 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyViT-FUSE: A Foundation Model for Multi-Sensor Earth Observation Data
Apr 26, 2025We propose PyViT-FUSE, a foundation model for earth observation data explicitly designed to handle multi-modal imagery by learning to fuse an arbitrary number of mixed-resolution input bands into a single representation through an attention mechanism. The learned patch tokens are further processed by a stack of vision transformers with a novel pyramidal structure. We train the model on a globally sampled dataset in a self-supervised manner, leveraging core concepts of the SwAV algorithm. We show the interpretability of the fusion mechanism by visualization of the attention scores and the models applicability to downstream tasks.
Digital Guardians: Can GPT-4, Perspective API, and Moderation API reliably detect hate speech in reader comments of German online newspapers?
Jan 02, 2025



In recent years, toxic content and hate speech have become widespread phenomena on the internet. Moderators of online newspapers and forums are now required, partly due to legal regulations, to carefully review and, if necessary, delete reader comments. This is a labor-intensive process. Some providers of large language models already offer solutions for automated hate speech detection or the identification of toxic content. These include GPT-4o from OpenAI, Jigsaw's (Google) Perspective API, and OpenAI's Moderation API. Based on the selected German test dataset HOCON34k, which was specifically created for developing tools to detect hate speech in reader comments of online newspapers, these solutions are compared with each other and against the HOCON34k baseline. The test dataset contains 1,592 annotated text samples. For GPT-4o, three different promptings are used, employing a Zero-Shot, One-Shot, and Few-Shot approach. The results of the experiments demonstrate that GPT-4o outperforms both the Perspective API and the Moderation API, and exceeds the HOCON34k baseline by approximately 5 percentage points, as measured by a combined metric of MCC and F2-score.
EnergyPlus Room Simulator
Oct 25, 2024Research towards energy optimization in buildings heavily relies on building-related data such as measured indoor climate factors. While data collection is a labor- and cost-intensive task, simulations are a cheap alternative to generate datasets of arbitrary sizes, particularly useful for data-intensive deep learning methods. In this paper, we present the tool EnergyPlus Room Simulator, which enables the simulation of indoor climate in a specific room of a building using the simulation software EnergyPlus. It allows to alter room models and simulate various factors such as temperature, humidity, and CO2 concentration. In contrast to manually working with EnergyPlus, this tool enhances the simulation process by offering a convenient interface, including a user-friendly graphical user interface (GUI) as well as a REST API. The tool is intended to support scientific, building-related tasks such as occupancy detection on a room level by facilitating fast access to simulation data that may, for instance, be used for pre-training machine learning models.
Unified Deep Learning Model for Global Prediction of Aboveground Biomass, Canopy Height and Cover from High-Resolution, Multi-Sensor Satellite Imagery
Aug 20, 2024Regular measurement of carbon stock in the world's forests is critical for carbon accounting and reporting under national and international climate initiatives, and for scientific research, but has been largely limited in scalability and temporal resolution due to a lack of ground based assessments. Increasing efforts have been made to address these challenges by incorporating remotely sensed data. We present a new methodology which uses multi-sensor, multi-spectral imagery at a resolution of 10 meters and a deep learning based model which unifies the prediction of above ground biomass density (AGBD), canopy height (CH), canopy cover (CC) as well as uncertainty estimations for all three quantities. The model is trained on millions of globally sampled GEDI-L2/L4 measurements. We validate the capability of our model by deploying it over the entire globe for the year 2023 as well as annually from 2016 to 2023 over selected areas. The model achieves a mean absolute error for AGBD (CH, CC) of 26.1 Mg/ha (3.7 m, 9.9 %) and a root mean squared error of 50.6 Mg/ha (5.4 m, 15.8 %) on a globally sampled test dataset, demonstrating a significant improvement over previously published results. We also report the model performance against independently collected ground measurements published in the literature, which show a high degree of correlation across varying conditions. We further show that our pre-trained model facilitates seamless transferability to other GEDI variables due to its multi-head architecture.
Towards the Detection of Building Occupancy with Synthetic Environmental Data
Oct 08, 2020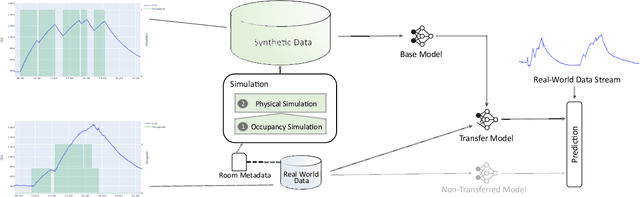

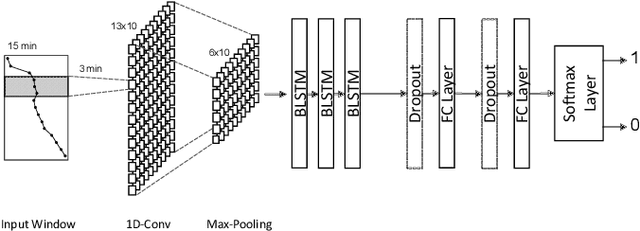
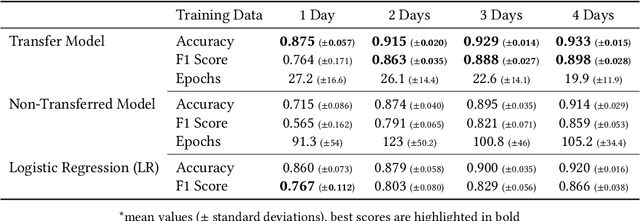
Information about room-level occupancy is crucial to many building-related tasks, such as building automation or energy performance simulation. Current occupancy detection literature focuses on data-driven methods, but is mostly based on small case studies with few rooms. The necessity to collect room-specific data for each room of interest impedes applicability of machine learning, especially data-intensive deep learning approaches, in practice. To derive accurate predictions from less data, we suggest knowledge transfer from synthetic data. In this paper, we conduct an experiment with data from a CO$_2$ sensor in an office room, and additional synthetic data obtained from a simulation. Our contribution includes (a) a simulation method for CO$_2$ dynamics under randomized occupant behavior, (b) a proof of concept for knowledge transfer from simulated CO$_2$ data, and (c) an outline of future research implications. From our results, we can conclude that the transfer approach can effectively reduce the required amount of data for model training.