 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederatedFactory: Generative One-Shot Learning for Extremely Non-IID Distributed Scenarios
Mar 17, 2026Federated Learning (FL) enables distributed optimization without compromising data sovereignty. Yet, where local label distributions are mutually exclusive, standard weight aggregation fails due to conflicting optimization trajectories. Often, FL methods rely on pretrained foundation models, introducing unrealistic assumptions. We introduce FederatedFactory, a zero-dependency framework that inverts the unit of federation from discriminative parameters to generative priors. By exchanging generative modules in a single communication round, our architecture supports ex nihilo synthesis of universally class balanced datasets, eliminating gradient conflict and external prior bias entirely. Evaluations across diverse medical imagery benchmarks, including MedMNIST and ISIC2019, demonstrate that our approach recovers centralized upper-bound performance. Under pathological heterogeneity, it lifts baseline accuracy from a collapsed 11.36% to 90.57% on CIFAR-10 and restores ISIC2019 AUROC to 90.57%. Additionally, this framework facilitates exact modular unlearning through the deterministic deletion of specific generative modules.
The Observer Effect in World Models: Invasive Adaptation Corrupts Latent Physics
Feb 12, 2026Determining whether neural models internalize physical laws as world models, rather than exploiting statistical shortcuts, remains challenging, especially under out-of-distribution (OOD) shifts. Standard evaluations often test latent capability via downstream adaptation (e.g., fine-tuning or high-capacity probes), but such interventions can change the representations being measured and thus confound what was learned during self-supervised learning (SSL). We propose a non-invasive evaluation protocol, PhyIP. We test whether physical quantities are linearly decodable from frozen representations, motivated by the linear representation hypothesis. Across fluid dynamics and orbital mechanics, we find that when SSL achieves low error, latent structure becomes linearly accessible. PhyIP recovers internal energy and Newtonian inverse-square scaling on OOD tests (e.g., $ρ> 0.90$). In contrast, adaptation-based evaluations can collapse this structure ($ρ\approx 0.05$). These findings suggest that adaptation-based evaluation can obscure latent structures and that low-capacity probes offer a more accurate evaluation of physical world models.
Automated Federated Learning via Informed Pruning
May 16, 2024

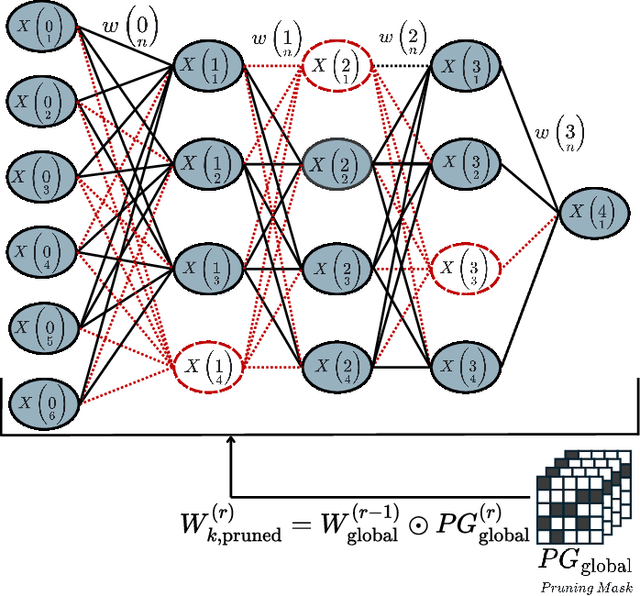

Federated learning (FL) represents a pivotal shift in machine learning (ML) as it enables collaborative training of local ML models coordinated by a central aggregator, all without the need to exchange local data. However, its application on edge devices is hindered by limited computational capabilities and data communication challenges, compounded by the inherent complexity of Deep Learning (DL) models. Model pruning is identified as a key technique for compressing DL models on devices with limited resources. Nonetheless, conventional pruning techniques typically rely on manually crafted heuristics and demand human expertise to achieve a balance between model size, speed, and accuracy, often resulting in sub-optimal solutions. In this study, we introduce an automated federated learning approach utilizing informed pruning, called AutoFLIP, which dynamically prunes and compresses DL models within both the local clients and the global server. It leverages a federated loss exploration phase to investigate model gradient behavior across diverse datasets and losses, providing insights into parameter significance. Our experiments showcase notable enhancements in scenarios with strong non-IID data, underscoring AutoFLIP's capacity to tackle computational constraints and achieve superior global convergence.
Question-Answering Model for Schizophrenia Symptoms and Their Impact on Daily Life using Mental Health Forums Data
Sep 30, 2023In recent years, there is strong emphasis on mining medical data using machine learning techniques. A common problem is to obtain a noiseless set of textual documents, with a relevant content for the research question, and developing a Question Answering (QA) model for a specific medical field. The purpose of this paper is to present a new methodology for building a medical dataset and obtain a QA model for analysis of symptoms and impact on daily life for a specific disease domain. The ``Mental Health'' forum was used, a forum dedicated to people suffering from schizophrenia and different mental disorders. Relevant posts of active users, who regularly participate, were extrapolated providing a new method of obtaining low-bias content and without privacy issues. Furthermore, it is shown how to pre-process the dataset to convert it into a QA dataset. The Bidirectional Encoder Representations from Transformers (BERT), DistilBERT, RoBERTa, and BioBERT models were fine-tuned and evaluated via F1-Score, Exact Match, Precision and Recall. Accurate empirical experiments demonstrated the effectiveness of the proposed method for obtaining an accurate dataset for QA model implementation. By fine-tuning the BioBERT QA model, we achieved an F1 score of 0.885, showing a considerable improvement and outperforming the state-of-the-art model for mental disorders domain.