 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Optimizers: Regret-optimal gradient descent algorithms
Jan 19, 2021
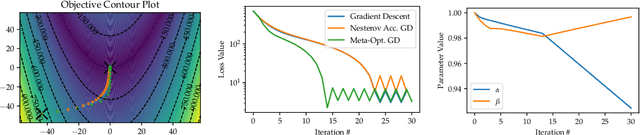
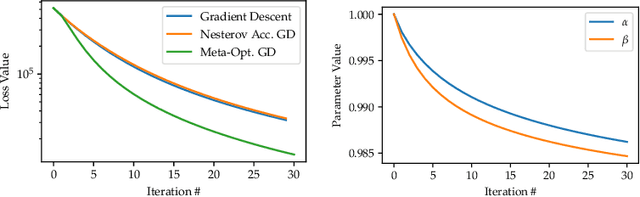
The need for fast and robust optimization algorithms are of critical importance in all areas of machine learning. This paper treats the task of designing optimization algorithms as an optimal control problem. Using regret as a metric for an algorithm's performance, we study the existence, uniqueness and consistency of regret-optimal algorithms. By providing first-order optimality conditions for the control problem, we show that regret-optimal algorithms must satisfy a specific structure in their dynamics which we show is equivalent to performing dual-preconditioned gradient descent on the value function generated by its regret. Using these optimal dynamics, we provide bounds on their rates of convergence to solutions of convex optimization problems. Though closed-form optimal dynamics cannot be obtained in general, we present fast numerical methods for approximating them, generating optimization algorithms which directly optimize their long-term regret. Lastly, these are benchmarked against commonly used optimization algorithms to demonstrate their effectiveness.
A Latent Variational Framework for Stochastic Optimization
May 23, 2019This paper provides a unifying theoretical framework for stochastic optimization algorithms by means of a latent stochastic variational problem. Using techniques from stochastic control, the solution to the variational problem is shown to be equivalent to that of a Forward Backward Stochastic Differential Equation (FBSDE). By solving these equations, we recover a variety of existing adaptive stochastic gradient descent methods. This framework establishes a direct connection between stochastic optimization algorithms and a secondary Bayesian inference problem on gradients, where a prior measure on noisy gradient observations determine the resulting algorithm.
Deep Q-Learning for Nash Equilibria: Nash-DQN
Apr 23, 2019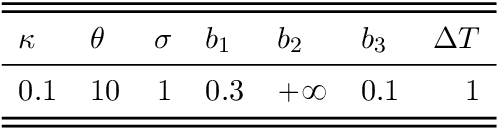

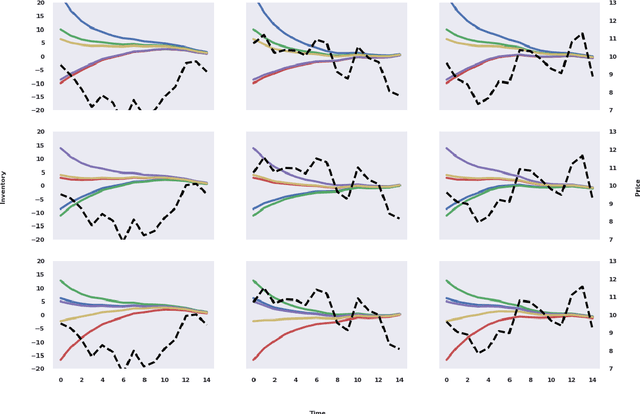

Model-free learning for multi-agent stochastic games is an active area of research. Existing reinforcement learning algorithms, however, are often restricted to zero-sum games, and are applicable only in small state-action spaces or other simplified settings. Here, we develop a new data efficient Deep-Q-learning methodology for model-free learning of Nash equilibria for general-sum stochastic games. The algorithm uses a local linear-quadratic expansion of the stochastic game, which leads to analytically solvable optimal actions. The expansion is parametrized by deep neural networks to give it sufficient flexibility to learn the environment without the need to experience all state-action pairs. We study symmetry properties of the algorithm stemming from label-invariant stochastic games and as a proof of concept, apply our algorithm to learning optimal trading strategies in competitive electronic markets.
Trading algorithms with learning in latent alpha models
Jun 12, 2018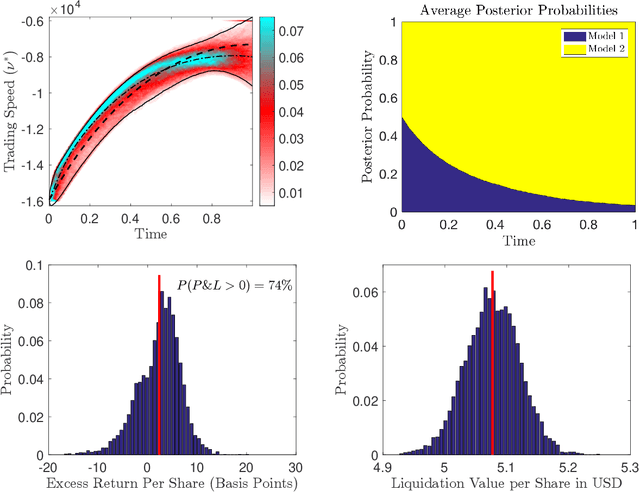

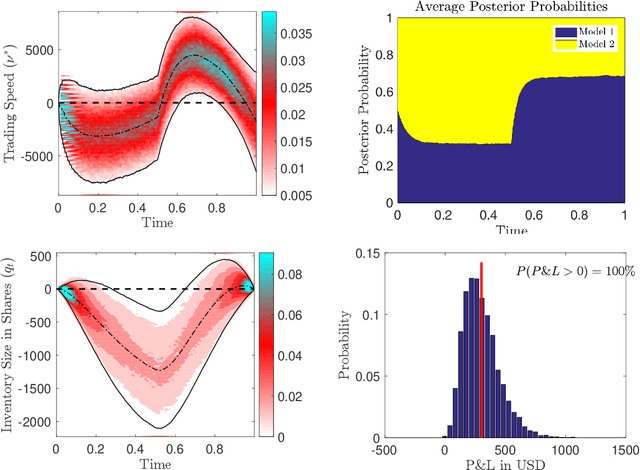

Alpha signals for statistical arbitrage strategies are often driven by latent factors. This paper analyses how to optimally trade with latent factors that cause prices to jump and diffuse. Moreover, we account for the effect of the trader's actions on quoted prices and the prices they receive from trading. Under fairly general assumptions, we demonstrate how the trader can learn the posterior distribution over the latent states, and explicitly solve the latent optimal trading problem. We provide a verification theorem, and a methodology for calibrating the model by deriving a variation of the expectation-maximization algorithm. To illustrate the efficacy of the optimal strategy, we demonstrate its performance through simulations and compare it to strategies which ignore learning in the latent factors. We also provide calibration results for a particular model using Intel Corporation stock as an example.
* 42 pages, 5 figures