 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Backpropagation for Training Autoencoders against Adversarial Attack
Paper and Code
Mar 04, 2020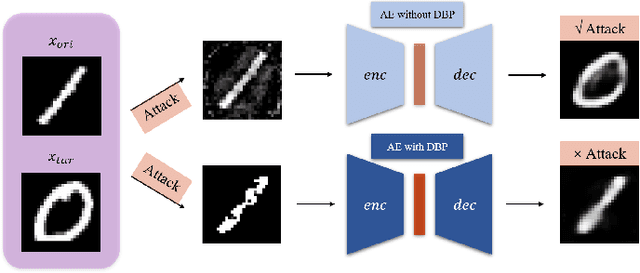

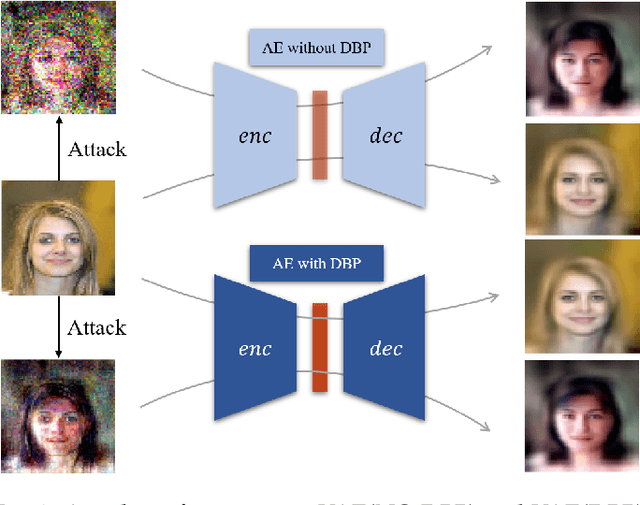

Deep learning, as widely known, is vulnerable to adversarial samples. This paper focuses on the adversarial attack on autoencoders. Safety of the autoencoders (AEs) is important because they are widely used as a compression scheme for data storage and transmission, however, the current autoencoders are easily attacked, i.e., one can slightly modify an input but has totally different codes. The vulnerability is rooted the sensitivity of the autoencoders and to enhance the robustness, we propose to adopt double backpropagation (DBP) to secure autoencoder such as VAE and DRAW. We restrict the gradient from the reconstruction image to the original one so that the autoencoder is not sensitive to trivial perturbation produced by the adversarial attack. After smoothing the gradient by DBP, we further smooth the label by Gaussian Mixture Model (GMM), aiming for accurate and robust classification. We demonstrate in MNIST, CelebA, SVHN that our method leads to a robust autoencoder resistant to attack and a robust classifier able for image transition and immune to adversarial attack if combined with GMM.