 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-Bayesian Generalization Guarantees for Fairness on Stochastic and Deterministic Classifiers
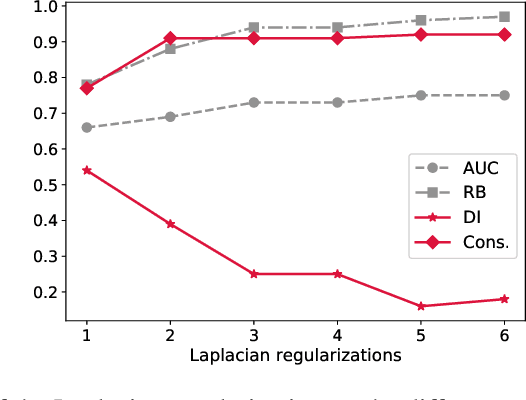
Feb 12, 2026Classical PAC generalization bounds on the prediction risk of a classifier are insufficient to provide theoretical guarantees on fairness when the goal is to learn models balancing predictive risk and fairness constraints. We propose a PAC-Bayesian framework for deriving generalization bounds for fairness, covering both stochastic and deterministic classifiers. For stochastic classifiers, we derive a fairness bound using standard PAC-Bayes techniques. Whereas for deterministic classifiers, as usual PAC-Bayes arguments do not apply directly, we leverage a recent advance in PAC-Bayes to extend the fairness bound beyond the stochastic setting. Our framework has two advantages: (i) It applies to a broad class of fairness measures that can be expressed as a risk discrepancy, and (ii) it leads to a self-bounding algorithm in which the learning procedure directly optimizes a trade-off between generalization bounds on the prediction risk and on the fairness. We empirically evaluate our framework with three classical fairness measures, demonstrating not only its usefulness but also the tightness of our bounds.
Drop the mask! GAMM-A Taxonomy for Graph Attributes Missing Mechanisms
Feb 09, 2026Exploring missing data in attributed graphs introduces unique challenges beyond those found in tabular datasets. In this work, we extend the taxonomy for missing data mechanisms to attributed graphs by proposing GAMM (Graph Attributes Missing Mechanisms), a framework that systematically links missingness probability to both node attributes and the underlying graph structure. Our taxonomy enriches the conventional definitions of masking mechanisms by introducing graph-specific dependencies. We empirically demonstrate that state-of-the-art imputation methods, while effective on traditional masks, significantly struggle when confronted with these more realistic graph-aware missingness scenarios.
Pattern Mining for Anomaly Detection in Graphs: Application to Fraud in Public Procurement
Jun 19, 2023In the context of public procurement, several indicators called red flags are used to estimate fraud risk. They are computed according to certain contract attributes and are therefore dependent on the proper filling of the contract and award notices. However, these attributes are very often missing in practice, which prohibits red flags computation. Traditional fraud detection approaches focus on tabular data only, considering each contract separately, and are therefore very sensitive to this issue. In this work, we adopt a graph-based method allowing leveraging relations between contracts, to compensate for the missing attributes. We propose PANG (Pattern-Based Anomaly Detection in Graphs), a general supervised framework relying on pattern extraction to detect anomalous graphs in a collection of attributed graphs. Notably, it is able to identify induced subgraphs, a type of pattern widely overlooked in the literature. When benchmarked on standard datasets, its predictive performance is on par with state-of-the-art methods, with the additional advantage of being explainable. These experiments also reveal that induced patterns are more discriminative on certain datasets. When applying PANG to public procurement data, the prediction is superior to other methods, and it identifies subgraph patterns that are characteristic of fraud-prone situations, thereby making it possible to better understand fraudulent behavior.
A Survey on Fairness for Machine Learning on Graphs
May 11, 2022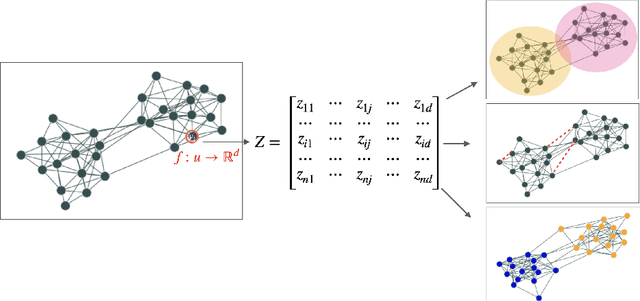
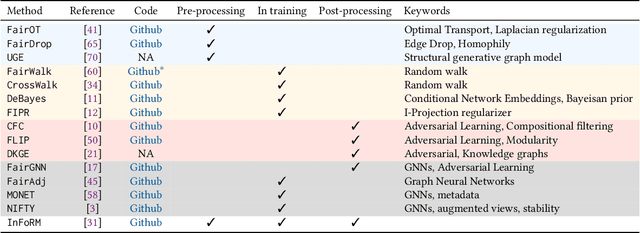
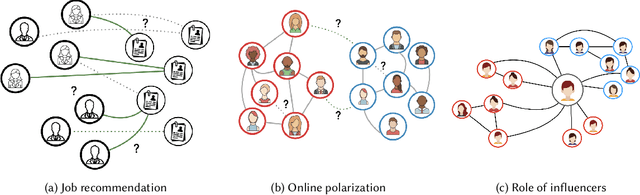
Nowadays, the analysis of complex phenomena modeled by graphs plays a crucial role in many real-world application domains where decisions can have a strong societal impact. However, numerous studies and papers have recently revealed that machine learning models could lead to potential disparate treatment between individuals and unfair outcomes. In that context, algorithmic contributions for graph mining are not spared by the problem of fairness and present some specific challenges related to the intrinsic nature of graphs: (1) graph data is non-IID, and this assumption may invalidate many existing studies in fair machine learning, (2) suited metric definitions to assess the different types of fairness with relational data and (3) algorithmic challenge on the difficulty of finding a good trade-off between model accuracy and fairness. This survey is the first one dedicated to fairness for relational data. It aims to present a comprehensive review of state-of-the-art techniques in fairness on graph mining and identify the open challenges and future trends. In particular, we start by presenting several sensible application domains and the associated graph mining tasks with a focus on edge prediction and node classification in the sequel. We also recall the different metrics proposed to evaluate potential bias at different levels of the graph mining process; then we provide a comprehensive overview of recent contributions in the domain of fair machine learning for graphs, that we classify into pre-processing, in-processing and post-processing models. We also propose to describe existing graph data, synthetic and real-world benchmarks. Finally, we present in detail five potential promising directions to advance research in studying algorithmic fairness on graphs.
All of the Fairness for Edge Prediction with Optimal Transport
Oct 30, 2020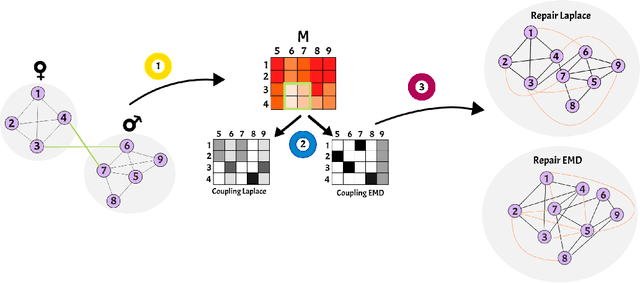


Machine learning and data mining algorithms have been increasingly used recently to support decision-making systems in many areas of high societal importance such as healthcare, education, or security. While being very efficient in their predictive abilities, the deployed algorithms sometimes tend to learn an inductive model with a discriminative bias due to the presence of this latter in the learning sample. This problem gave rise to a new field of algorithmic fairness where the goal is to correct the discriminative bias introduced by a certain attribute in order to decorrelate it from the model's output. In this paper, we study the problem of fairness for the task of edge prediction in graphs, a largely underinvestigated scenario compared to a more popular setting of fair classification. To this end, we formulate the problem of fair edge prediction, analyze it theoretically, and propose an embedding-agnostic repairing procedure for the adjacency matrix of an arbitrary graph with a trade-off between the group and individual fairness. We experimentally show the versatility of our approach and its capacity to provide explicit control over different notions of fairness and prediction accuracy.
A Model for Managing Collections of Patterns
Feb 06, 2009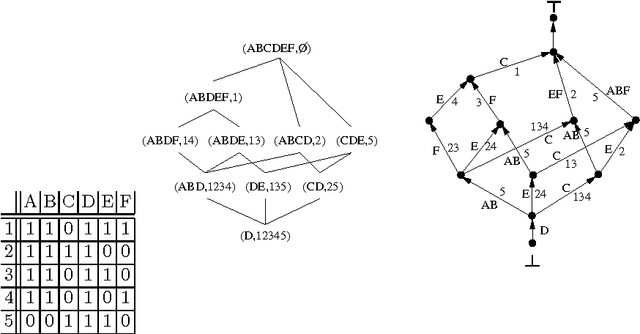
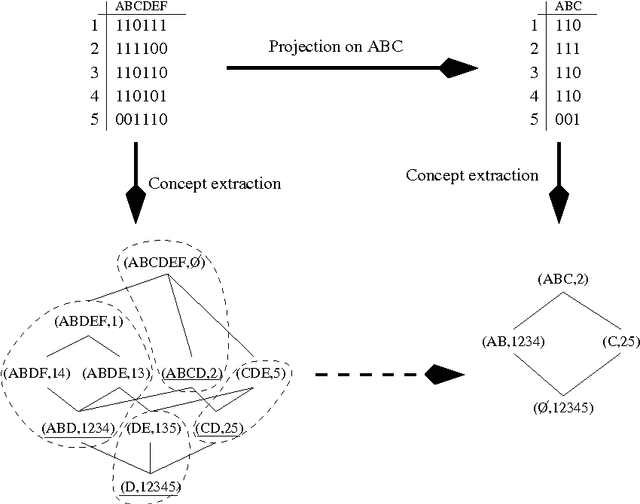
Data mining algorithms are now able to efficiently deal with huge amount of data. Various kinds of patterns may be discovered and may have some great impact on the general development of knowledge. In many domains, end users may want to have their data mined by data mining tools in order to extract patterns that could impact their business. Nevertheless, those users are often overwhelmed by the large quantity of patterns extracted in such a situation. Moreover, some privacy issues, or some commercial one may lead the users not to be able to mine the data by themselves. Thus, the users may not have the possibility to perform many experiments integrating various constraints in order to focus on specific patterns they would like to extract. Post processing of patterns may be an answer to that drawback. Thus, in this paper we present a framework that could allow end users to manage collections of patterns. We propose to use an efficient data structure on which some algebraic operators may be used in order to retrieve or access patterns in pattern bases.