 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern Mining for Anomaly Detection in Graphs: Application to Fraud in Public Procurement
Jun 19, 2023In the context of public procurement, several indicators called red flags are used to estimate fraud risk. They are computed according to certain contract attributes and are therefore dependent on the proper filling of the contract and award notices. However, these attributes are very often missing in practice, which prohibits red flags computation. Traditional fraud detection approaches focus on tabular data only, considering each contract separately, and are therefore very sensitive to this issue. In this work, we adopt a graph-based method allowing leveraging relations between contracts, to compensate for the missing attributes. We propose PANG (Pattern-Based Anomaly Detection in Graphs), a general supervised framework relying on pattern extraction to detect anomalous graphs in a collection of attributed graphs. Notably, it is able to identify induced subgraphs, a type of pattern widely overlooked in the literature. When benchmarked on standard datasets, its predictive performance is on par with state-of-the-art methods, with the additional advantage of being explainable. These experiments also reveal that induced patterns are more discriminative on certain datasets. When applying PANG to public procurement data, the prediction is superior to other methods, and it identifies subgraph patterns that are characteristic of fraud-prone situations, thereby making it possible to better understand fraudulent behavior.
Characterizing and comparing external measures for the assessment of cluster analysis and community detection
Feb 01, 2021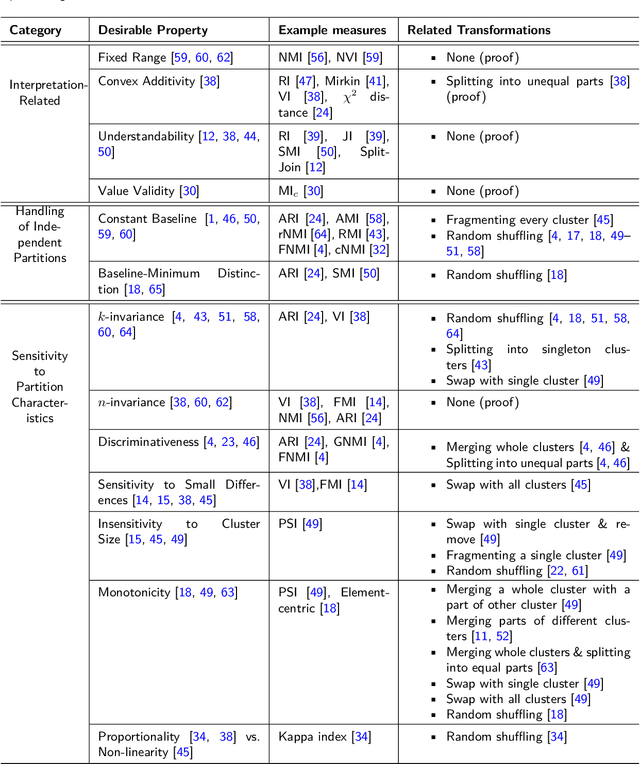
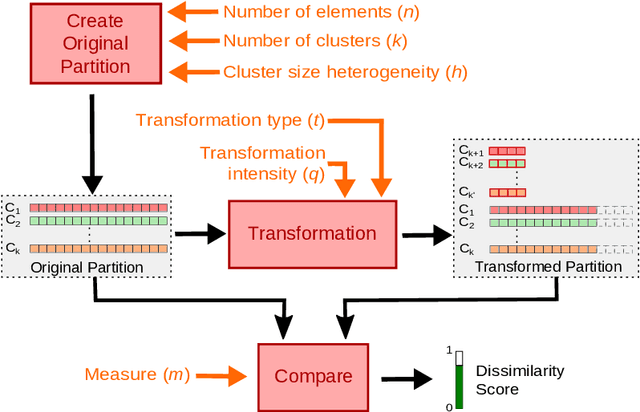

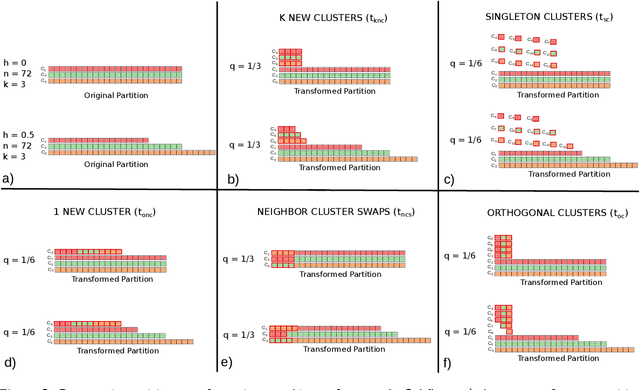
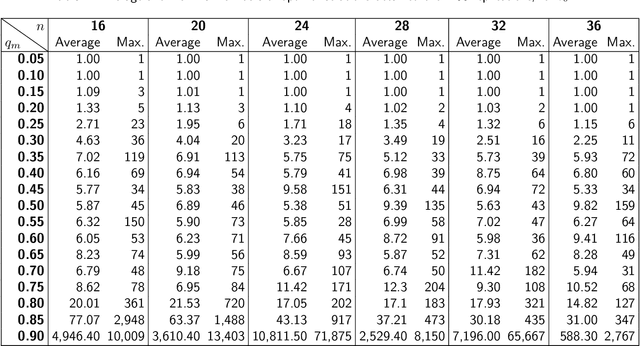
In the context of cluster analysis and graph partitioning, many external evaluation measures have been proposed in the literature to compare two partitions of the same set. This makes the task of selecting the most appropriate measure for a given situation a challenge for the end user. However, this issue is overlooked in the literature. Researchers tend to follow tradition and use the standard measures of their field, although they often became standard only because previous researchers started consistently using them. In this work, we propose a new empirical evaluation framework to solve this issue, and help the end user selecting an appropriate measure for their application. For a collection of candidate measures, it first consists in describing their behavior by computing them for a generated dataset of partitions, obtained by applying a set of predefined parametric partition transformations. Second, our framework performs a regression analysis to characterize the measures in terms of how they are affected by these parameters and transformations. This allows both describing and comparing the measures. Our approach is not tied to any specific measure or application, so it can be applied to any situation. We illustrate its relevance by applying it to a selection of standard measures, and show how it can be put in practice through two concrete use cases.
Multiplicity and Diversity: Analyzing the Optimal Solution Space of the Correlation Clustering Problem on Complete Signed Graphs
Nov 10, 2020
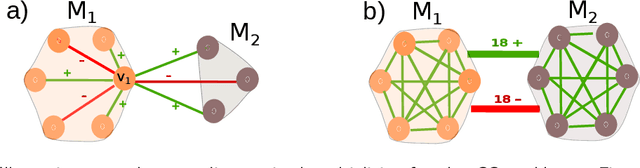
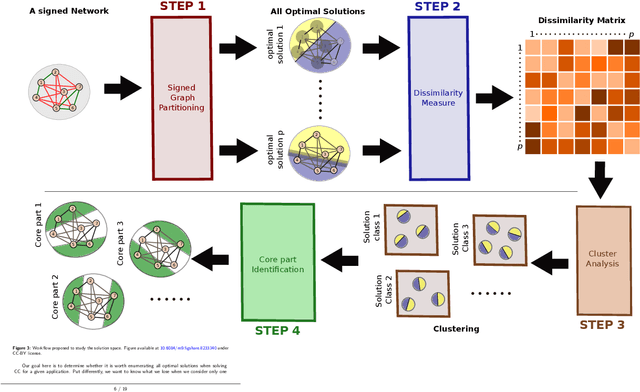
In order to study real-world systems, many applied works model them through signed graphs, i.e. graphs whose edges are labeled as either positive or negative. Such a graph is considered as structurally balanced when it can be partitioned into a number of modules, such that positive (resp. negative) edges are located inside (resp. in-between) the modules. When it is not the case, authors look for the closest partition to such balance, a problem called Correlation Clustering (CC). Due to the complexity of the CC problem, the standard approach is to find a single optimal partition and stick to it, even if other optimal or high scoring solutions possibly exist. In this work, we study the space of optimal solutions of the CC problem, on a collection of synthetic complete graphs. We show empirically that under certain conditions, there can be many optimal partitions of a signed graph. Some of these are very different and thus provide distinct perspectives on the system, as illustrated on a small real-world graph. This is an important result, as it implies that one may have to find several, if not all, optimal solutions of the CC problem, in order to properly study the considered system.
Relevance of Negative Links in Graph Partitioning: A Case Study Using Votes From the European Parliament
Jul 21, 2015
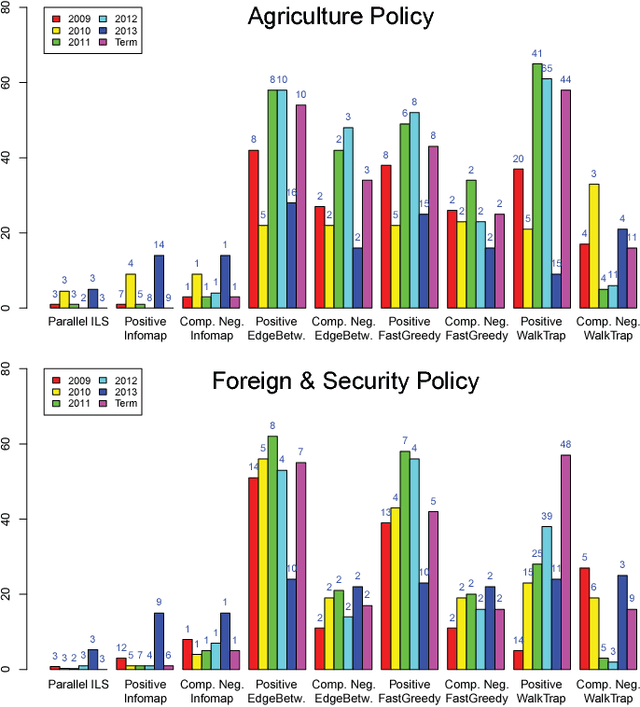


In this paper, we want to study the informative value of negative links in signed complex networks. For this purpose, we extract and analyze a collection of signed networks representing voting sessions of the European Parliament (EP). We first process some data collected by the VoteWatch Europe Website for the whole 7 th term (2009-2014), by considering voting similarities between Members of the EP to define weighted signed links. We then apply a selection of community detection algorithms, designed to process only positive links, to these data. We also apply Parallel Iterative Local Search (Parallel ILS), an algorithm recently proposed to identify balanced partitions in signed networks. Our results show that, contrary to the conclusions of a previous study focusing on other data, the partitions detected by ignoring or considering the negative links are indeed remarkably different for these networks. The relevance of negative links for graph partitioning therefore is an open question which should be further explored.