 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSITHCon: A neural network robust to variations in input scaling on the time dimension
Jul 09, 2021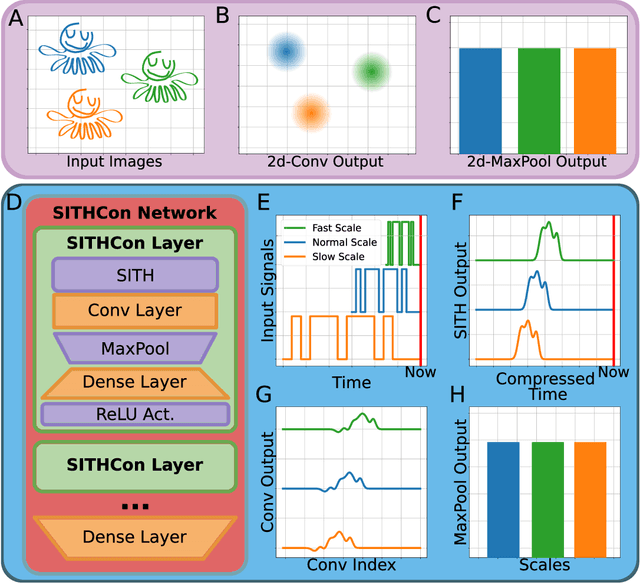

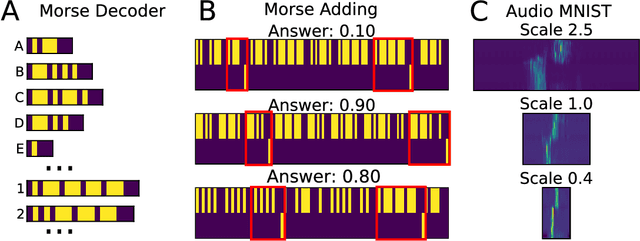
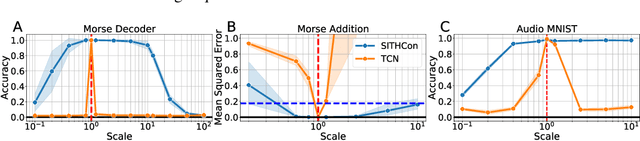
In machine learning, convolutional neural networks (CNNs) have been extremely influential in both computer vision and in recognizing patterns extended over time. In computer vision, part of the flexibility arises from the use of max-pooling operations over the convolutions to attain translation invariance. In the mammalian brain, neural representations of time use a set of temporal basis functions. Critically, these basis functions appear to be arranged in a geometric series such that the basis set is evenly distributed over logarithmic time. This paper introduces a Scale-Invariant Temporal History Convolution network (SITHCon) that uses a logarithmically-distributed temporal memory. A max-pool over a logarithmically-distributed temporal memory results in scale-invariance in time. We compare performance of SITHCon to a Temporal Convolution Network (TCN) and demonstrate that, although both networks can learn classification and regression problems on both univariate and multivariate time series $f(t)$, only SITHCon has the property that it generalizes without retraining to rescaled versions of the input $f(at)$. This property, inspired by findings from neuroscience and psychology, could lead to large-scale networks with dramatically different capabilities, including faster training and greater generalizability, even with significantly fewer free parameters.
Scale-invariant temporal history (SITH): optimal slicing of the past in an uncertain world
Aug 11, 2018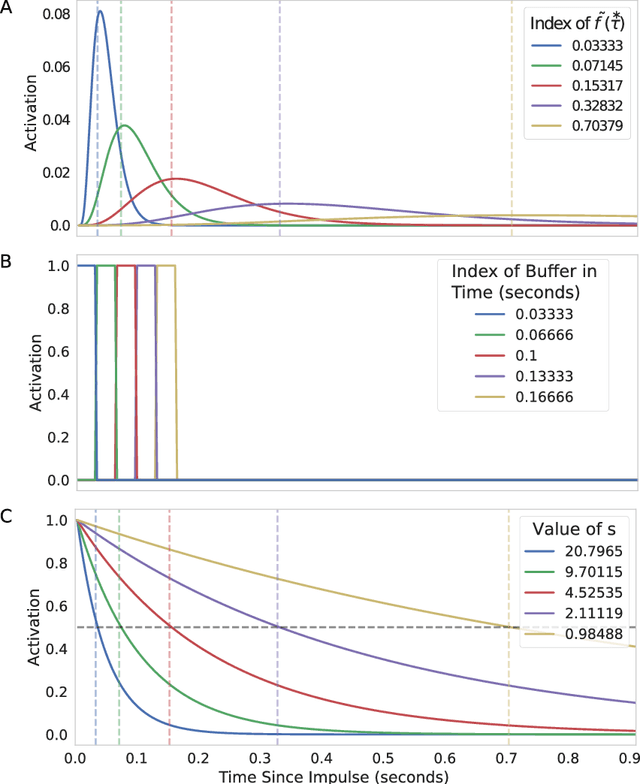
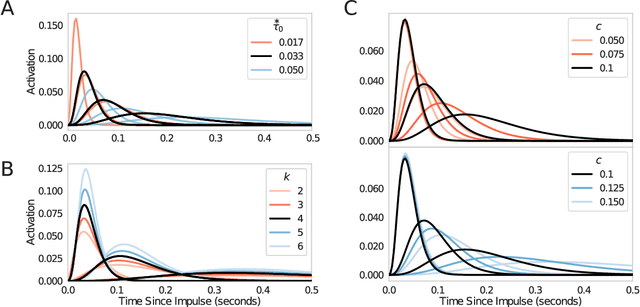
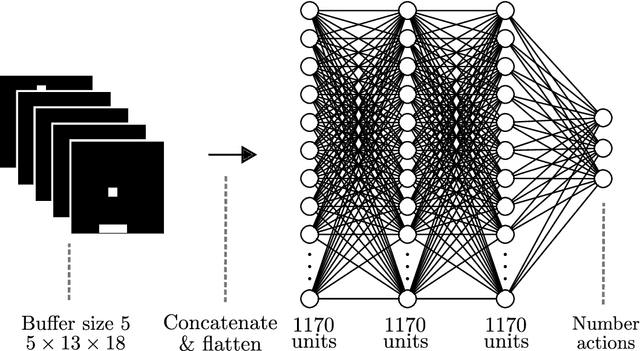

In both the human brain and any general artificial intelligence (AI), a representation of the past is necessary to predict the future. However, perfect storage of all experiences is not feasible. One possibility, utilized in many applications, is to retain information about the past in a buffer. A limitation of this approach is that, although events in the buffer are represented with perfect accuracy, the resources necessary to represent information at multiple time scales go up rapidly. Here we present a neurally-plausible, compressed, scale-free memory representation we call Scale-Invariant Temporal History (SITH). This representation covers an exponentially large period of time at the cost of sacrificing temporal accuracy for events further in the past. The form of this decay is scale-invariant and can be shown to be optimal, in that it is able to respond to worlds with a wide range of relevant time scales. We demonstrate the utility of this representation in learning to play video games at different levels of complexity. In these environments, SITH exhibits better learning performance than both a fixed-size buffer history representation and a representation with exponentially decaying features. Whereas the buffer performs well as long as the temporal dependencies can be represented within the buffer, SITH performs well over a much larger range of time scales with the same amount of resources. Finally, we discuss how the application of SITH, along with other human-inspired models of cognition, could improve reinforcement and machine learning algorithms in general.