 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Textual Personality Detection toward Social Media: Integrating Long-term and Short-term Perspectives
Apr 23, 2024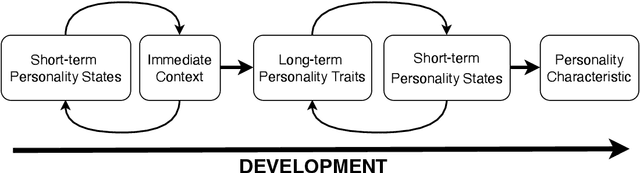
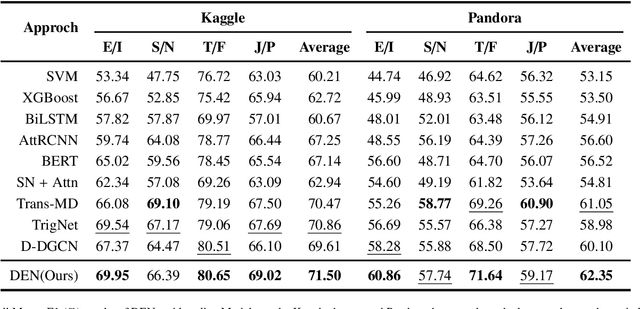
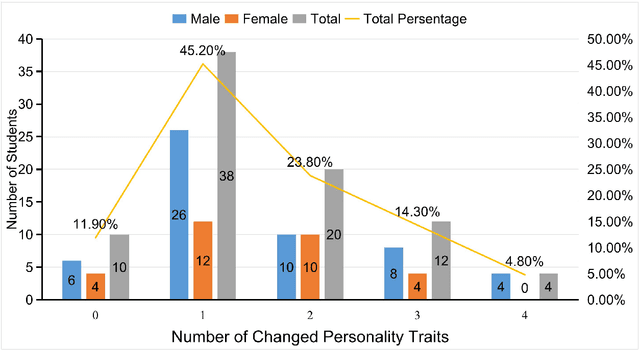
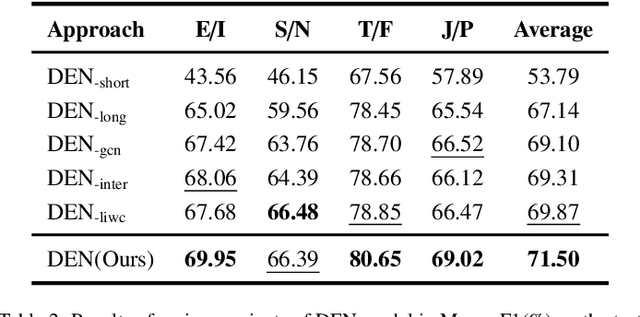
Textual personality detection aims to identify personality characteristics by analyzing user-generated content toward social media platforms. Numerous psychological literature highlighted that personality encompasses both long-term stable traits and short-term dynamic states. However, existing studies often concentrate only on either long-term or short-term personality representations, without effectively combining both aspects. This limitation hinders a comprehensive understanding of individuals' personalities, as both stable traits and dynamic states are vital. To bridge this gap, we propose a Dual Enhanced Network(DEN) to jointly model users' long-term and short-term personality for textual personality detection. In DEN, a Long-term Personality Encoding is devised to effectively model long-term stable personality traits. Short-term Personality Encoding is presented to capture short-term dynamic personality states. The Bi-directional Interaction component facilitates the integration of both personality aspects, allowing for a comprehensive representation of the user's personality. Experimental results on two personality detection datasets demonstrate the effectiveness of the DEN model and the benefits of considering both the dynamic and stable nature of personality characteristics for textual personality detection.
Facilitating Fine-grained Detection of Chinese Toxic Language: Hierarchical Taxonomy, Resources, and Benchmarks
May 08, 2023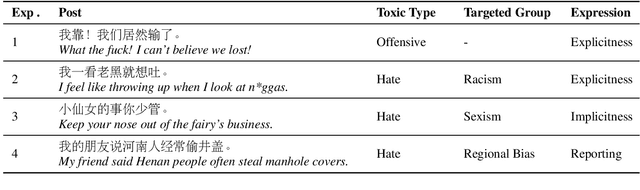
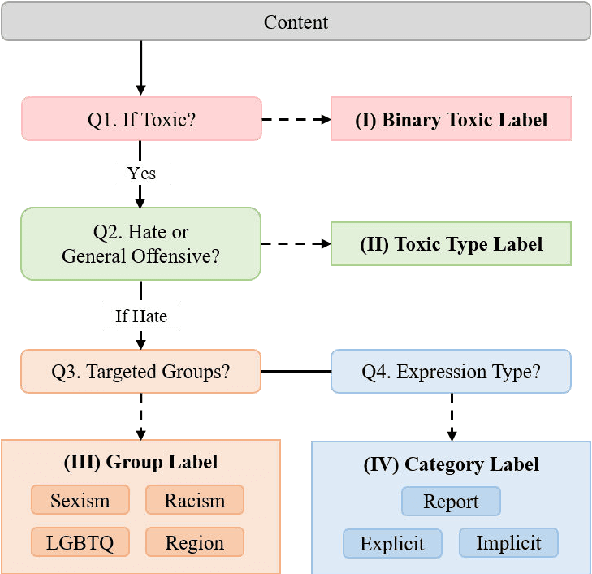
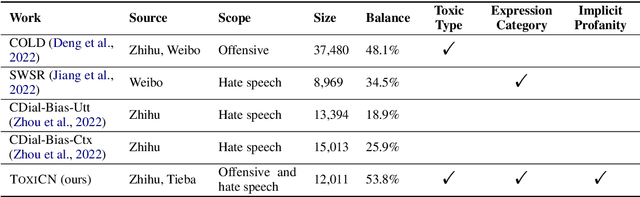
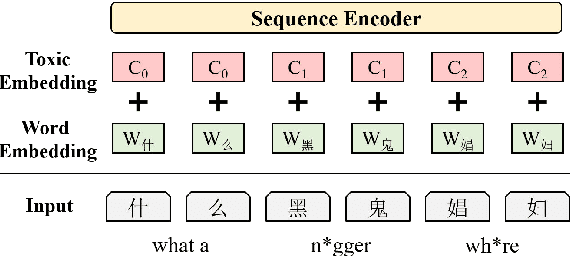
The widespread dissemination of toxic online posts is increasingly damaging to society. However, research on detecting toxic language in Chinese has lagged significantly. Existing datasets lack fine-grained annotation of toxic types and expressions, and ignore the samples with indirect toxicity. In addition, it is crucial to introduce lexical knowledge to detect the toxicity of posts, which has been a challenge for researchers. In this paper, we facilitate the fine-grained detection of Chinese toxic language. First, we built Monitor Toxic Frame, a hierarchical taxonomy to analyze toxic types and expressions. Then, a fine-grained dataset ToxiCN is presented, including both direct and indirect toxic samples. We also build an insult lexicon containing implicit profanity and propose Toxic Knowledge Enhancement (TKE) as a benchmark, incorporating the lexical feature to detect toxic language. In the experimental stage, we demonstrate the effectiveness of TKE. After that, a systematic quantitative and qualitative analysis of the findings is given.