 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrage-Free Implied Volatility Surface Generation with Variational Autoencoders
Aug 13, 2021

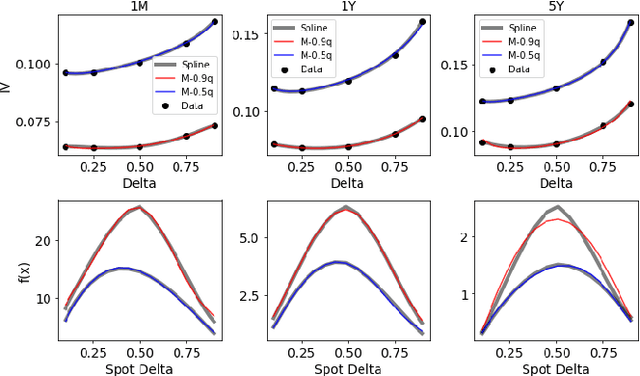

We propose a hybrid method for generating arbitrage-free implied volatility (IV) surfaces consistent with historical data by combining model-free Variational Autoencoders (VAEs) with continuous time stochastic differential equation (SDE) driven models. We focus on two classes of SDE models: regime switching models and L\'evy additive processes. By projecting historical surfaces onto the space of SDE model parameters, we obtain a distribution on the parameter subspace faithful to the data on which we then train a VAE. Arbitrage-free IV surfaces are then generated by sampling from the posterior distribution on the latent space, decoding to obtain SDE model parameters, and finally mapping those parameters to IV surfaces.
Deep Q-Learning for Nash Equilibria: Nash-DQN
Apr 23, 2019

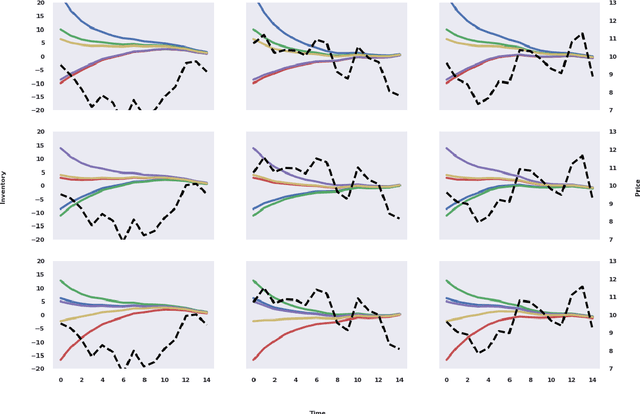

Model-free learning for multi-agent stochastic games is an active area of research. Existing reinforcement learning algorithms, however, are often restricted to zero-sum games, and are applicable only in small state-action spaces or other simplified settings. Here, we develop a new data efficient Deep-Q-learning methodology for model-free learning of Nash equilibria for general-sum stochastic games. The algorithm uses a local linear-quadratic expansion of the stochastic game, which leads to analytically solvable optimal actions. The expansion is parametrized by deep neural networks to give it sufficient flexibility to learn the environment without the need to experience all state-action pairs. We study symmetry properties of the algorithm stemming from label-invariant stochastic games and as a proof of concept, apply our algorithm to learning optimal trading strategies in competitive electronic markets.
Double Deep Q-Learning for Optimal Execution
Dec 17, 2018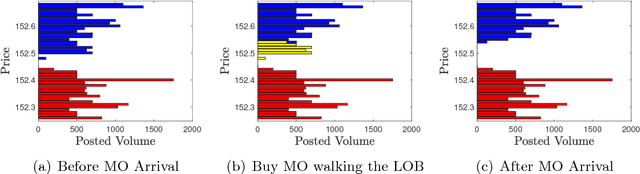
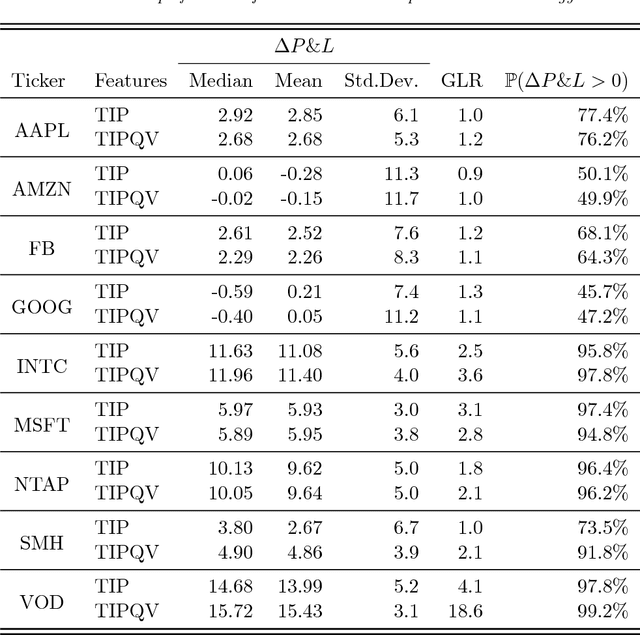
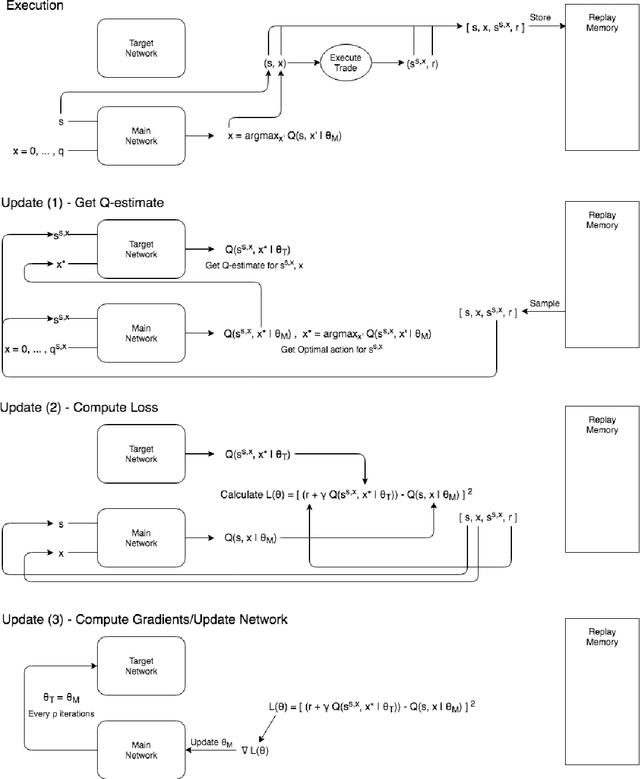

Optimal trade execution is an important problem faced by essentially all traders. Much research into optimal execution uses stringent model assumptions and applies continuous time stochastic control to solve them. Here, we instead take a model free approach and develop a variation of Deep Q-Learning to estimate the optimal actions of a trader. The model is a fully connected Neural Network trained using Experience Replay and Double DQN with input features given by the current state of the limit order book, other trading signals, and available execution actions, while the output is the Q-value function estimating the future rewards under an arbitrary action. We apply our model to nine different stocks and find that it outperforms the standard benchmark approach on most stocks using the measures of (i) mean and median out-performance, (ii) probability of out-performance, and (iii) gain-loss ratios.