 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Private Online Learning for Social Big Data Computing over Data Center Networks
Feb 21, 2016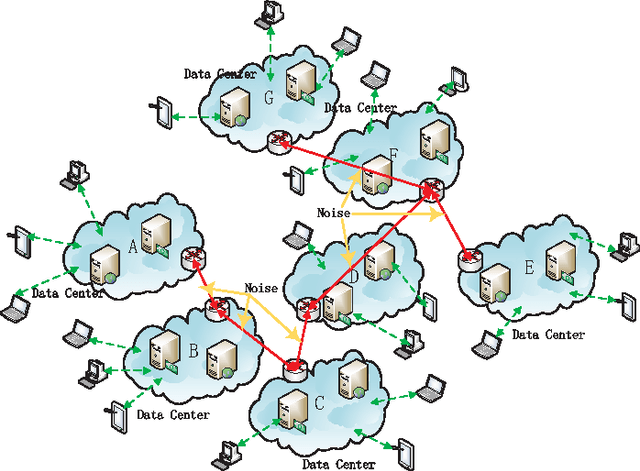
With the rapid growth of Internet technologies, cloud computing and social networks have become ubiquitous. An increasing number of people participate in social networks and massive online social data are obtained. In order to exploit knowledge from copious amounts of data obtained and predict social behavior of users, we urge to realize data mining in social networks. Almost all online websites use cloud services to effectively process the large scale of social data, which are gathered from distributed data centers. These data are so large-scale, high-dimension and widely distributed that we propose a distributed sparse online algorithm to handle them. Additionally, privacy-protection is an important point in social networks. We should not compromise the privacy of individuals in networks, while these social data are being learned for data mining. Thus we also consider the privacy problem in this article. Our simulations shows that the appropriate sparsity of data would enhance the performance of our algorithm and the privacy-preserving method does not significantly hurt the performance of the proposed algorithm.
Differentially Private Distributed Online Learning
Jun 23, 2015


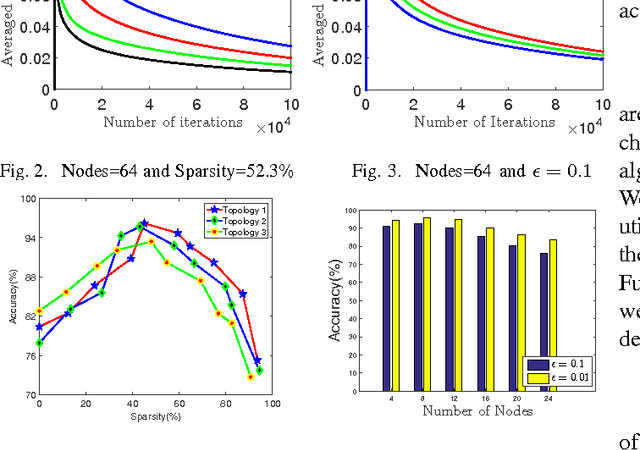
Online learning has been in the spotlight from the machine learning society for a long time. To handle massive data in Big Data era, one single learner could never efficiently finish this heavy task. Hence, in this paper, we propose a novel distributed online learning algorithm to solve the problem. Comparing to typical centralized online learner, the distributed learners optimize their own learning parameters based on local data sources and timely communicate with neighbors. However, communication may lead to a privacy breach. Thus, we use differential privacy to preserve the privacy of learners, and study the influence of guaranteeing differential privacy on the utility of the distributed online learning algorithm. Furthermore, by using the results from Kakade and Tewari (2009), we use the regret bounds of online learning to achieve fast convergence rates for offline learning algorithms in distributed scenarios, which provides tighter utility performance than the existing state-of-the-art results. In simulation, we demonstrate that the differentially private offline learning algorithm has high variance, but we can use mini-batch to improve the performance. Finally, the simulations show that the analytical results of our proposed theorems are right and our private distributed online learning algorithm is a general framework.