 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Thin Ice: Towards Explainable Conservation Monitoring via Attribution and Perturbations
Oct 24, 2025Computer vision can accelerate ecological research and conservation monitoring, yet adoption in ecology lags in part because of a lack of trust in black-box neural-network-based models. We seek to address this challenge by applying post-hoc explanations to provide evidence for predictions and document limitations that are important to field deployment. Using aerial imagery from Glacier Bay National Park, we train a Faster R-CNN to detect pinnipeds (harbor seals) and generate explanations via gradient-based class activation mapping (HiResCAM, LayerCAM), local interpretable model-agnostic explanations (LIME), and perturbation-based explanations. We assess explanations along three axes relevant to field use: (i) localization fidelity: whether high-attribution regions coincide with the animal rather than background context; (ii) faithfulness: whether deletion/insertion tests produce changes in detector confidence; and (iii) diagnostic utility: whether explanations reveal systematic failure modes. Explanations concentrate on seal torsos and contours rather than surrounding ice/rock, and removal of the seals reduces detection confidence, providing model-evidence for true positives. The analysis also uncovers recurrent error sources, including confusion between seals and black ice and rocks. We translate these findings into actionable next steps for model development, including more targeted data curation and augmentation. By pairing object detection with post-hoc explainability, we can move beyond "black-box" predictions toward auditable, decision-supporting tools for conservation monitoring.
The Term 'Agent' Has Been Diluted Beyond Utility and Requires Redefinition
Aug 07, 2025
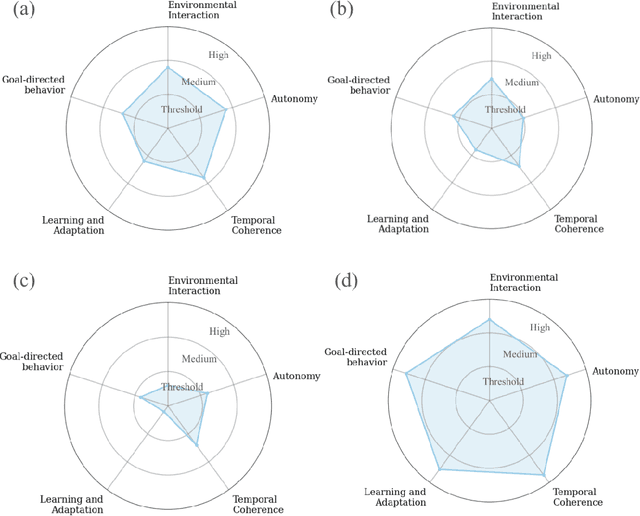
The term 'agent' in artificial intelligence has long carried multiple interpretations across different subfields. Recent developments in AI capabilities, particularly in large language model systems, have amplified this ambiguity, creating significant challenges in research communication, system evaluation and reproducibility, and policy development. This paper argues that the term 'agent' requires redefinition. Drawing from historical analysis and contemporary usage patterns, we propose a framework that defines clear minimum requirements for a system to be considered an agent while characterizing systems along a multidimensional spectrum of environmental interaction, learning and adaptation, autonomy, goal complexity, and temporal coherence. This approach provides precise vocabulary for system description while preserving the term's historically multifaceted nature. After examining potential counterarguments and implementation challenges, we provide specific recommendations for moving forward as a field, including suggestions for terminology standardization and framework adoption. The proposed approach offers practical tools for improving research clarity and reproducibility while supporting more effective policy development.
Semantic Approach to Quantifying the Consistency of Diffusion Model Image Generation
Apr 12, 2024

In this study, we identify the need for an interpretable, quantitative score of the repeatability, or consistency, of image generation in diffusion models. We propose a semantic approach, using a pairwise mean CLIP (Contrastive Language-Image Pretraining) score as our semantic consistency score. We applied this metric to compare two state-of-the-art open-source image generation diffusion models, Stable Diffusion XL and PixArt-{\alpha}, and we found statistically significant differences between the semantic consistency scores for the models. Agreement between the Semantic Consistency Score selected model and aggregated human annotations was 94%. We also explored the consistency of SDXL and a LoRA-fine-tuned version of SDXL and found that the fine-tuned model had significantly higher semantic consistency in generated images. The Semantic Consistency Score proposed here offers a measure of image generation alignment, facilitating the evaluation of model architectures for specific tasks and aiding in informed decision-making regarding model selection.
Releasing the CRaQAn : An open-source dataset and dataset creation methodology using instruction-following models
Nov 27, 2023



Instruction-following language models demand robust methodologies for information retrieval to augment instructions for question-answering applications. A primary challenge is the resolution of coreferences in the context of chunking strategies for long documents. The critical barrier to experimentation of handling coreferences is a lack of open source datasets, specifically in question-answering tasks that require coreference resolution. In this work we present our Coreference Resolution in Question-Answering (CRaQAn) dataset, an open-source dataset that caters to the nuanced information retrieval requirements of coreference resolution in question-answering tasks by providing over 250 question-answer pairs containing coreferences. To develop this dataset, we developed a novel approach for creating high-quality datasets using an instruction-following model (GPT-4) and a Recursive Criticism and Improvement Loop.
InfiniteForm: A synthetic, minimal bias dataset for fitness applications
Oct 04, 2021
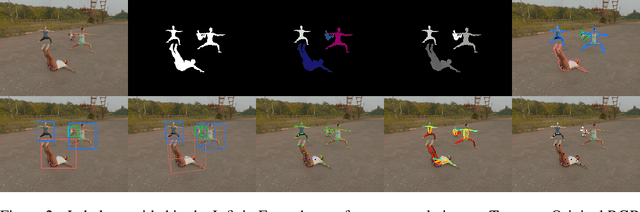
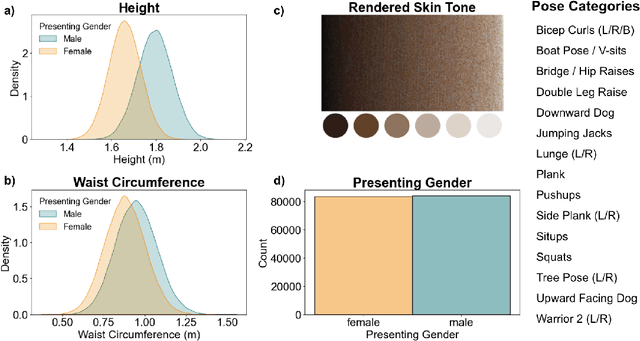
The growing popularity of remote fitness has increased the demand for highly accurate computer vision models that track human poses. However, the best methods still fail in many real-world fitness scenarios, suggesting that there is a domain gap between current datasets and real-world fitness data. To enable the field to address fitness-specific vision problems, we created InfiniteForm, an open-source synthetic dataset of 60k images with diverse fitness poses (15 categories), both single- and multi-person scenes, and realistic variation in lighting, camera angles, and occlusions. As a synthetic dataset, InfiniteForm offers minimal bias in body shape and skin tone, and provides pixel-perfect labels for standard annotations like 2D keypoints, as well as those that are difficult or impossible for humans to produce like depth and occlusion. In addition, we introduce a novel generative procedure for creating diverse synthetic poses from predefined exercise categories. This generative process can be extended to any application where pose diversity is needed to train robust computer vision models.
Low-Rank Nonlinear Decoding of $μ$-ECoG from the Primary Auditory Cortex
May 06, 2020
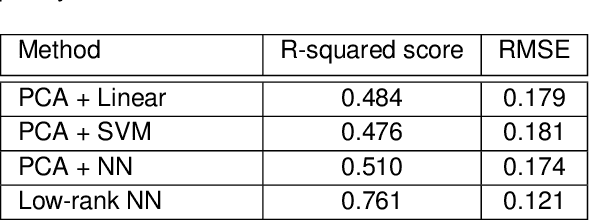

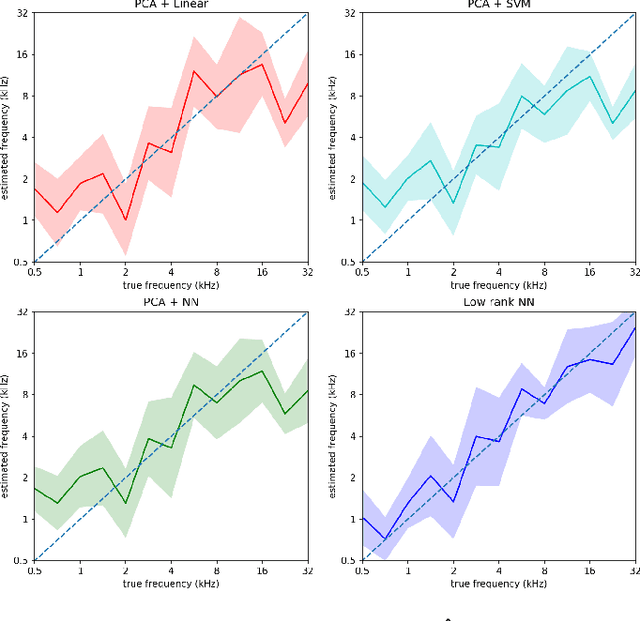
This paper considers the problem of neural decoding from parallel neural measurements systems such as micro-electrocorticography ($\mu$-ECoG). In systems with large numbers of array elements at very high sampling rates, the dimension of the raw measurement data may be large. Learning neural decoders for this high-dimensional data can be challenging, particularly when the number of training samples is limited. To address this challenge, this work presents a novel neural network decoder with a low-rank structure in the first hidden layer. The low-rank constraints dramatically reduce the number of parameters in the decoder while still enabling a rich class of nonlinear decoder maps. The low-rank decoder is illustrated on $\mu$-ECoG data from the primary auditory cortex (A1) of awake rats. This decoding problem is particularly challenging due to the complexity of neural responses in the auditory cortex and the presence of confounding signals in awake animals. It is shown that the proposed low-rank decoder significantly outperforms models using standard dimensionality reduction techniques such as principal component analysis (PCA).