 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning generalizes because the parameter-function map is biased towards simple functions
Paper and Code
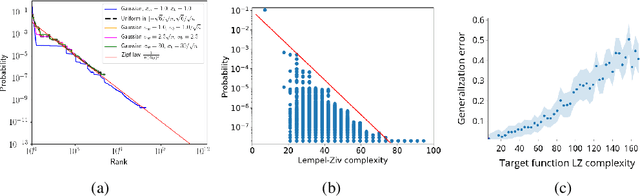

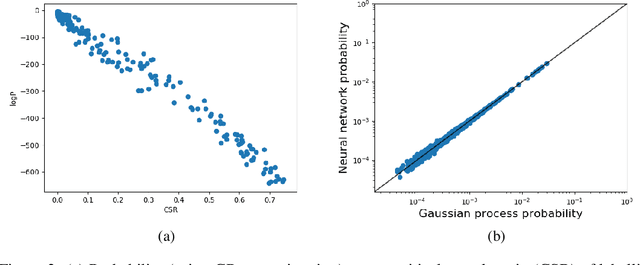

Deep neural networks generalize remarkably well without explicit regularization even in the strongly over-parametrized regime. This success suggests that some form of implicit regularization must be at work. In this paper we argue that a strong intrinsic bias in the parameter-function map helps explain the success of deep neural networks. We provide evidence that the parameter-function map results in a heavily biased prior over functions, if we assume that the training algorithm samples parameters close to uniformly within the zero-error region. The PAC-Bayes theorem then guarantees good expected generalization for target functions producing high-likelihood training sets. We exploit connections between deep neural networks and Gaussian processes to estimate the marginal likelihood, finding remarkably good agreement between Gaussian processes and neural networks for small input sets. Using approximate marginal likelihood calculations we produce nontrivial generalization PAC-Bayes error bounds which correlate well with the true error on realistic datasets such as MNIST and CIFAR and for architectures including convolutional and fully connected networks. As predicted by recent arguments based on algorithmic information theory, we find that the prior probability drops exponentially with linear increases in several measures of descriptional complexity of the target function. As target functions in many real problems are expected to be highly structured, this simplicity bias offers an insight into why deep networks generalize well on real world problems, but badly on randomized data.