 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode Feature Kernels Increase Graph Convolutional Network Robustness
Sep 04, 2021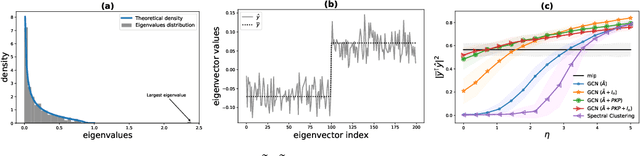
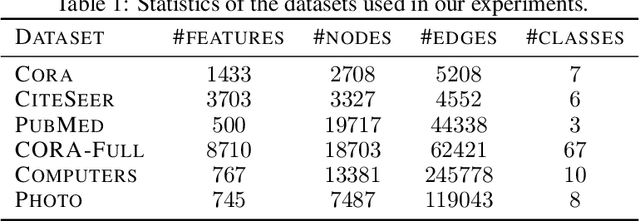
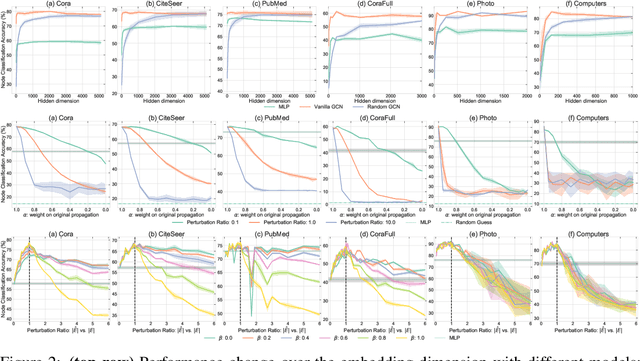
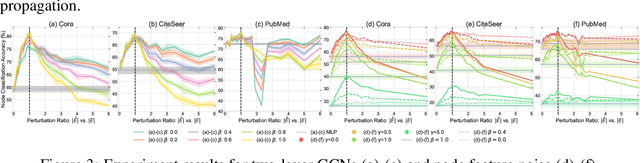
The robustness of the much-used Graph Convolutional Networks (GCNs) to perturbations of their input is becoming a topic of increasing importance. In this paper, the random GCN is introduced for which a random matrix theory analysis is possible. This analysis suggests that if the graph is sufficiently perturbed, or in the extreme case random, then the GCN fails to benefit from the node features. It is furthermore observed that enhancing the message passing step in GCNs by adding the node feature kernel to the adjacency matrix of the graph structure solves this problem. An empirical study of a GCN utilised for node classification on six real datasets further confirms the theoretical findings and demonstrates that perturbations of the graph structure can result in GCNs performing significantly worse than Multi-Layer Perceptrons run on the node features alone. In practice, adding a node feature kernel to the message passing of perturbed graphs results in a significant improvement of the GCN's performance, thereby rendering it more robust to graph perturbations. Our code is publicly available at:https://github.com/ChangminWu/RobustGCN.
Sparsifying the Update Step in Graph Neural Networks
Sep 02, 2021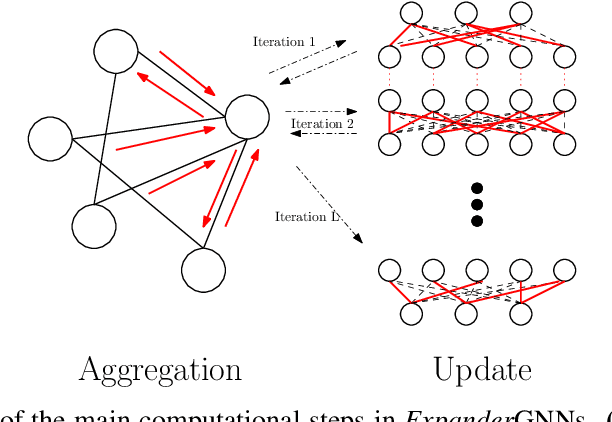

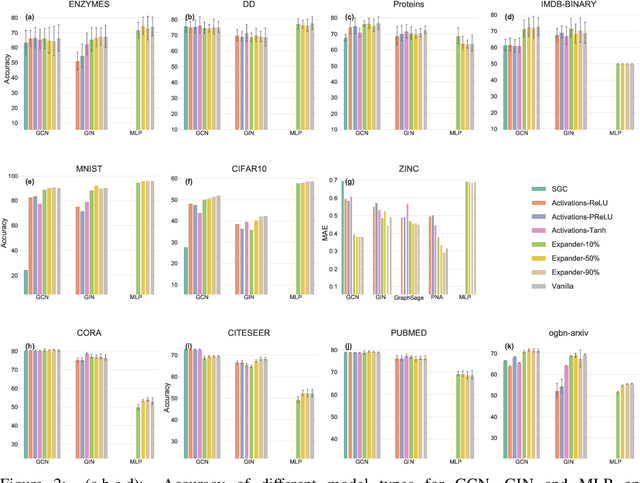
Message-Passing Neural Networks (MPNNs), the most prominent Graph Neural Network (GNN) framework, celebrate much success in the analysis of graph-structured data. Concurrently, the sparsification of Neural Network models attracts a great amount of academic and industrial interest. In this paper, we conduct a structured study of the effect of sparsification on the trainable part of MPNNs known as the Update step. To this end, we design a series of models to successively sparsify the linear transform in the Update step. Specifically, we propose the ExpanderGNN model with a tuneable sparsification rate and the Activation-Only GNN, which has no linear transform in the Update step. In agreement with a growing trend in the literature, the sparsification paradigm is changed by initialising sparse neural network architectures rather than expensively sparsifying already trained architectures. Our novel benchmark models enable a better understanding of the influence of the Update step on model performance and outperform existing simplified benchmark models such as the Simple Graph Convolution. The ExpanderGNNs, and in some cases the Activation-Only models, achieve performance on par with their vanilla counterparts on several downstream tasks while containing significantly fewer trainable parameters. In experiments with matching parameter numbers, our benchmark models outperform the state-of-the-art GNN models. Our code is publicly available at: https://github.com/ChangminWu/ExpanderGNN.
EvoNet: A Neural Network for Predicting the Evolution of Dynamic Graphs
Mar 02, 2020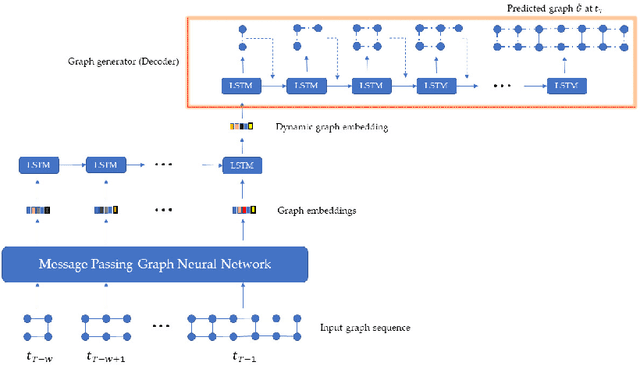
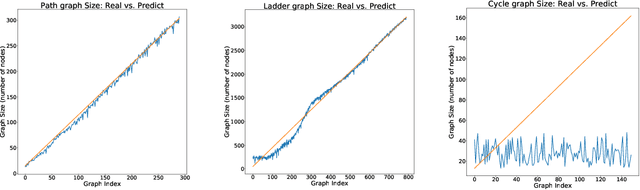
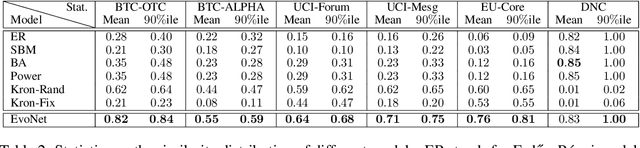
Neural networks for structured data like graphs have been studied extensively in recent years. To date, the bulk of research activity has focused mainly on static graphs. However, most real-world networks are dynamic since their topology tends to change over time. Predicting the evolution of dynamic graphs is a task of high significance in the area of graph mining. Despite its practical importance, the task has not been explored in depth so far, mainly due to its challenging nature. In this paper, we propose a model that predicts the evolution of dynamic graphs. Specifically, we use a graph neural network along with a recurrent architecture to capture the temporal evolution patterns of dynamic graphs. Then, we employ a generative model which predicts the topology of the graph at the next time step and constructs a graph instance that corresponds to that topology. We evaluate the proposed model on several artificial datasets following common network evolving dynamics, as well as on real-world datasets. Results demonstrate the effectiveness of the proposed model.