 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe UCR Time Series Archive
Paper and Code
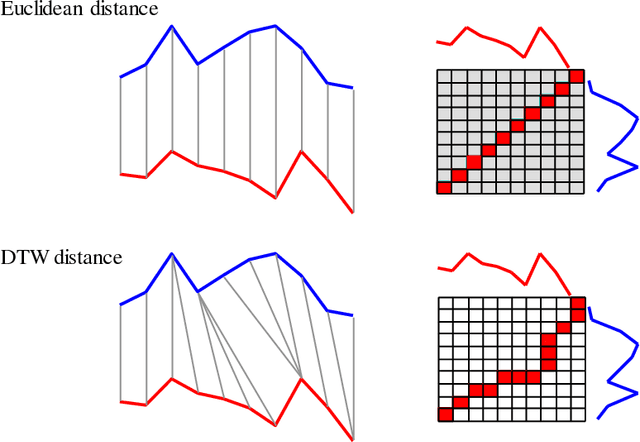
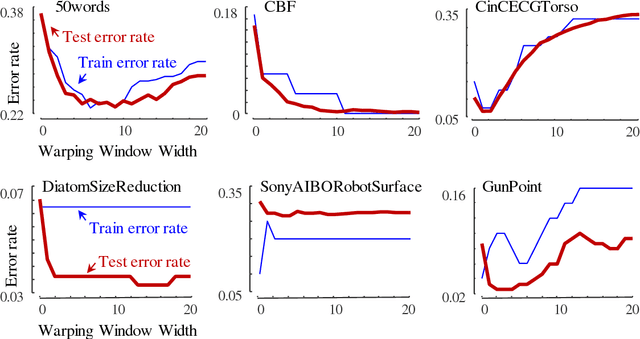
The UCR Time Series Archive - introduced in 2002, has become an important resource in the time series data mining community, with at least one thousand published papers making use of at least one dataset from the archive. The original incarnation of the archive had sixteen datasets but since that time, it has gone through periodic expansions. The last expansion took place in the summer of 2015 when the archive grew from 45 datasets to 85 datasets. This paper introduces and will focus on the new data expansion from 85 to 128 datasets. Beyond expanding this valuable resource, this paper offers pragmatic advice to anyone who may wish to evaluate a new algorithm on the archive. Finally, this paper makes a novel and yet actionable claim: of the hundreds of papers that show an improvement over the standard baseline (1-Nearest Neighbor classification), a large fraction may be misattributing the reasons for their improvement. Moreover, they may have been able to achieve the same improvement with a much simpler modification, requiring just a single line of code.