 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Prediction-Focused Mixtures
Oct 27, 2021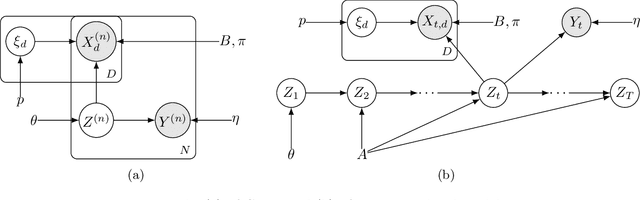
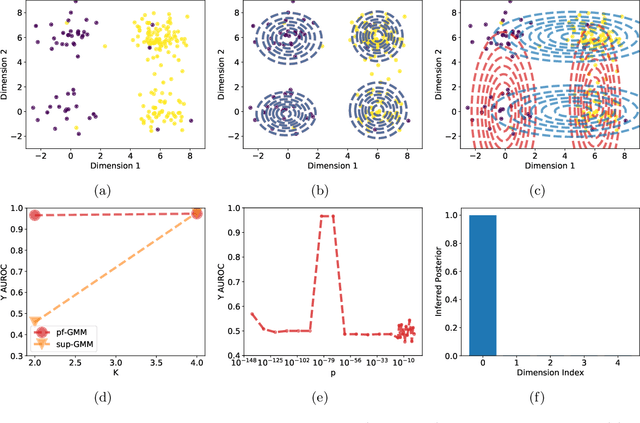
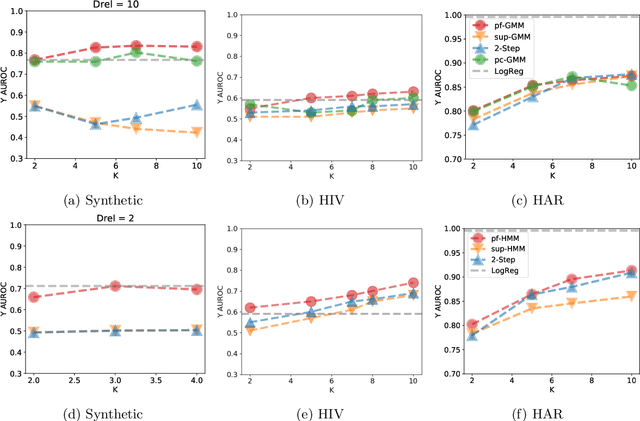
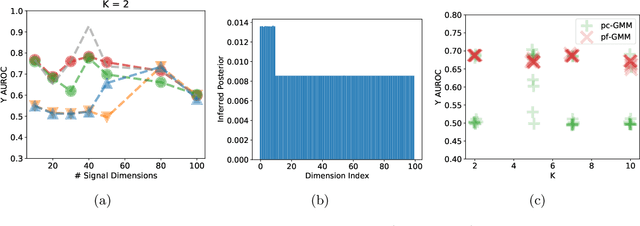
Probabilistic models help us encode latent structures that both model the data and are ideally also useful for specific downstream tasks. Among these, mixture models and their time-series counterparts, hidden Markov models, identify discrete components in the data. In this work, we focus on a constrained capacity setting, where we want to learn a model with relatively few components (e.g. for interpretability purposes). To maintain prediction performance, we introduce prediction-focused modeling for mixtures, which automatically selects the dimensions relevant to the prediction task. Our approach identifies relevant signal from the input, outperforms models that are not prediction-focused, and is easy to optimize; we also characterize when prediction-focused modeling can be expected to work.