 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-HOI: Contact-Guided 3D Human-Object Interaction Generation
Nov 27, 2023We propose CG-HOI, the first method to address the task of generating dynamic 3D human-object interactions (HOIs) from text. We model the motion of both human and object in an interdependent fashion, as semantically rich human motion rarely happens in isolation without any interactions. Our key insight is that explicitly modeling contact between the human body surface and object geometry can be used as strong proxy guidance, both during training and inference. Using this guidance to bridge human and object motion enables generating more realistic and physically plausible interaction sequences, where the human body and corresponding object move in a coherent manner. Our method first learns to model human motion, object motion, and contact in a joint diffusion process, inter-correlated through cross-attention. We then leverage this learned contact for guidance during inference synthesis of realistic, coherent HOIs. Extensive evaluation shows that our joint contact-based human-object interaction approach generates realistic and physically plausible sequences, and we show two applications highlighting the capabilities of our method. Conditioned on a given object trajectory, we can generate the corresponding human motion without re-training, demonstrating strong human-object interdependency learning. Our approach is also flexible, and can be applied to static real-world 3D scene scans.
Forecasting Actions and Characteristic 3D Poses
Nov 25, 2022



We propose to model longer-term future human behavior by jointly predicting action labels and 3D characteristic poses (3D poses representative of the associated actions). While previous work has considered action and 3D pose forecasting separately, we observe that the nature of the two tasks is coupled, and thus we predict them together. Starting from an input 2D video observation, we jointly predict a future sequence of actions along with 3D poses characterizing these actions. Since coupled action labels and 3D pose annotations are difficult and expensive to acquire for videos of complex action sequences, we train our approach with action labels and 2D pose supervision from two existing action video datasets, in tandem with an adversarial loss that encourages likely 3D predicted poses. Our experiments demonstrate the complementary nature of joint action and characteristic 3D pose prediction: our joint approach outperforms each task treated individually, enables robust longer-term sequence prediction, and outperforms alternative approaches to forecast actions and characteristic 3D poses.
Forecasting Characteristic 3D Poses of Human Actions
Nov 30, 2020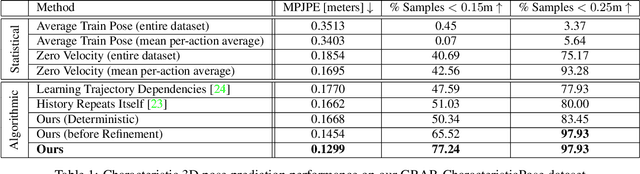
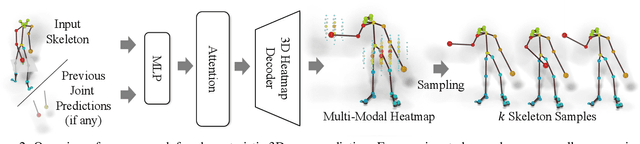
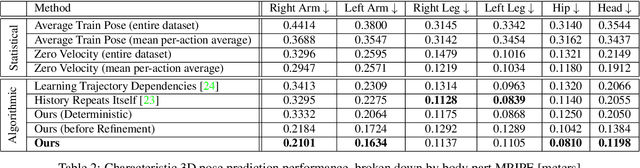
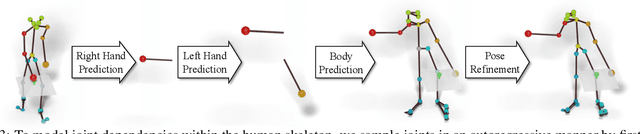
We propose the task of forecasting characteristic 3D poses: from a single pose observation of a person, to predict a future 3D pose of that person in a likely action-defining, characteristic pose - for instance, from observing a person picking up a banana, predict the pose of the person eating the banana. Prior work on human motion prediction estimates future poses at fixed time intervals. Although easy to define, this frame-by-frame formulation confounds temporal and intentional aspects of human action. Instead, we define a goal-directed pose prediction task that decouples pose prediction from time, taking inspiration from human, goal-directed behavior. To predict characteristic goal poses, we propose a probabilistic approach that first models the possible multi-modality in the distribution of possible characteristic poses. It then samples future pose hypotheses from the predicted distribution in an autoregressive fashion to model dependencies between joints and then optimizes the final pose with bone length and angle constraints. To evaluate our method, we construct a dataset of manually annotated single-frame observations and characteristic 3D poses. Our experiments with this dataset suggest that our proposed probabilistic approach outperforms state-of-the-art approaches by 22% on average.
SG-NN: Sparse Generative Neural Networks for Self-Supervised Scene Completion of RGB-D Scans
Nov 29, 2019



We present a novel approach that converts partial and noisy RGB-D scans into high-quality 3D scene reconstructions by inferring unobserved scene geometry. Our approach is fully self-supervised and can hence be trained solely on real-world, incomplete scans. To achieve self-supervision, we remove frames from a given (incomplete) 3D scan in order to make it even more incomplete; self-supervision is then formulated by correlating the two levels of partialness of the same scan while masking out regions that have never been observed. Through generalization across a large training set, we can then predict 3D scene completion without ever seeing any 3D scan of entirely complete geometry. Combined with a new 3D sparse generative neural network architecture, our method is able to predict highly-detailed surfaces in a coarse-to-fine hierarchical fashion, generating 3D scenes at 2cm resolution, more than twice the resolution of existing state-of-the-art methods as well as outperforming them by a significant margin in reconstruction quality.