 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking the Dynamic Time Warping Distance Warping-Invariant
Mar 08, 2019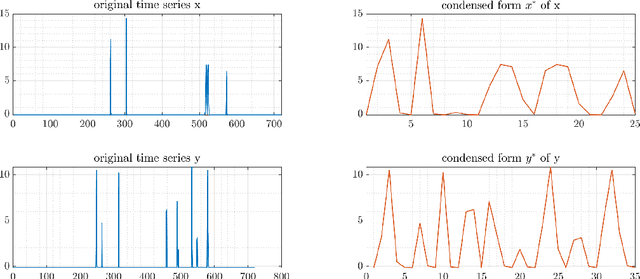


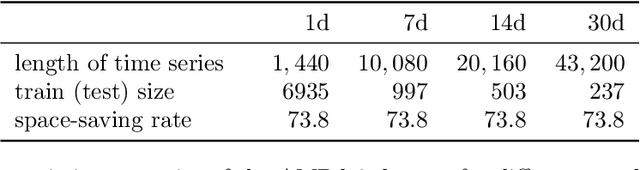
The literature postulates that the dynamic time warping (dtw) distance can cope with temporal variations but stores and processes time series in a form as if the dtw-distance cannot cope with such variations. To address this inconsistency, we first show that the dtw-distance is not warping-invariant. The lack of warping-invariance contributes to the inconsistency mentioned above and to a strange behavior. To eliminate these peculiarities, we convert the dtw-distance to a warping-invariant semi-metric, called time-warp-invariant (twi) distance. Empirical results suggest that the error rates of the twi and dtw nearest-neighbor classifier are practically equivalent in a Bayesian sense. However, the twi-distance requires less storage and computation time than the dtw-distance for a broad range of problems. These results challenge the current practice of applying the dtw-distance in nearest-neighbor classification and suggest the proposed twi-distance as a more efficient and consistent option.
Comparing Temporal Graphs Using Dynamic Time Warping
Oct 15, 2018



The connections within many real-world networks change over time. Thus, there has been a recent boom in studying temporal graphs. Recognizing patterns in temporal graphs requires a similarity measure to compare different temporal graphs. To this end, we initiate the study of dynamic time warping (an established concept for mining time series data) on temporal graphs. We propose the dynamic temporal graph warping distance (dtgw) to determine the (dis-)similarity of two temporal graphs. Our novel measure is flexible and can be applied in various application domains. We show that computing the dtgw-distance is a challenging (NP-hard) optimization problem and identify some polynomial-time solvable special cases. Moreover, we develop a quadratic programming formulation and an efficient heuristic. Preliminary experiments indicate that the heuristic performs very well and that our concept yields meaningful results on real-world instances.
Revisiting Inaccuracies of Time Series Averaging under Dynamic Time Warping
Sep 07, 2018



This article revisits an analysis on inaccuracies of time series averaging under dynamic time warping conducted by \cite{Niennattrakul2007}. The authors presented a correctness-criterion and introduced drift-outs of averages from clusters. They claimed that averages are inaccurate if they are incorrect or drift-outs. Furthermore, they conjectured that such inaccuracies are caused by the lack of triangle inequality. We show that a rectified version of the correctness-criterion is unsatisfiable and that the concept of drift-out is geometrically and operationally inconclusive. Satisfying the triangle inequality is insufficient to achieve correctness and unnecessary to overcome the drift-out phenomenon. We place the concept of drift-out on a principled basis and show that sample means as global minimizers of a Fr\'echet function never drift out. The adjusted drift-out is a way to test to which extent an approximation is coherent. Empirical results show that solutions obtained by the state-of-the-art methods SSG and DBA are incoherent approximations of a sample mean in over a third of all trials.
Exact Mean Computation in Dynamic Time Warping Spaces
May 31, 2018



Dynamic time warping constitutes a major tool for analyzing time series. In particular, computing a mean series of a given sample of series in dynamic time warping spaces (by minimizing the Fr\'echet function) is a challenging computational problem, so far solved by several heuristic and inexact strategies. We spot some inaccuracies in the literature on exact mean computation in dynamic time warping spaces. Our contributions comprise an exact dynamic program computing a mean (useful for benchmarking and evaluating known heuristics). Based on this dynamic program, we empirically study properties like uniqueness and length of a mean. Moreover, experimental evaluations reveal substantial deficits of state-of-the-art heuristics in terms of their output quality. We also give an exact polynomial-time algorithm for the special case of binary time series.
Asymmetric Learning Vector Quantization for Efficient Nearest Neighbor Classification in Dynamic Time Warping Spaces
Mar 24, 2017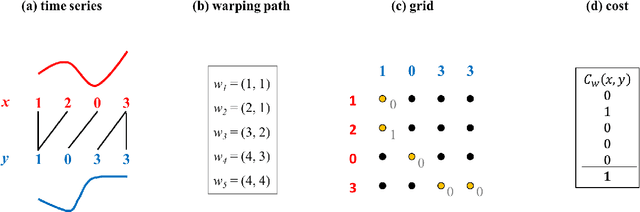
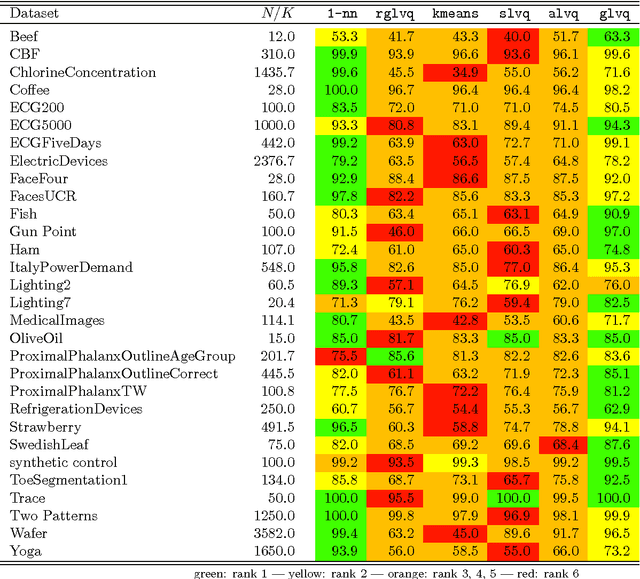

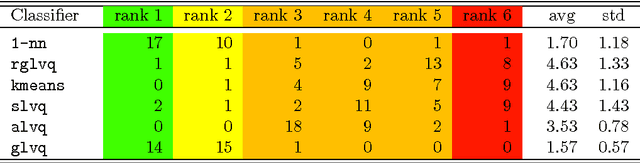
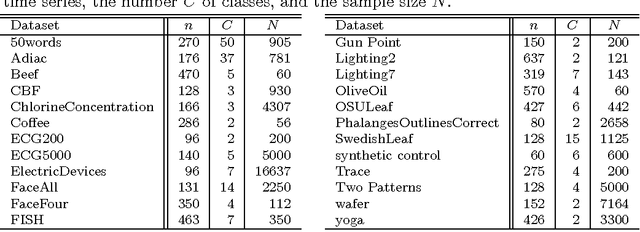
The nearest neighbor method together with the dynamic time warping (DTW) distance is one of the most popular approaches in time series classification. This method suffers from high storage and computation requirements for large training sets. As a solution to both drawbacks, this article extends learning vector quantization (LVQ) from Euclidean spaces to DTW spaces. The proposed LVQ scheme uses asymmetric weighted averaging as update rule. Empirical results exhibited superior performance of asymmetric generalized LVQ (GLVQ) over other state-of-the-art prototype generation methods for nearest neighbor classification.
Nonsmooth Analysis and Subgradient Methods for Averaging in Dynamic Time Warping Spaces
Jan 23, 2017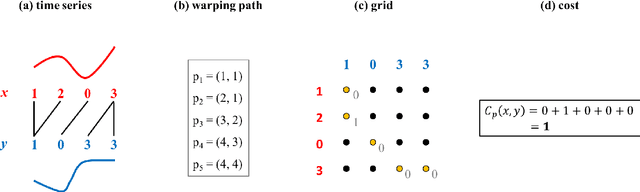

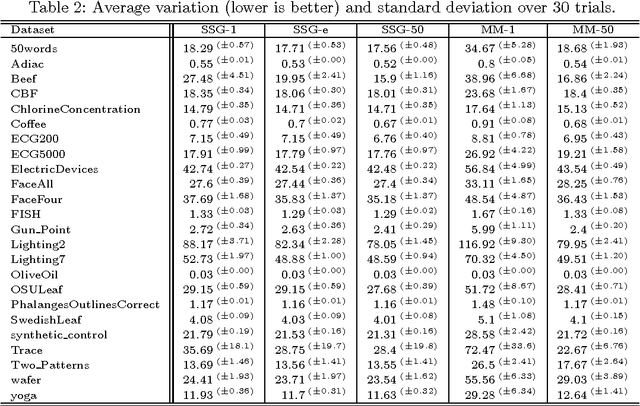
Time series averaging in dynamic time warping (DTW) spaces has been successfully applied to improve pattern recognition systems. This article proposes and analyzes subgradient methods for the problem of finding a sample mean in DTW spaces. The class of subgradient methods generalizes existing sample mean algorithms such as DTW Barycenter Averaging (DBA). We show that DBA is a majorize-minimize algorithm that converges to necessary conditions of optimality after finitely many iterations. Empirical results show that for increasing sample sizes the proposed stochastic subgradient (SSG) algorithm is more stable and finds better solutions in shorter time than the DBA algorithm on average. Therefore, SSG is useful in online settings and for non-small sample sizes. The theoretical and empirical results open new paths for devising sample mean algorithms: nonsmooth optimization methods and modified variants of pairwise averaging methods.
Asymptotic Behavior of Mean Partitions in Consensus Clustering
Dec 18, 2015Although consistency is a minimum requirement of any estimator, little is known about consistency of the mean partition approach in consensus clustering. This contribution studies the asymptotic behavior of mean partitions. We show that under normal assumptions, the mean partition approach is consistent and asymptotic normal. To derive both results, we represent partitions as points of some geometric space, called orbit space. Then we draw on results from the theory of Fr\'echet means and stochastic programming. The asymptotic properties hold for continuous extensions of standard cluster criteria (indices). The results justify consensus clustering using finite but sufficiently large sample sizes. Furthermore, the orbit space framework provides a mathematical foundation for studying further statistical, geometrical, and analytical properties of sets of partitions.
Generalized Gradient Learning on Time Series under Elastic Transformations
Jun 09, 2015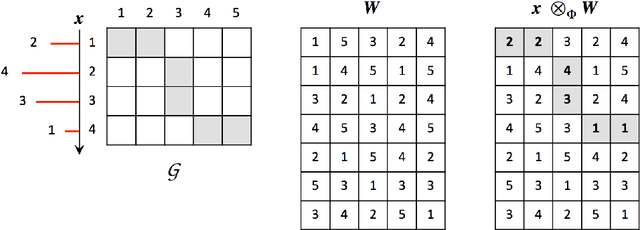

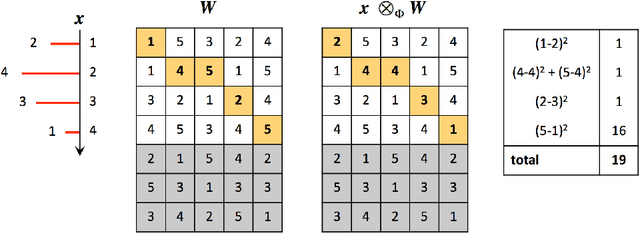

The majority of machine learning algorithms assumes that objects are represented as vectors. But often the objects we want to learn on are more naturally represented by other data structures such as sequences and time series. For these representations many standard learning algorithms are unavailable. We generalize gradient-based learning algorithms to time series under dynamic time warping. To this end, we introduce elastic functions, which extend functions on time series to matrix spaces. Necessary conditions are presented under which generalized gradient learning on time series is consistent. We indicate how results carry over to arbitrary elastic distance functions and to sequences consisting of symbolic elements. Specifically, four linear classifiers are extended to time series under dynamic time warping and applied to benchmark datasets. Results indicate that generalized gradient learning via elastic functions have the potential to complement the state-of-the-art in statistical pattern recognition on time series.
Flip-Flop Sublinear Models for Graphs: Proof of Theorem 1
May 30, 2014We prove that there is no class-dual for almost all sublinear models on graphs.
Extending Bron Kerbosch for Solving the Maximum Weight Clique Problem
Jan 06, 2011

This contribution extends the Bron Kerbosch algorithm for solving the maximum weight clique problem, where continuous-valued weights are assigned to both, vertices and edges. We applied the proposed algorithm to graph matching problems.