 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Fairness for Machine Learning on Graphs
May 11, 2022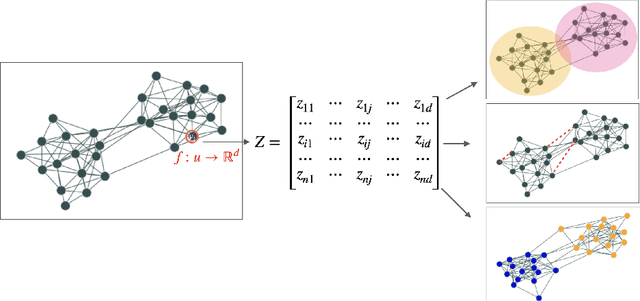
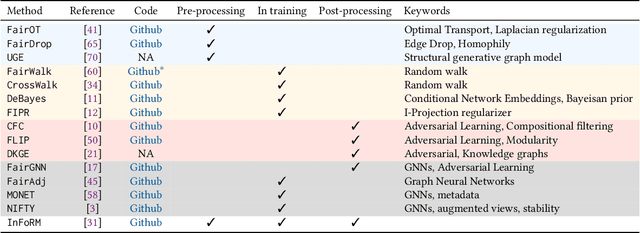
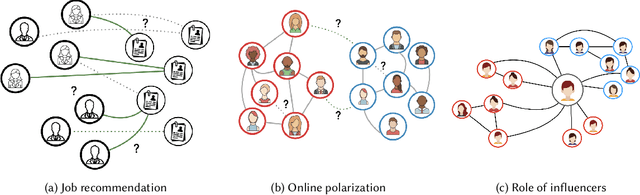
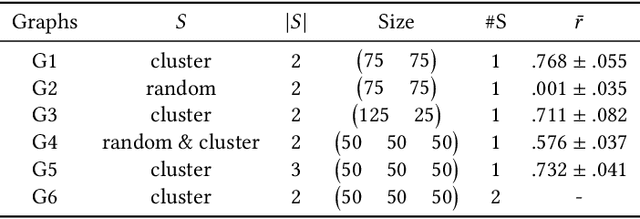
Nowadays, the analysis of complex phenomena modeled by graphs plays a crucial role in many real-world application domains where decisions can have a strong societal impact. However, numerous studies and papers have recently revealed that machine learning models could lead to potential disparate treatment between individuals and unfair outcomes. In that context, algorithmic contributions for graph mining are not spared by the problem of fairness and present some specific challenges related to the intrinsic nature of graphs: (1) graph data is non-IID, and this assumption may invalidate many existing studies in fair machine learning, (2) suited metric definitions to assess the different types of fairness with relational data and (3) algorithmic challenge on the difficulty of finding a good trade-off between model accuracy and fairness. This survey is the first one dedicated to fairness for relational data. It aims to present a comprehensive review of state-of-the-art techniques in fairness on graph mining and identify the open challenges and future trends. In particular, we start by presenting several sensible application domains and the associated graph mining tasks with a focus on edge prediction and node classification in the sequel. We also recall the different metrics proposed to evaluate potential bias at different levels of the graph mining process; then we provide a comprehensive overview of recent contributions in the domain of fair machine learning for graphs, that we classify into pre-processing, in-processing and post-processing models. We also propose to describe existing graph data, synthetic and real-world benchmarks. Finally, we present in detail five potential promising directions to advance research in studying algorithmic fairness on graphs.
All of the Fairness for Edge Prediction with Optimal Transport
Oct 30, 2020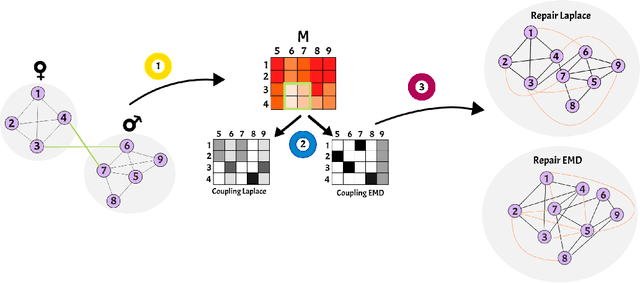
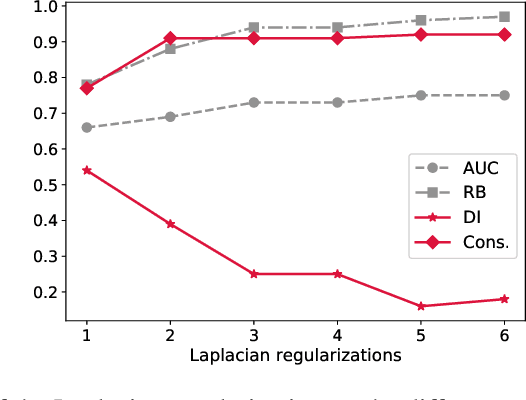


Machine learning and data mining algorithms have been increasingly used recently to support decision-making systems in many areas of high societal importance such as healthcare, education, or security. While being very efficient in their predictive abilities, the deployed algorithms sometimes tend to learn an inductive model with a discriminative bias due to the presence of this latter in the learning sample. This problem gave rise to a new field of algorithmic fairness where the goal is to correct the discriminative bias introduced by a certain attribute in order to decorrelate it from the model's output. In this paper, we study the problem of fairness for the task of edge prediction in graphs, a largely underinvestigated scenario compared to a more popular setting of fair classification. To this end, we formulate the problem of fair edge prediction, analyze it theoretically, and propose an embedding-agnostic repairing procedure for the adjacency matrix of an arbitrary graph with a trade-off between the group and individual fairness. We experimentally show the versatility of our approach and its capacity to provide explicit control over different notions of fairness and prediction accuracy.