 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual Basis Approach for Structured Robust Euclidean Distance Geometry
May 23, 2025Euclidean Distance Matrix (EDM), which consists of pairwise squared Euclidean distances of a given point configuration, finds many applications in modern machine learning. This paper considers the setting where only a set of anchor nodes is used to collect the distances between themselves and the rest. In the presence of potential outliers, it results in a structured partial observation on EDM with partial corruptions. Note that an EDM can be connected to a positive semi-definite Gram matrix via a non-orthogonal dual basis. Inspired by recent development of non-orthogonal dual basis in optimization, we propose a novel algorithmic framework, dubbed Robust Euclidean Distance Geometry via Dual Basis (RoDEoDB), for recovering the Euclidean distance geometry, i.e., the underlying point configuration. The exact recovery guarantees have been established in terms of both the Gram matrix and point configuration, under some mild conditions. Empirical experiments show superior performance of RoDEoDB on sensor localization and molecular conformation datasets.
Deeply Learned Robust Matrix Completion for Large-scale Low-rank Data Recovery
Dec 31, 2024



Robust matrix completion (RMC) is a widely used machine learning tool that simultaneously tackles two critical issues in low-rank data analysis: missing data entries and extreme outliers. This paper proposes a novel scalable and learnable non-convex approach, coined Learned Robust Matrix Completion (LRMC), for large-scale RMC problems. LRMC enjoys low computational complexity with linear convergence. Motivated by the proposed theorem, the free parameters of LRMC can be effectively learned via deep unfolding to achieve optimum performance. Furthermore, this paper proposes a flexible feedforward-recurrent-mixed neural network framework that extends deep unfolding from fix-number iterations to infinite iterations. The superior empirical performance of LRMC is verified with extensive experiments against state-of-the-art on synthetic datasets and real applications, including video background subtraction, ultrasound imaging, face modeling, and cloud removal from satellite imagery.
Structured Sampling for Robust Euclidean Distance Geometry
Dec 14, 2024This paper addresses the problem of estimating the positions of points from distance measurements corrupted by sparse outliers. Specifically, we consider a setting with two types of nodes: anchor nodes, for which exact distances to each other are known, and target nodes, for which complete but corrupted distance measurements to the anchors are available. To tackle this problem, we propose a novel algorithm powered by Nystr\"om method and robust principal component analysis. Our method is computationally efficient as it processes only a localized subset of the distance matrix and does not require distance measurements between target nodes. Empirical evaluations on synthetic datasets, designed to mimic sensor localization, and on molecular experiments, demonstrate that our algorithm achieves accurate recovery with a modest number of anchors, even in the presence of high levels of sparse outliers.
On the Robustness of Cross-Concentrated Sampling for Matrix Completion
Jan 28, 2024



Matrix completion is one of the crucial tools in modern data science research. Recently, a novel sampling model for matrix completion coined cross-concentrated sampling (CCS) has caught much attention. However, the robustness of the CCS model against sparse outliers remains unclear in the existing studies. In this paper, we aim to answer this question by exploring a novel Robust CCS Completion problem. A highly efficient non-convex iterative algorithm, dubbed Robust CUR Completion (RCURC), is proposed. The empirical performance of the proposed algorithm, in terms of both efficiency and robustness, is verified in synthetic and real datasets.
Deep multi-modal networks for book genre classification based on its cover
Nov 15, 2020
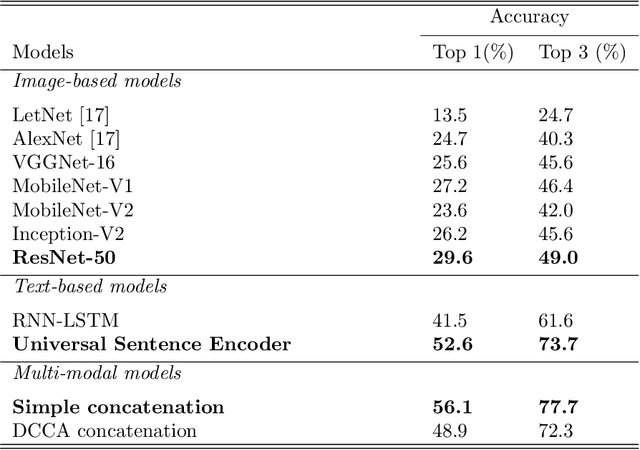
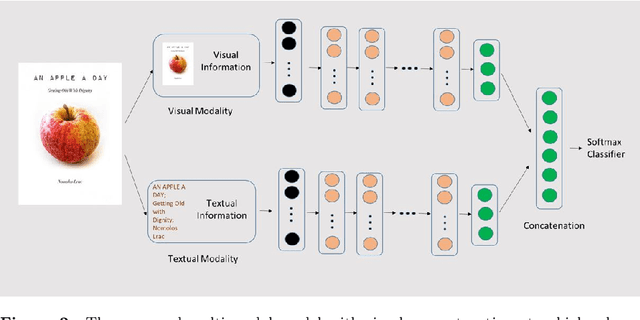
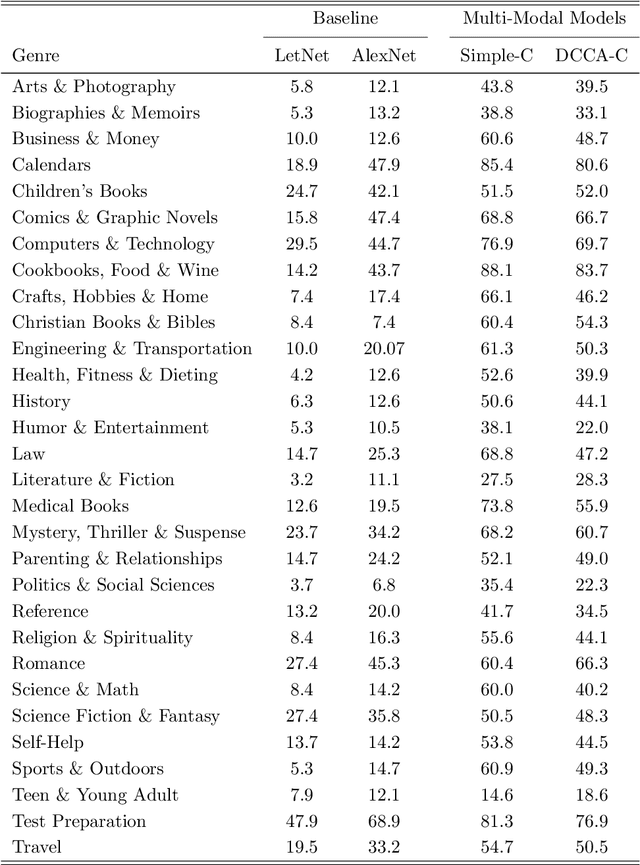
Book covers are usually the very first impression to its readers and they often convey important information about the content of the book. Book genre classification based on its cover would be utterly beneficial to many modern retrieval systems, considering that the complete digitization of books is an extremely expensive task. At the same time, it is also an extremely challenging task due to the following reasons: First, there exists a wide variety of book genres, many of which are not concretely defined. Second, book covers, as graphic designs, vary in many different ways such as colors, styles, textual information, etc, even for books of the same genre. Third, book cover designs may vary due to many external factors such as country, culture, target reader populations, etc. With the growing competitiveness in the book industry, the book cover designers and typographers push the cover designs to its limit in the hope of attracting sales. The cover-based book classification systems become a particularly exciting research topic in recent years. In this paper, we propose a multi-modal deep learning framework to solve this problem. The contribution of this paper is four-fold. First, our method adds an extra modality by extracting texts automatically from the book covers. Second, image-based and text-based, state-of-the-art models are evaluated thoroughly for the task of book cover classification. Third, we develop an efficient and salable multi-modal framework based on the images and texts shown on the covers only. Fourth, a thorough analysis of the experimental results is given and future works to improve the performance is suggested. The results show that the multi-modal framework significantly outperforms the current state-of-the-art image-based models. However, more efforts and resources are needed for this classification task in order to reach a satisfactory level.