 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Fairness for Machine Learning on Graphs
Paper and Code
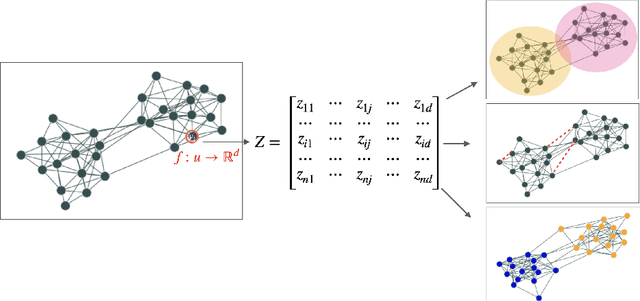
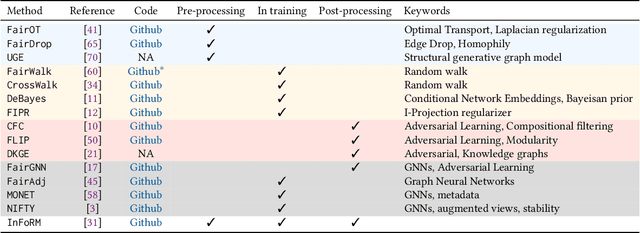
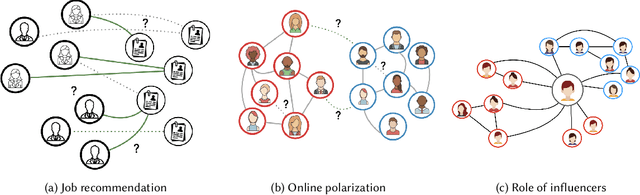
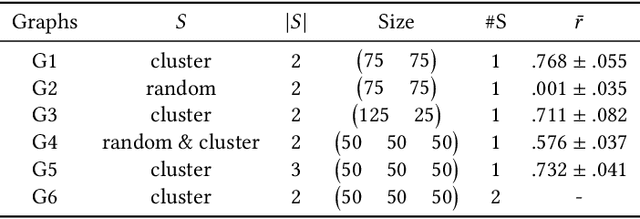
Nowadays, the analysis of complex phenomena modeled by graphs plays a crucial role in many real-world application domains where decisions can have a strong societal impact. However, numerous studies and papers have recently revealed that machine learning models could lead to potential disparate treatment between individuals and unfair outcomes. In that context, algorithmic contributions for graph mining are not spared by the problem of fairness and present some specific challenges related to the intrinsic nature of graphs: (1) graph data is non-IID, and this assumption may invalidate many existing studies in fair machine learning, (2) suited metric definitions to assess the different types of fairness with relational data and (3) algorithmic challenge on the difficulty of finding a good trade-off between model accuracy and fairness. This survey is the first one dedicated to fairness for relational data. It aims to present a comprehensive review of state-of-the-art techniques in fairness on graph mining and identify the open challenges and future trends. In particular, we start by presenting several sensible application domains and the associated graph mining tasks with a focus on edge prediction and node classification in the sequel. We also recall the different metrics proposed to evaluate potential bias at different levels of the graph mining process; then we provide a comprehensive overview of recent contributions in the domain of fair machine learning for graphs, that we classify into pre-processing, in-processing and post-processing models. We also propose to describe existing graph data, synthetic and real-world benchmarks. Finally, we present in detail five potential promising directions to advance research in studying algorithmic fairness on graphs.