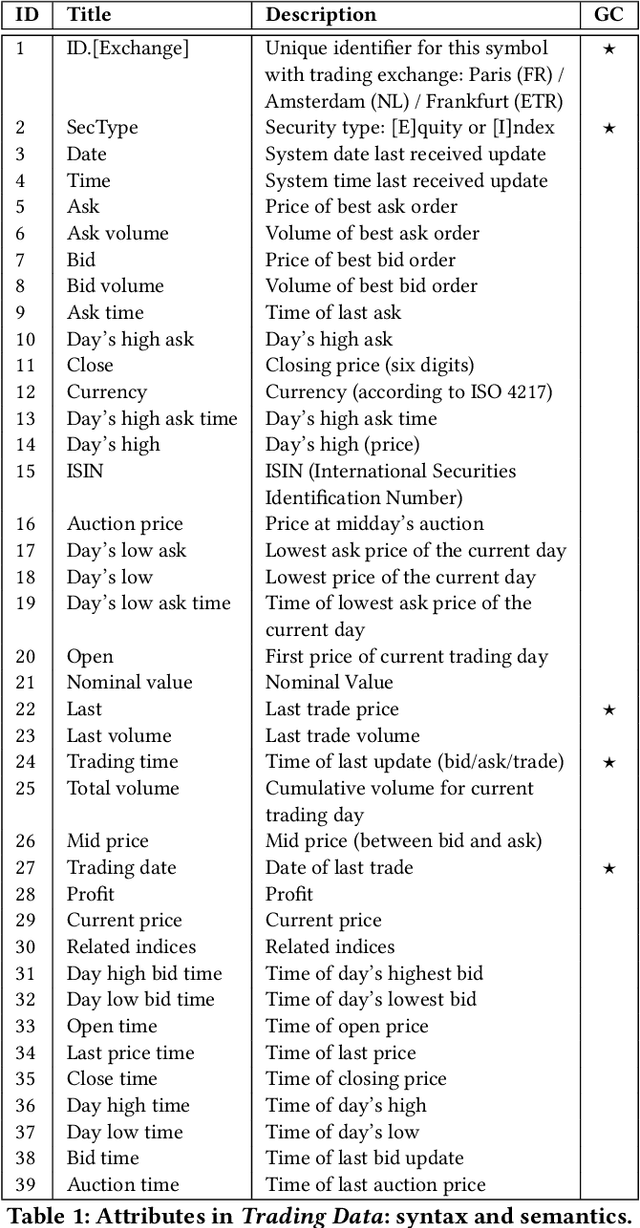
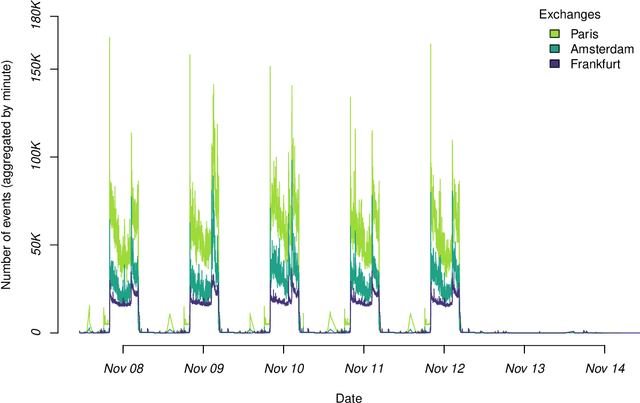
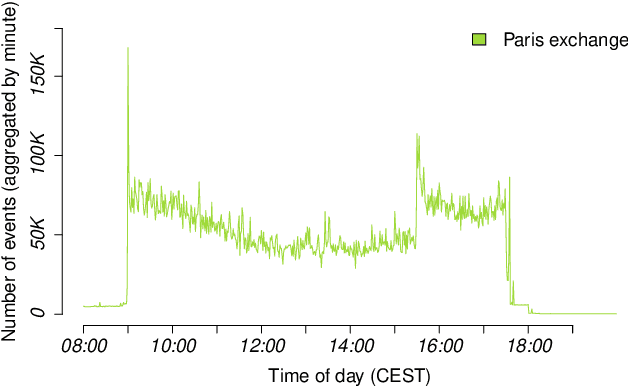
The DEBS Grand Challenge (GC) is an annual programming competition open to practitioners from both academia and industry. The GC 2022 edition focuses on real-time complex event processing of high-volume tick data provided by Infront Financial Technology GmbH. The goal of the challenge is to efficiently compute specific trend indicators and detect patterns in these indicators like those used by real-life traders to decide on buying or selling in financial markets. The data set Trading Data used for benchmarking contains 289 million tick events from approximately 5500+ financial instruments that had been traded on the three major exchanges Amsterdam (NL), Paris (FR), and Frankfurt am Main (GER) over the course of a full week in 2021. The data set is made publicly available. In addition to correctness and performance, submissions must explicitly focus on reusability and practicability. Hence, participants must address specific nonfunctional requirements and are asked to build upon open-source platforms. This paper describes the required scenario and the data set Trading Data, defines the queries of the problem statement, and explains the enhancements made to the evaluation platform Challenger that handles data distribution, dynamic subscriptions, and remote evaluation of the submissions.
Towards the Detection of Building Occupancy with Synthetic Environmental Data
Oct 08, 2020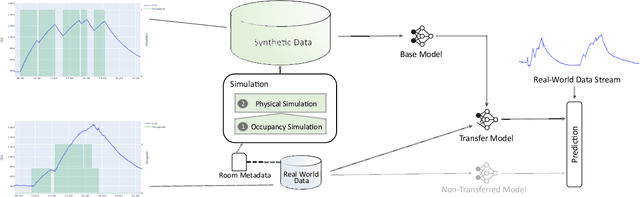

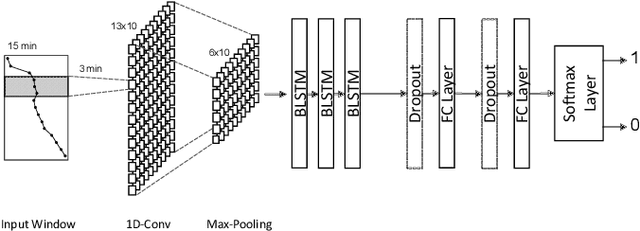
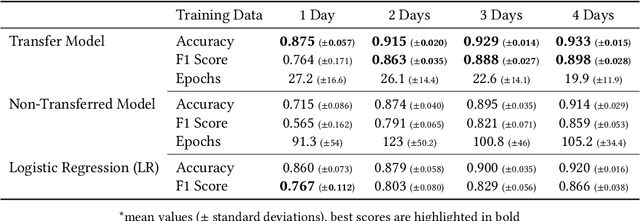
Information about room-level occupancy is crucial to many building-related tasks, such as building automation or energy performance simulation. Current occupancy detection literature focuses on data-driven methods, but is mostly based on small case studies with few rooms. The necessity to collect room-specific data for each room of interest impedes applicability of machine learning, especially data-intensive deep learning approaches, in practice. To derive accurate predictions from less data, we suggest knowledge transfer from synthetic data. In this paper, we conduct an experiment with data from a CO$_2$ sensor in an office room, and additional synthetic data obtained from a simulation. Our contribution includes (a) a simulation method for CO$_2$ dynamics under randomized occupant behavior, (b) a proof of concept for knowledge transfer from simulated CO$_2$ data, and (c) an outline of future research implications. From our results, we can conclude that the transfer approach can effectively reduce the required amount of data for model training.
Real-time Load Prediction with High Velocity Smart Home Data Stream
Aug 12, 2017
This paper addresses the use of smart-home sensor streams for continuous prediction of energy loads of individual households which participate as an agent in local markets. We introduces a new device level energy consumption dataset recorded over three years wich includes high resolution energy measurements from electrical devices collected within a pilot program. Using data from that pilot, we analyze the applicability of various machine learning mechanisms for continuous load prediction. Specifically, we address short-term load prediction that is required for load balancing in electrical micro-grids. We report on the prediction performance and the computational requirements of a broad range of prediction mechanisms. Furthermore we present an architecture and experimental evaluation when this prediction is applied in the stream.
Household Electricity Demand Forecasting -- Benchmarking State-of-the-Art Methods
Apr 01, 2014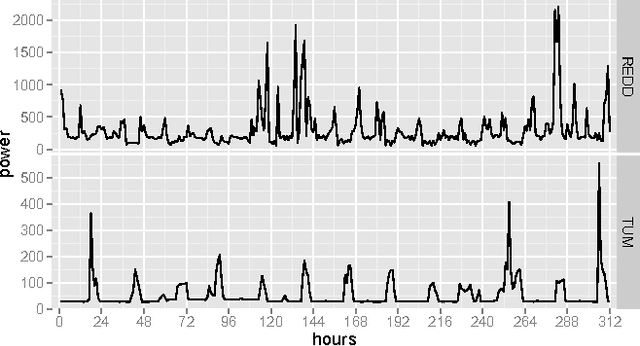
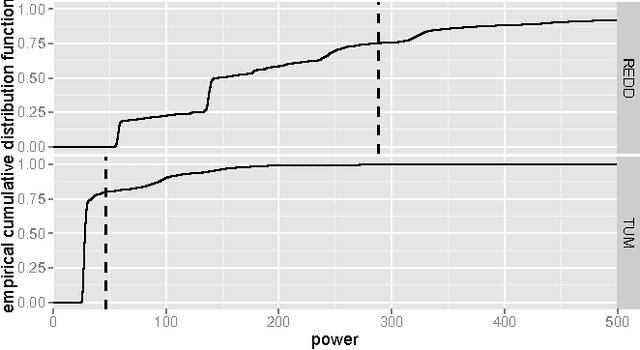
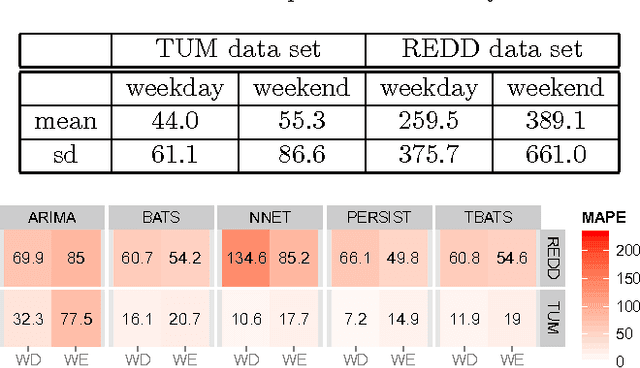
The increasing use of renewable energy sources with variable output, such as solar photovoltaic and wind power generation, calls for Smart Grids that effectively manage flexible loads and energy storage. The ability to forecast consumption at different locations in distribution systems will be a key capability of Smart Grids. The goal of this paper is to benchmark state-of-the-art methods for forecasting electricity demand on the household level across different granularities and time scales in an explorative way, thereby revealing potential shortcomings and find promising directions for future research in this area. We apply a number of forecasting methods including ARIMA, neural networks, and exponential smoothening using several strategies for training data selection, in particular day type and sliding window based strategies. We consider forecasting horizons ranging between 15 minutes and 24 hours. Our evaluation is based on two data sets containing the power usage of individual appliances at second time granularity collected over the course of several months. The results indicate that forecasting accuracy varies significantly depending on the choice of forecasting methods/strategy and the parameter configuration. Measured by the Mean Absolute Percentage Error (MAPE), the considered state-of-the-art forecasting methods rarely beat corresponding persistence forecasts. Overall, we observed MAPEs in the range between 5 and >100%. The average MAPE for the first data set was ~30%, while it was ~85% for the other data set. These results show big room for improvement. Based on the identified trends and experiences from our experiments, we contribute a detailed discussion of promising future research.