 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeType I Attack for Generative Models
Paper and Code
Mar 04, 2020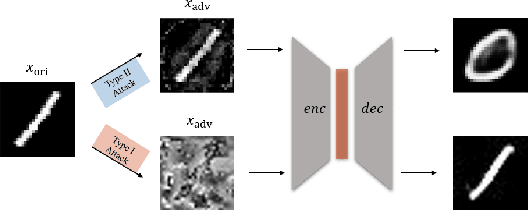
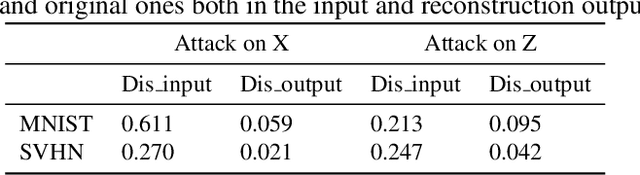

Generative models are popular tools with a wide range of applications. Nevertheless, it is as vulnerable to adversarial samples as classifiers. The existing attack methods mainly focus on generating adversarial examples by adding imperceptible perturbations to input, which leads to wrong result. However, we focus on another aspect of attack, i.e., cheating models by significant changes. The former induces Type II error and the latter causes Type I error. In this paper, we propose Type I attack to generative models such as VAE and GAN. One example given in VAE is that we can change an original image significantly to a meaningless one but their reconstruction results are similar. To implement the Type I attack, we destroy the original one by increasing the distance in input space while keeping the output similar because different inputs may correspond to similar features for the property of deep neural network. Experimental results show that our attack method is effective to generate Type I adversarial examples for generative models on large-scale image datasets.