 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe UCR Time Series Archive
Oct 17, 2018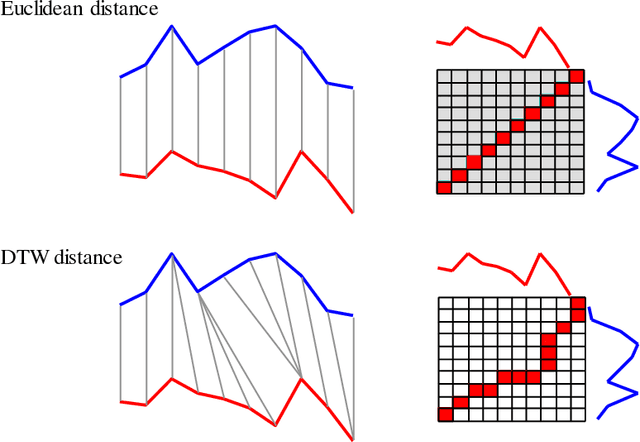
The UCR Time Series Archive - introduced in 2002, has become an important resource in the time series data mining community, with at least one thousand published papers making use of at least one dataset from the archive. The original incarnation of the archive had sixteen datasets but since that time, it has gone through periodic expansions. The last expansion took place in the summer of 2015 when the archive grew from 45 datasets to 85 datasets. This paper introduces and will focus on the new data expansion from 85 to 128 datasets. Beyond expanding this valuable resource, this paper offers pragmatic advice to anyone who may wish to evaluate a new algorithm on the archive. Finally, this paper makes a novel and yet actionable claim: of the hundreds of papers that show an improvement over the standard baseline (1-Nearest Neighbor classification), a large fraction may be misattributing the reasons for their improvement. Moreover, they may have been able to achieve the same improvement with a much simpler modification, requiring just a single line of code.
Exact Indexing for Massive Time Series Databases under Time Warping Distance
Jun 13, 2009


Among many existing distance measures for time series data, Dynamic Time Warping (DTW) distance has been recognized as one of the most accurate and suitable distance measures due to its flexibility in sequence alignment. However, DTW distance calculation is computationally intensive. Especially in very large time series databases, sequential scan through the entire database is definitely impractical, even with random access that exploits some index structures since high dimensionality of time series data incurs extremely high I/O cost. More specifically, a sequential structure consumes high CPU but low I/O costs, while an index structure requires low CPU but high I/O costs. In this work, we therefore propose a novel indexed sequential structure called TWIST (Time Warping in Indexed Sequential sTructure) which benefits from both sequential access and index structure. When a query sequence is issued, TWIST calculates lower bounding distances between a group of candidate sequences and the query sequence, and then identifies the data access order in advance, hence reducing a great number of both sequential and random accesses. Impressively, our indexed sequential structure achieves significant speedup in a querying process by a few orders of magnitude. In addition, our method shows superiority over existing rival methods in terms of query processing time, number of page accesses, and storage requirement with no false dismissal guaranteed.
Learning DTW Global Constraint for Time Series Classification
Feb 28, 2009



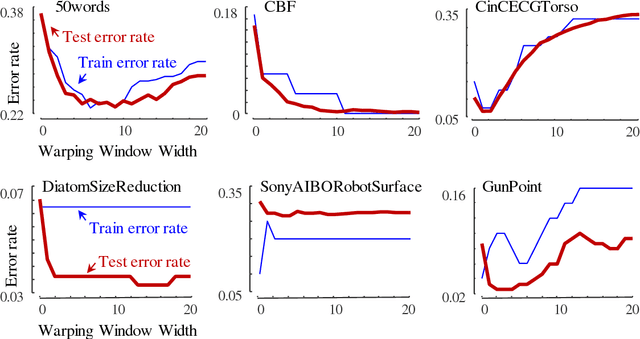
1-Nearest Neighbor with the Dynamic Time Warping (DTW) distance is one of the most effective classifiers on time series domain. Since the global constraint has been introduced in speech community, many global constraint models have been proposed including Sakoe-Chiba (S-C) band, Itakura Parallelogram, and Ratanamahatana-Keogh (R-K) band. The R-K band is a general global constraint model that can represent any global constraints with arbitrary shape and size effectively. However, we need a good learning algorithm to discover the most suitable set of R-K bands, and the current R-K band learning algorithm still suffers from an 'overfitting' phenomenon. In this paper, we propose two new learning algorithms, i.e., band boundary extraction algorithm and iterative learning algorithm. The band boundary extraction is calculated from the bound of all possible warping paths in each class, and the iterative learning is adjusted from the original R-K band learning. We also use a Silhouette index, a well-known clustering validation technique, as a heuristic function, and the lower bound function, LB_Keogh, to enhance the prediction speed. Twenty datasets, from the Workshop and Challenge on Time Series Classification, held in conjunction of the SIGKDD 2007, are used to evaluate our approach.