 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory III: Dynamics and Generalization in Deep Networks - a simple solution
Apr 11, 2019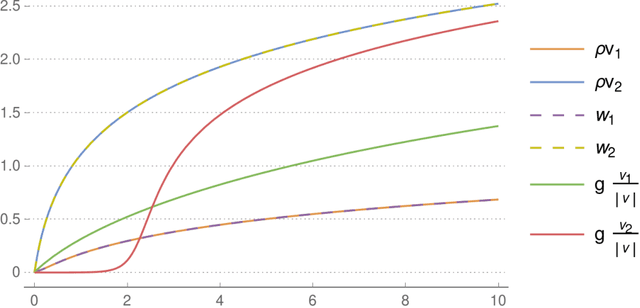
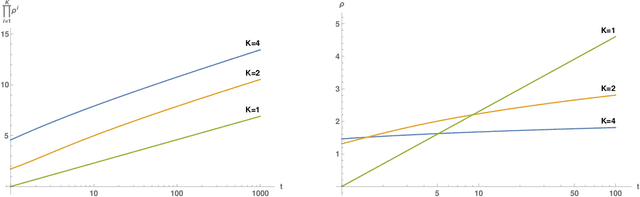


We review recent observations on the dynamical systems induced by gradient descent (GD) methods used for training deep networks and summarize properties of the solutions they converge to. Recent results illuminate the absence of overfitting in the special case of linear networks for binary classification. They prove that minimization of loss functions such as the logistic, the cross-entropy and the exponential loss yields asymptotic convergence to the maximum margin solution for linearly separable datasets, independently of the initial conditions. Here we discuss the case of nonlinear DNNs near zero minima of the empirical loss, under exponential-type and square losses, for several variations of the basic GD algorithm, including a new NMGD version that converges to the minimum norm fixed points. Our main results are: 1) GD algorithms with weight normalization constraint achieve generalization; 2) the fundamental reason for the effectiveness of existing weight and batch normalization techniques is that they are approximate implementations of maximizing the margin under unit norm constraint; 3) even without explicit unit norm constraints, generalization can still be obtained for not-too-deep networks because standard GD is intrinsically consistent with the dynamics of normalized weights. In addition, the balance of the weights across different layers, if present at initialization, is maintained by the gradient flow. In the perspective of these theoretical results, we discuss experimental evidence around the apparent absence of overfitting, that is the observation that the expected classification error does not get worse when increasing the number of parameters. Our explanation focuses on the implicit normalization enforced by algorithms such as batch normalization. In particular, the control of the norm of the weights is related to Halpern iterations for minimum norm solutions.