 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Forecasted Vital Signs Using N-BEATS in Sepsis Patients
Jun 24, 2023
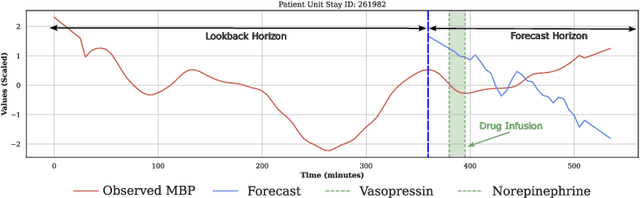
Detecting and predicting septic shock early is crucial for the best possible outcome for patients. Accurately forecasting the vital signs of patients with sepsis provides valuable insights to clinicians for timely interventions, such as administering stabilizing drugs or optimizing infusion strategies. Our research examines N-BEATS, an interpretable deep-learning forecasting model that can forecast 3 hours of vital signs for sepsis patients in intensive care units (ICUs). In this work, we use the N-BEATS interpretable configuration to forecast the vital sign trends and compare them with the actual trend to understand better the patient's changing condition and the effects of infused drugs on their vital signs. We evaluate our approach using the publicly available eICU Collaborative Research Database dataset and rigorously evaluate the vital sign forecasts using out-of-sample evaluation criteria. We present the performance of our model using error metrics, including mean squared error (MSE), mean average percentage error (MAPE), and dynamic time warping (DTW), where the best scores achieved are 18.52e-4, 7.60, and 17.63e-3, respectively. We analyze the samples where the forecasted trend does not match the actual trend and study the impact of infused drugs on changing the actual vital signs compared to the forecasted trend. Additionally, we examined the mortality rates of patients where the actual trend and the forecasted trend did not match. We observed that the mortality rate was higher (92%) when the actual and forecasted trends closely matched, compared to when they were not similar (84%).
Investigating Poor Performance Regions of Black Boxes: LIME-based Exploration in Sepsis Detection
Jun 21, 2023
Interpreting machine learning models remains a challenge, hindering their adoption in clinical settings. This paper proposes leveraging Local Interpretable Model-Agnostic Explanations (LIME) to provide interpretable descriptions of black box classification models in high-stakes sepsis detection. By analyzing misclassified instances, significant features contributing to suboptimal performance are identified. The analysis reveals regions where the classifier performs poorly, allowing the calculation of error rates within these regions. This knowledge is crucial for cautious decision-making in sepsis detection and other critical applications. The proposed approach is demonstrated using the eICU dataset, effectively identifying and visualizing regions where the classifier underperforms. By enhancing interpretability, our method promotes the adoption of machine learning models in clinical practice, empowering informed decision-making and mitigating risks in critical scenarios.