 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining how your AI system is fair
May 03, 2021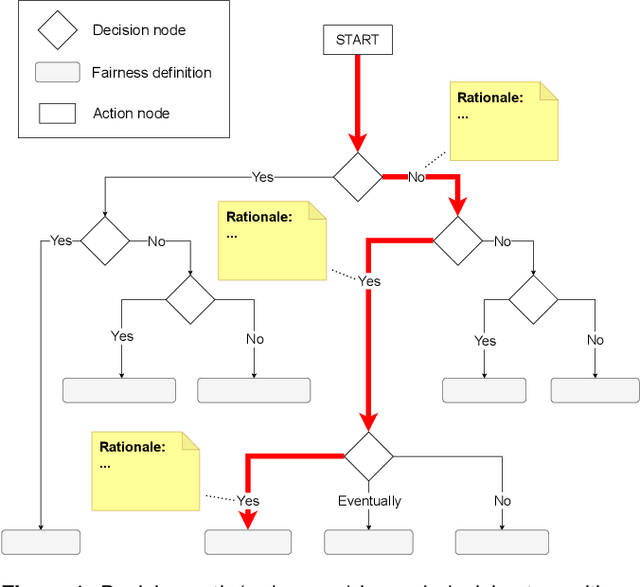
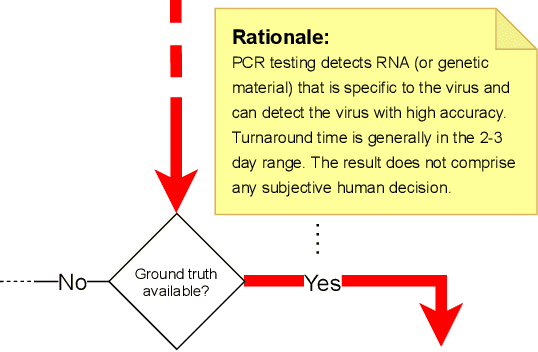
To implement fair machine learning in a sustainable way, choosing the right fairness objective is key. Since fairness is a concept of justice which comes in various, sometimes conflicting definitions, this is not a trivial task though. The most appropriate fairness definition for an artificial intelligence (AI) system is a matter of ethical standards and legal requirements, and the right choice depends on the particular use case and its context. In this position paper, we propose to use a decision tree as means to explain and justify the implemented kind of fairness to the end users. Such a structure would first of all support AI practitioners in mapping ethical principles to fairness definitions for a concrete application and therefore make the selection a straightforward and transparent process. However, this approach would also help document the reasoning behind the decision making. Due to the general complexity of the topic of fairness in AI, we argue that specifying "fairness" for a given use case is the best way forward to maintain confidence in AI systems. In this case, this could be achieved by sharing the reasons and principles expressed during the decision making process with the broader audience.
Implementing Fair Regression In The Real World
Apr 09, 2021



Most fair regression algorithms mitigate bias towards sensitive sub populations and therefore improve fairness at group level. In this paper, we investigate the impact of such implementation of fair regression on the individual. More precisely, we assess the evolution of continuous predictions from an unconstrained to a fair algorithm by comparing results from baseline algorithms with fair regression algorithms for the same data points. Based on our findings, we propose a set of post-processing algorithms to improve the utility of the existing fair regression approaches.
Towards the Right Kind of Fairness in AI
Mar 16, 2021

Fairness is a concept of justice. Various definitions exist, some of them conflicting with each other. In the absence of an uniformly accepted notion of fairness, choosing the right kind for a specific situation has always been a central issue in human history. When it comes to implementing sustainable fairness in artificial intelligence systems, this old question plays a key role once again: How to identify the most appropriate fairness metric for a particular application? The answer is often a matter of context, and the best choice depends on ethical standards and legal requirements. Since ethics guidelines on this topic are kept rather general for now, we aim to provide more hands-on guidance with this document. Therefore, we first structure the complex landscape of existing fairness metrics and explain the different options by example. Furthermore, we propose the "Fairness Compass", a tool which formalises the selection process and makes identifying the most appropriate fairness definition for a given system a simple, straightforward procedure. Because this process also allows to document the reasoning behind the respective decisions, we argue that this approach can help to build trust from the user through explaining and justifying the implemented fairness.
Active Fairness Instead of Unawareness
Sep 14, 2020The possible risk that AI systems could promote discrimination by reproducing and enforcing unwanted bias in data has been broadly discussed in research and society. Many current legal standards demand to remove sensitive attributes from data in order to achieve "fairness through unawareness". We argue that this approach is obsolete in the era of big data where large datasets with highly correlated attributes are common. In the contrary, we propose the active use of sensitive attributes with the purpose of observing and controlling any kind of discrimination, and thus leading to fair results.
Getting Fairness Right: Towards a Toolbox for Practitioners
Mar 15, 2020The potential risk of AI systems unintentionally embedding and reproducing bias has attracted the attention of machine learning practitioners and society at large. As policy makers are willing to set the standards of algorithms and AI techniques, the issue on how to refine existing regulation, in order to enforce that decisions made by automated systems are fair and non-discriminatory, is again critical. Meanwhile, researchers have demonstrated that the various existing metrics for fairness are statistically mutually exclusive and the right choice mostly depends on the use case and the definition of fairness. Recognizing that the solutions for implementing fair AI are not purely mathematical but require the commitments of the stakeholders to define the desired nature of fairness, this paper proposes to draft a toolbox which helps practitioners to ensure fair AI practices. Based on the nature of the application and the available training data, but also on legal requirements and ethical, philosophical and cultural dimensions, the toolbox aims to identify the most appropriate fairness objective. This approach attempts to structure the complex landscape of fairness metrics and, therefore, makes the different available options more accessible to non-technical people. In the proven absence of a silver bullet solution for fair AI, this toolbox intends to produce the fairest AI systems possible with respect to their local context.
Fair Adversarial Gradient Tree Boosting
Nov 18, 2019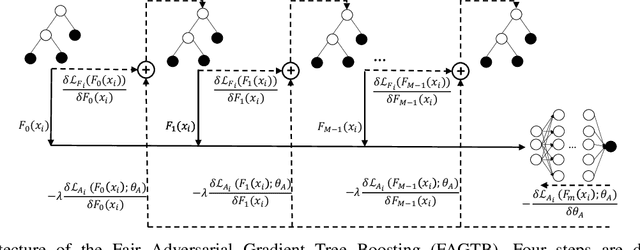

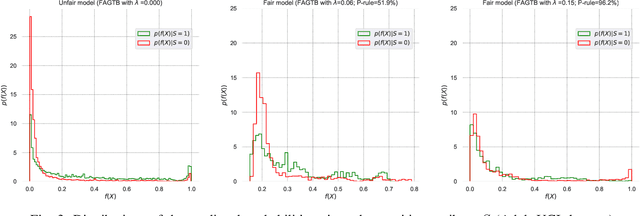

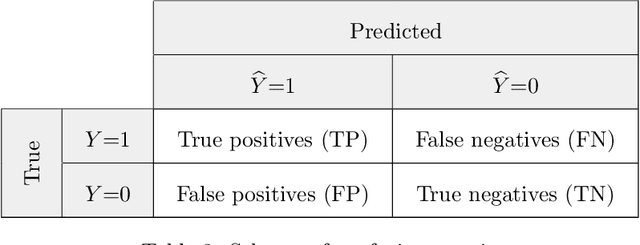
Fair classification has become an important topic in machine learning research. While most bias mitigation strategies focus on neural networks, we noticed a lack of work on fair classifiers based on decision trees even though they have proven very efficient. In an up-to-date comparison of state-of-the-art classification algorithms in tabular data, tree boosting outperforms deep learning. For this reason, we have developed a novel approach of adversarial gradient tree boosting. The objective of the algorithm is to predict the output $Y$ with gradient tree boosting while minimizing the ability of an adversarial neural network to predict the sensitive attribute $S$. The approach incorporates at each iteration the gradient of the neural network directly in the gradient tree boosting. We empirically assess our approach on 4 popular data sets and compare against state-of-the-art algorithms. The results show that our algorithm achieves a higher accuracy while obtaining the same level of fairness, as measured using a set of different common fairness definitions.
Fairness-Aware Neural Réyni Minimization for Continuous Features
Nov 12, 2019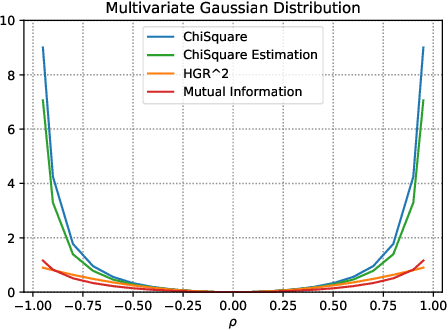

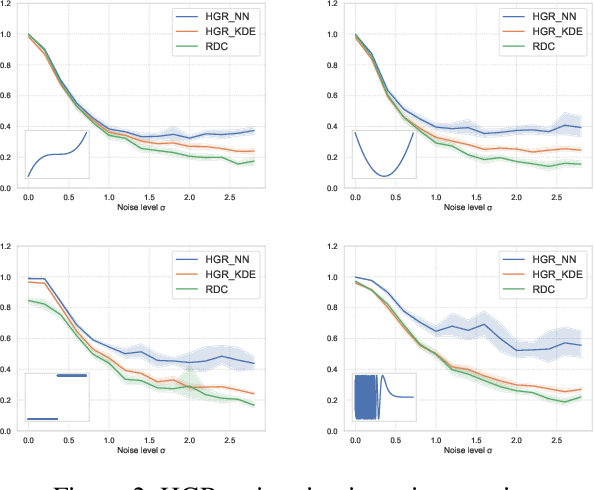
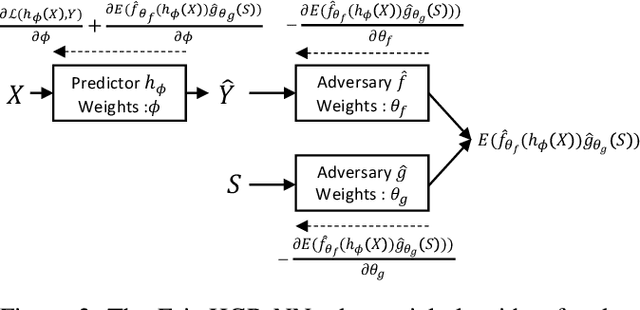
The past few years have seen a dramatic rise of academic and societal interest in fair machine learning. While plenty of fair algorithms have been proposed recently to tackle this challenge for discrete variables, only a few ideas exist for continuous ones. The objective in this paper is to ensure some independence level between the outputs of regression models and any given continuous sensitive variables. For this purpose, we use the Hirschfeld-Gebelein-R\'enyi (HGR) maximal correlation coefficient as a fairness metric. We propose two approaches to minimize the HGR coefficient. First, by reducing an upper bound of the HGR with a neural network estimation of the $\chi^{2}$ divergence. Second, by minimizing the HGR directly with an adversarial neural network architecture. The idea is to predict the output Y while minimizing the ability of an adversarial neural network to find the estimated transformations which are required to predict the HGR coefficient. We empirically assess and compare our approaches and demonstrate significant improvements on previously presented work in the field.
Contract Statements Knowledge Service for Chatbots
Oct 10, 2019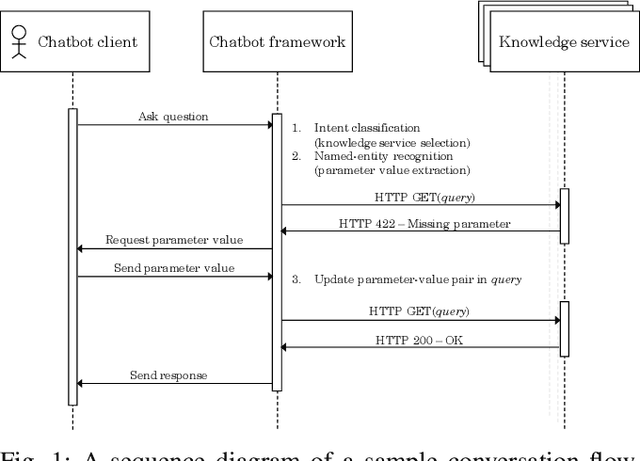


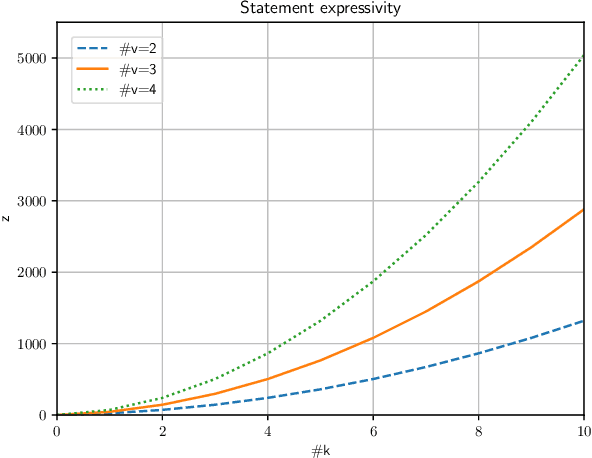
Towards conversational agents that are capable of handling more complex questions on contractual conditions, formalizing contract statements in a machine readable way is crucial. However, constructing a formal model which captures the full scope of a contract proves difficult due to the overall complexity its set of rules represent. Instead, this paper presents a top-down approach to the problem. After identifying the most relevant contract statements, we model their underlying rules in a novel knowledge engineering method. A user-friendly tool we developed for this purpose allows to do so easily and at scale. Then, we expose the statements as service so they can get smoothly integrated in any chatbot framework.