 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivided by discipline? A systematic literature review on the quantification of online sexism and misogyny using a semi-automated approach
Sep 30, 2024In recent years, several computational tools have been developed to detect and identify sexism, misogyny, and gender-based hate speech, especially on online platforms. Though these tools intend to draw on knowledge from both social science and computer science, little is known about the current state of research in quantifying online sexism or misogyny. Given the growing concern over the discrimination of women in online spaces and the rise in interdisciplinary research on capturing the online manifestation of sexism and misogyny, a systematic literature review on the research practices and their measures is the need of the hour. We make three main contributions: (i) we present a semi-automated way to narrow down the search results in the different phases of selection stage in the PRISMA flowchart; (ii) we perform a systematic literature review of research papers that focus on the quantification and measurement of online gender-based hate speech, examining literature from computer science and the social sciences from 2012 to 2022; and (iii) we identify the opportunities and challenges for measuring gender-based online hate speech. Our findings from topic analysis suggest a disciplinary divide between the themes of research on sexism/misogyny. With evidence-based review, we summarise the different approaches used by the studies who have explored interdisciplinary approaches to bridge the knowledge gap. Coupled with both the existing literature on social science theories and computational modeling, we provide an analysis of the benefits and shortcomings of the methodologies used. Lastly, we discuss the challenges and opportunities for future research dedicated to measuring online sexism and misogyny.
Deep learning generalizes because the parameter-function map is biased towards simple functions
Sep 28, 2018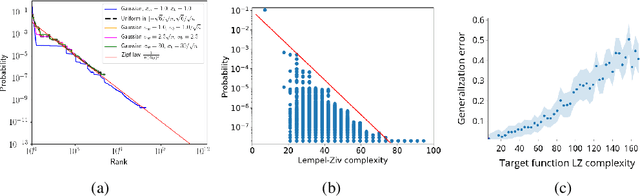

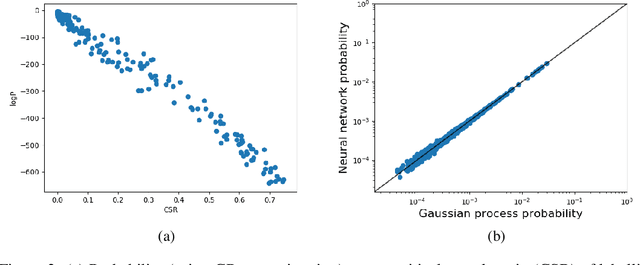

Deep neural networks generalize remarkably well without explicit regularization even in the strongly over-parametrized regime. This success suggests that some form of implicit regularization must be at work. In this paper we argue that a strong intrinsic bias in the parameter-function map helps explain the success of deep neural networks. We provide evidence that the parameter-function map results in a heavily biased prior over functions, if we assume that the training algorithm samples parameters close to uniformly within the zero-error region. The PAC-Bayes theorem then guarantees good expected generalization for target functions producing high-likelihood training sets. We exploit connections between deep neural networks and Gaussian processes to estimate the marginal likelihood, finding remarkably good agreement between Gaussian processes and neural networks for small input sets. Using approximate marginal likelihood calculations we produce nontrivial generalization PAC-Bayes error bounds which correlate well with the true error on realistic datasets such as MNIST and CIFAR and for architectures including convolutional and fully connected networks. As predicted by recent arguments based on algorithmic information theory, we find that the prior probability drops exponentially with linear increases in several measures of descriptional complexity of the target function. As target functions in many real problems are expected to be highly structured, this simplicity bias offers an insight into why deep networks generalize well on real world problems, but badly on randomized data.
Volatility in the Issue Attention Economy
Aug 27, 2018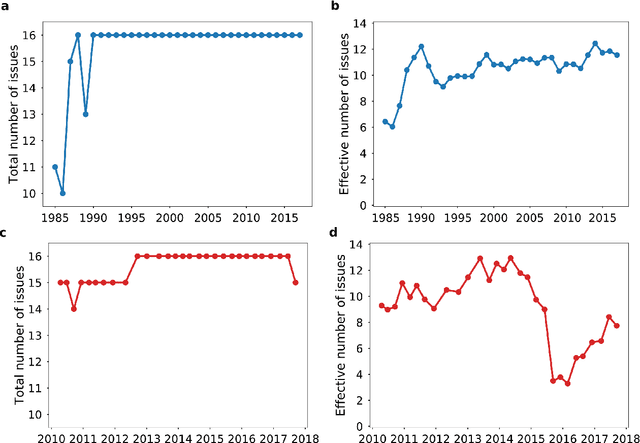
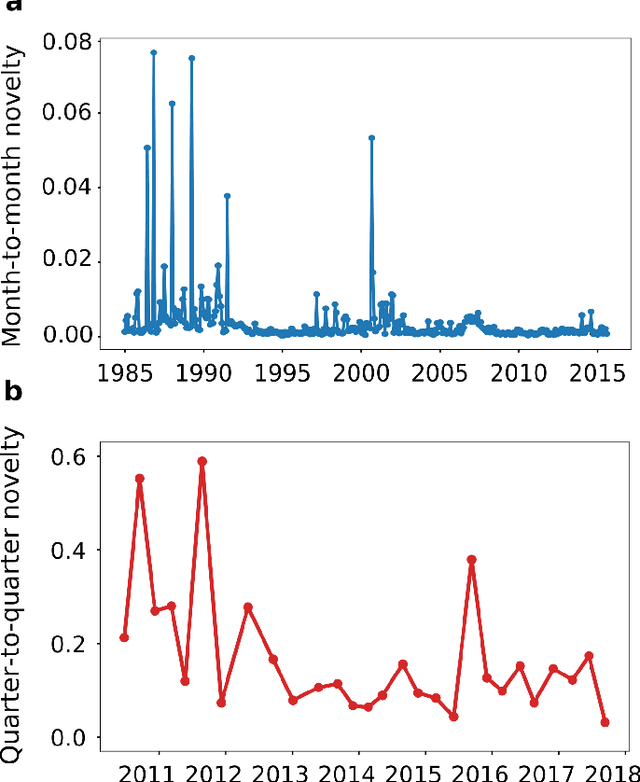
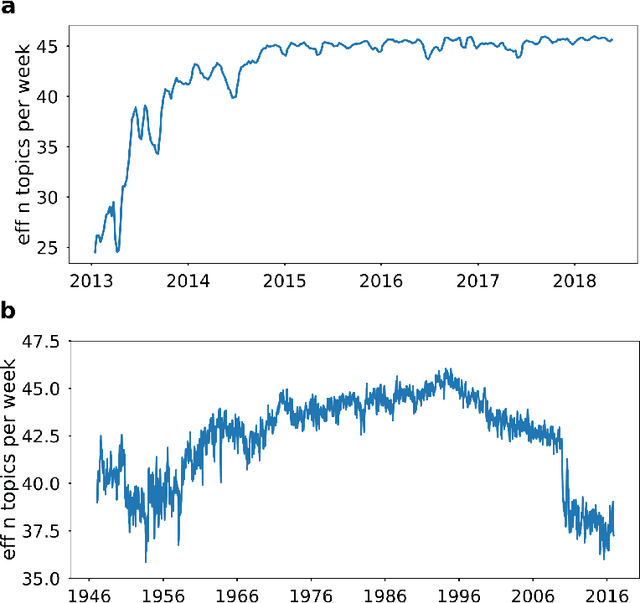
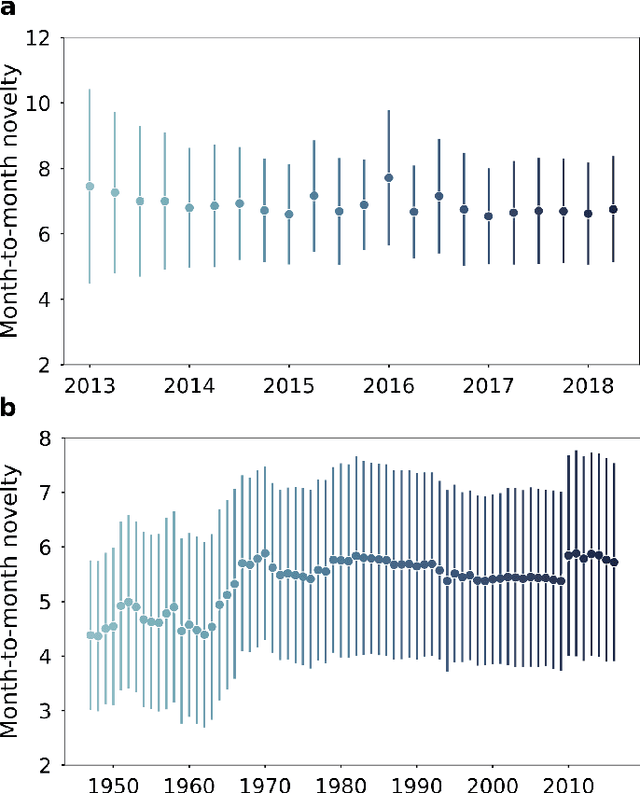
Recent election surprises and regime changes have left the impression that politics has become more fast-moving and unstable. While modern politics does seem more volatile, there is little systematic evidence to support this claim. This paper seeks to address this gap in knowledge by reporting data over the last seventy years using public opinion polls and traditional media data from the UK and Germany. These countries are good cases to study because both have experienced considerable changes in electoral behaviour and have new political parties during the time period studied. We measure volatility in public opinion and in media coverage using approaches from information theory, tracking the change in word-use patterns across over 700,000 articles. Our preliminary analysis suggests an increase in the number of opinion issues over time and a growth in lack of predictability of the media series from the 1970s.