 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Based Sequence Classification
May 17, 2019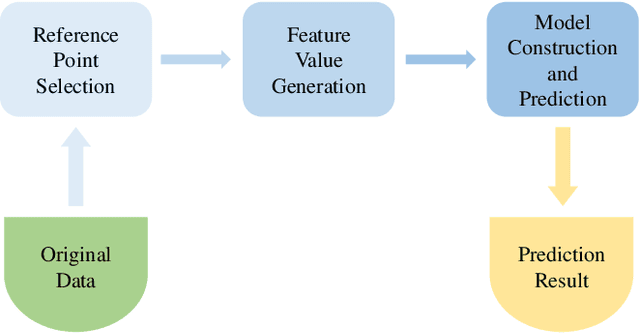
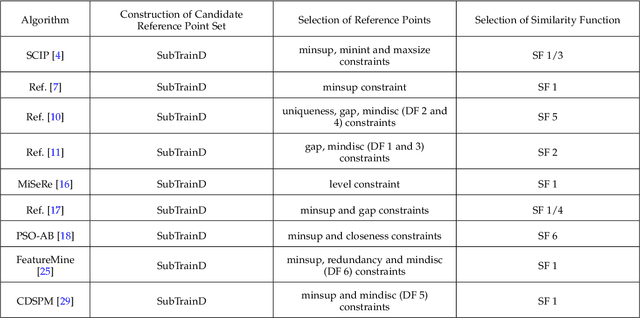
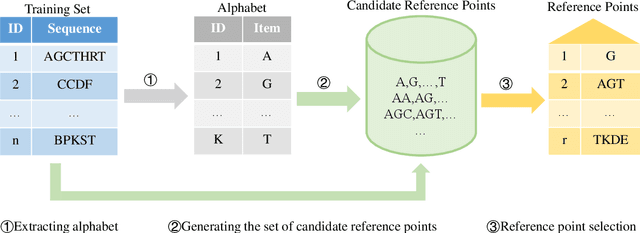
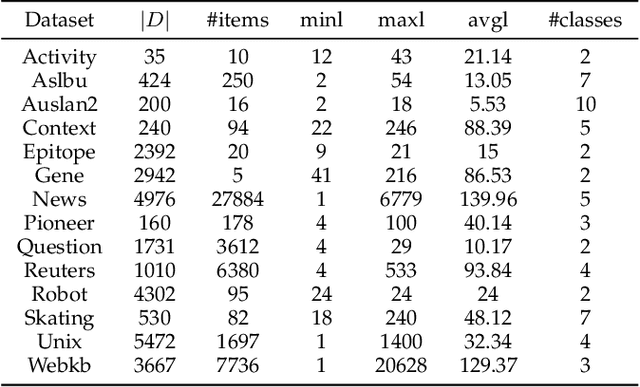
Sequence classification is an important data mining task in many real world applications. Over the past few decades, many sequence classification methods have been proposed from different aspects. In particular, the pattern-based method is one of the most important and widely studied sequence classification methods in the literature. In this paper, we present a reference-based sequence classification framework, which can unify existing pattern-based sequence classification methods under the same umbrella. More importantly, this framework can be used as a general platform for developing new sequence classification algorithms. By utilizing this framework as a tool, we propose new sequence classification algorithms that are quite different from existing solutions. Experimental results show that new methods developed under the proposed framework are capable of achieving comparable classification accuracy to those state-of-the-art sequence classification algorithms.
Instance-Based Classification through Hypothesis Testing
Jan 03, 2019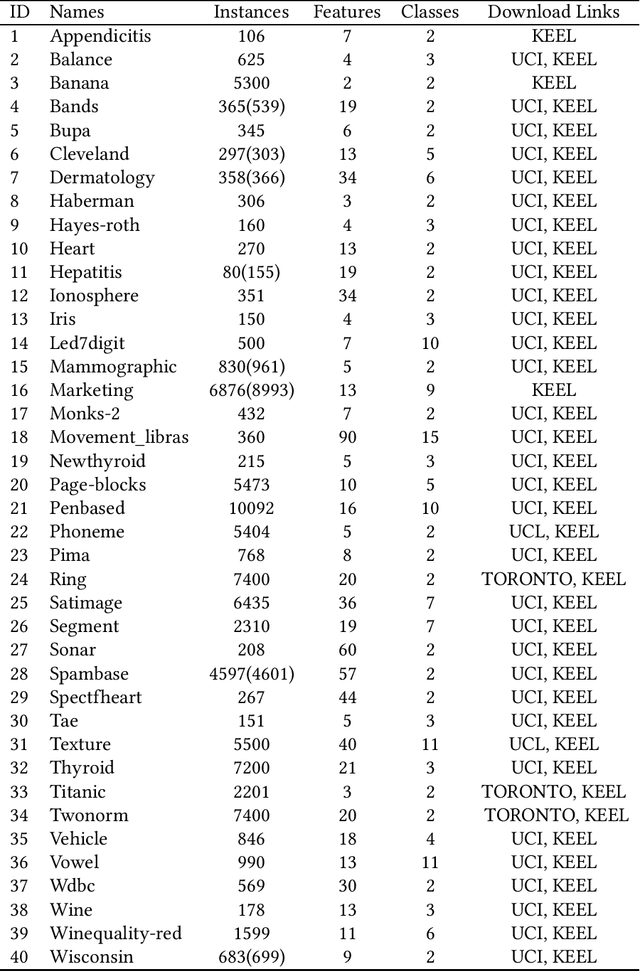
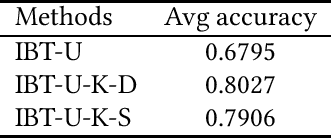

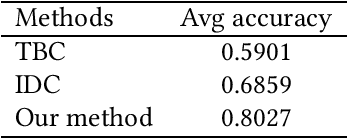
Classification is a fundamental problem in machine learning and data mining. During the past decades, numerous classification methods have been presented based on different principles. However, most existing classifiers cast the classification problem as an optimization problem and do not address the issue of statistical significance. In this paper, we formulate the binary classification problem as a two-sample testing problem. More precisely, our classification model is a generic framework that is composed of two steps. In the first step, the distance between the test instance and each training instance is calculated to derive two distance sets. In the second step, the two-sample test is performed under the null hypothesis that the two sets of distances are drawn from the same cumulative distribution. After these two steps, we have two p-values for each test instance and the test instance is assigned to the class associated with the smaller p-value. Essentially, the presented classification method can be regarded as an instance-based classifier based on hypothesis testing. The experimental results on 40 real data sets show that our method is able to achieve the same level performance as the state-of-the-art classifiers and has significantly better performance than existing testing-based classifiers. Furthermore, we can handle outlying instances and control the false discovery rate of test instances assigned to each class under the same framework.