 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning for Compilation of a Quantum Algorithm for Graph Coloring
Feb 23, 2020
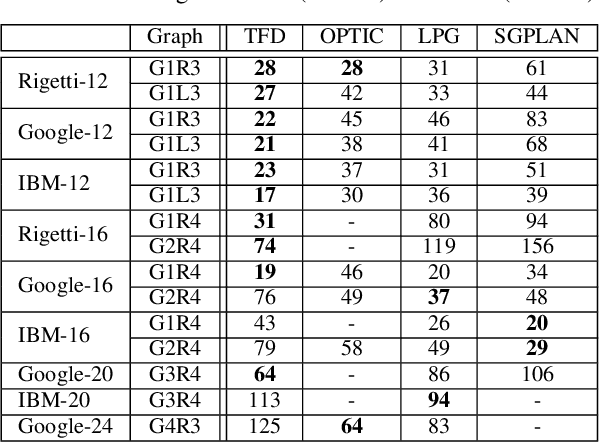
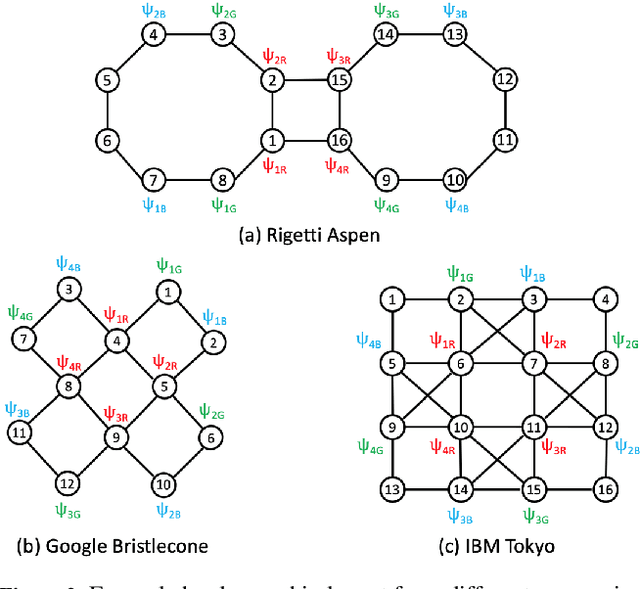
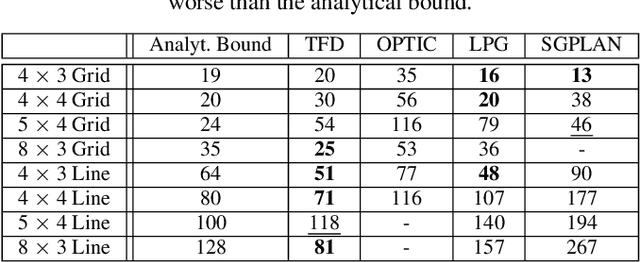
The problem of compiling general quantum algorithms for implementation on near-term quantum processors has been introduced to the AI community. Previous work demonstrated that temporal planning is an attractive approach for part of this compilationtask, specifically, the routing of circuits that implement the Quantum Alternating Operator Ansatz (QAOA) applied to the MaxCut problem on a quantum processor architecture. In this paper, we extend the earlier work to route circuits that implement QAOA for Graph Coloring problems. QAOA for coloring requires execution of more, and more complex, operations on the chip, which makes routing a more challenging problem. We evaluate the approach on state-of-the-art hardware architectures from leading quantum computing companies. Additionally, we apply a planning approach to qubit initialization. Our empirical evaluation shows that temporal planning compares well to reasonable analytic upper bounds, and that solving qubit initialization with a classical planner generally helps temporal planners in finding shorter-makespan compilations for QAOA for Graph Coloring. These advances suggest that temporal planning can be an effective approach for more complex quantum computing algorithms and architectures.
* 8 pages, 4 tables, 5 figures
Bayesian Network Structure Learning Using Quantum Annealing
Oct 02, 2014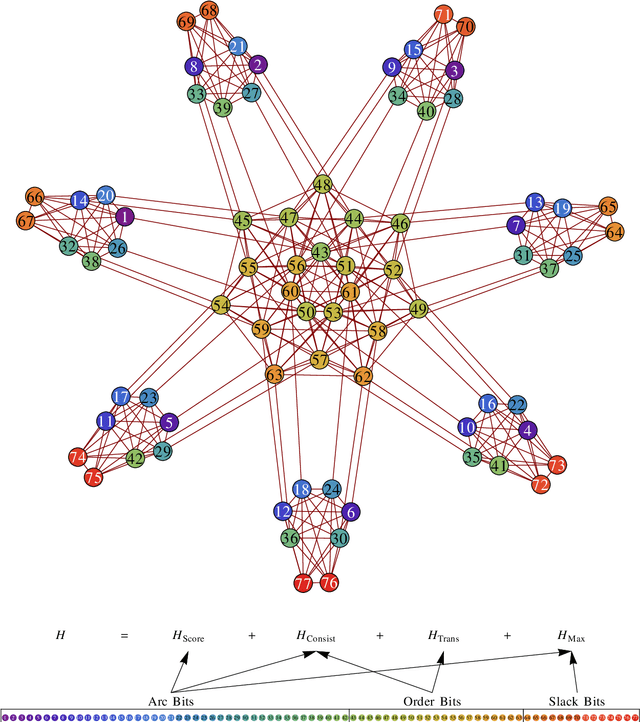
We introduce a method for the problem of learning the structure of a Bayesian network using the quantum adiabatic algorithm. We do so by introducing an efficient reformulation of a standard posterior-probability scoring function on graphs as a pseudo-Boolean function, which is equivalent to a system of 2-body Ising spins, as well as suitable penalty terms for enforcing the constraints necessary for the reformulation; our proposed method requires $\mathcal O(n^2)$ qubits for $n$ Bayesian network variables. Furthermore, we prove lower bounds on the necessary weighting of these penalty terms. The logical structure resulting from the mapping has the appealing property that it is instance-independent for a given number of Bayesian network variables, as well as being independent of the number of data cases.