 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Backpropagation for Training Autoencoders against Adversarial Attack
Mar 04, 2020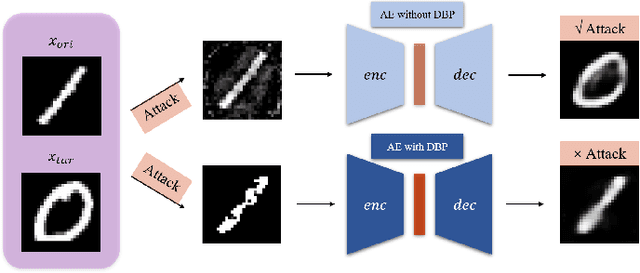

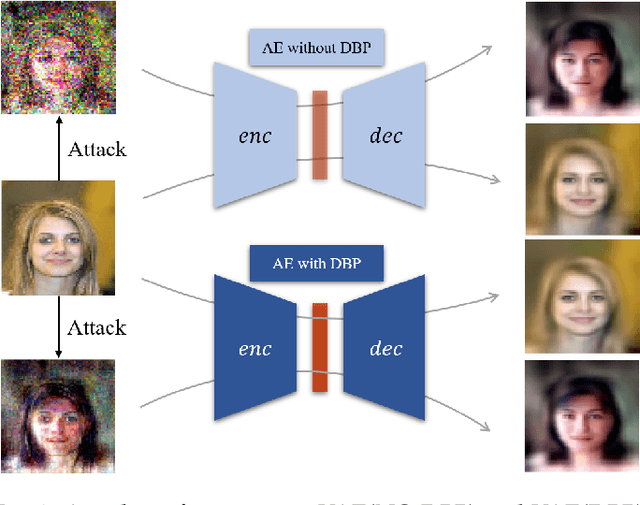

Deep learning, as widely known, is vulnerable to adversarial samples. This paper focuses on the adversarial attack on autoencoders. Safety of the autoencoders (AEs) is important because they are widely used as a compression scheme for data storage and transmission, however, the current autoencoders are easily attacked, i.e., one can slightly modify an input but has totally different codes. The vulnerability is rooted the sensitivity of the autoencoders and to enhance the robustness, we propose to adopt double backpropagation (DBP) to secure autoencoder such as VAE and DRAW. We restrict the gradient from the reconstruction image to the original one so that the autoencoder is not sensitive to trivial perturbation produced by the adversarial attack. After smoothing the gradient by DBP, we further smooth the label by Gaussian Mixture Model (GMM), aiming for accurate and robust classification. We demonstrate in MNIST, CelebA, SVHN that our method leads to a robust autoencoder resistant to attack and a robust classifier able for image transition and immune to adversarial attack if combined with GMM.
Type I Attack for Generative Models
Mar 04, 2020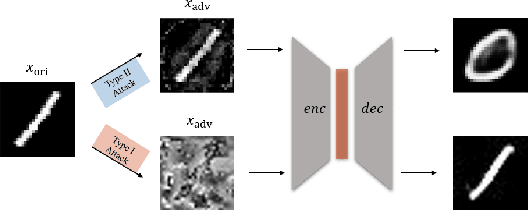
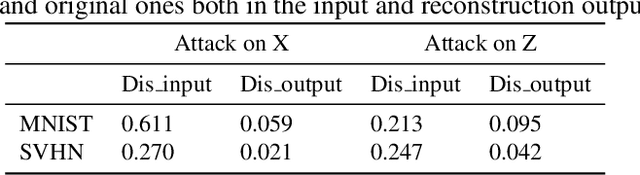
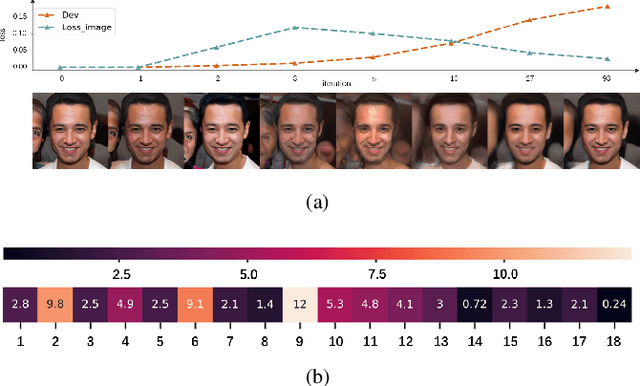

Generative models are popular tools with a wide range of applications. Nevertheless, it is as vulnerable to adversarial samples as classifiers. The existing attack methods mainly focus on generating adversarial examples by adding imperceptible perturbations to input, which leads to wrong result. However, we focus on another aspect of attack, i.e., cheating models by significant changes. The former induces Type II error and the latter causes Type I error. In this paper, we propose Type I attack to generative models such as VAE and GAN. One example given in VAE is that we can change an original image significantly to a meaningless one but their reconstruction results are similar. To implement the Type I attack, we destroy the original one by increasing the distance in input space while keeping the output similar because different inputs may correspond to similar features for the property of deep neural network. Experimental results show that our attack method is effective to generate Type I adversarial examples for generative models on large-scale image datasets.
Generate High-Resolution Adversarial Samples by Identifying Effective Features
Jan 21, 2020
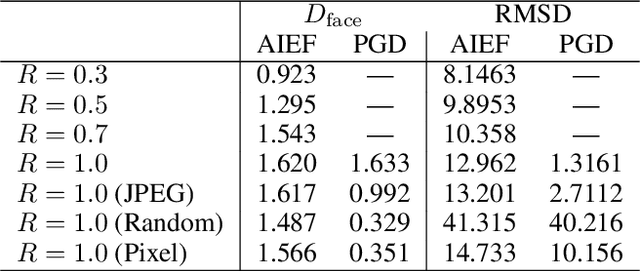
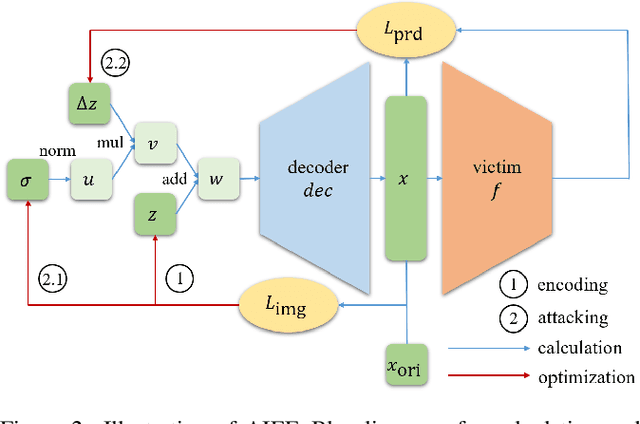

As the prevalence of deep learning in computer vision, adversarial samples that weaken the neural networks emerge in large numbers, revealing their deep-rooted defects. Most adversarial attacks calculate an imperceptible perturbation in image space to fool the DNNs. In this strategy, the perturbation looks like noise and thus could be mitigated. Attacks in feature space produce semantic perturbation, but they could only deal with low resolution samples. The reason lies in the great number of coupled features to express a high-resolution image. In this paper, we propose Attack by Identifying Effective Features (AIEF), which learns different weights for features to attack. Effective features, those with great weights, influence the victim model much but distort the image little, and thus are more effective for attack. By attacking mostly on them, AIEF produces high resolution adversarial samples with acceptable distortions. We demonstrate the effectiveness of AIEF by attacking on different tasks with different generative models.
Universal Adversarial Attack on Attention and the Resulting Dataset DAmageNet
Jan 16, 2020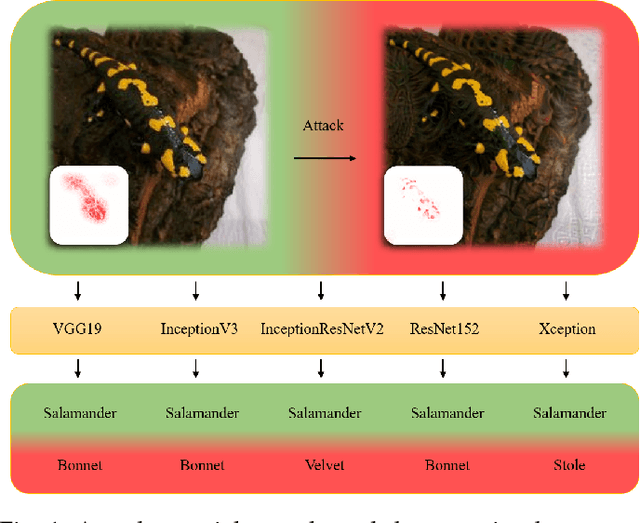
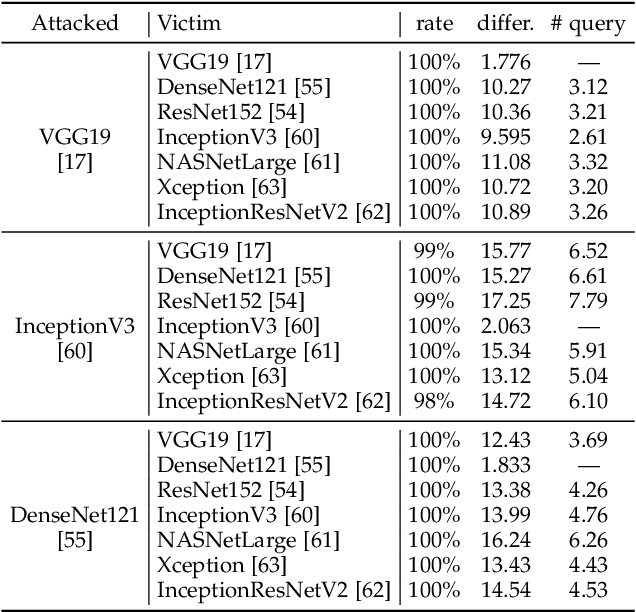


Adversarial attacks on deep neural networks (DNNs) have been found for several years. However, the existing adversarial attacks have high success rates only when the information of the attacked DNN is well-known or could be estimated by structure similarity or massive queries. In this paper, we propose an \emph{Attack on Attention} (AoA), a semantic feature commonly shared by DNNs. The transferability of AoA is quite high. With no more than 10 queries of the decision only, AoA can achieve almost 100\% success rate when attacking on many popular DNNs. Even without query, AoA could keep a surprisingly high attack performance. We apply AoA to generate 96020 adversarial samples from ImageNet to defeat many neural networks, and thus name the dataset as \emph{DAmageNet}. 20 well-trained DNNs are tested on DAmageNet. Without adversarial training, most of the tested DNNs have an error rate over 90\%. DAmageNet is the first universal adversarial dataset and it could serve as a benchmark for robustness testing and adversarial training.
DAmageNet: A Universal Adversarial Dataset
Dec 16, 2019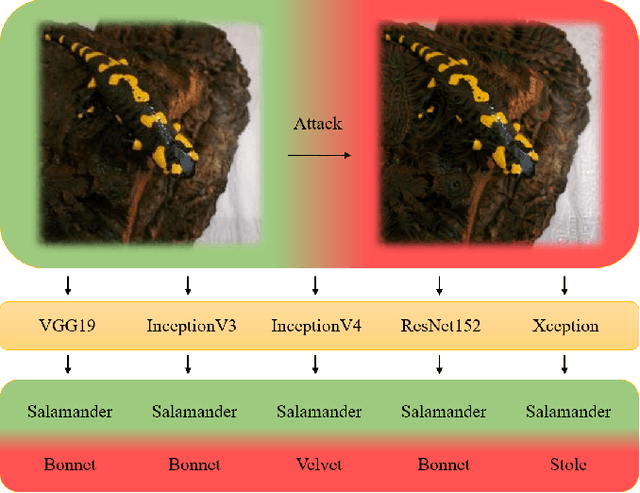
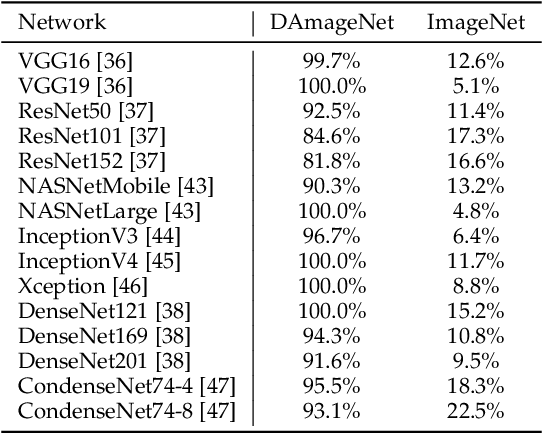

It is now well known that deep neural networks (DNNs) are vulnerable to adversarial attack. Adversarial samples are similar to the clean ones, but are able to cheat the attacked DNN to produce incorrect predictions in high confidence. But most of the existing adversarial attacks have high success rate only when the information of the attacked DNN is well-known or could be estimated by massive queries. A promising way is to generate adversarial samples with high transferability. By this way, we generate 96020 transferable adversarial samples from original ones in ImageNet. The average difference, measured by root means squared deviation, is only around 3.8 on average. However, the adversarial samples are misclassified by various models with an error rate up to 90\%. Since the images are generated independently with the attacked DNNs, this is essentially zero-query adversarial attack. We call the dataset \emph{DAmageNet}, which is the first universal adversarial dataset that beats many models trained in ImageNet. By finding the drawbacks, DAmageNet could serve as a benchmark to study and improve robustness of DNNs. DAmageNet could be downloaded in http://www.pami.sjtu.edu.cn/Show/56/122.