 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Daily High-resolution Inundation Observations using Deep Learning and EO
Aug 10, 2022

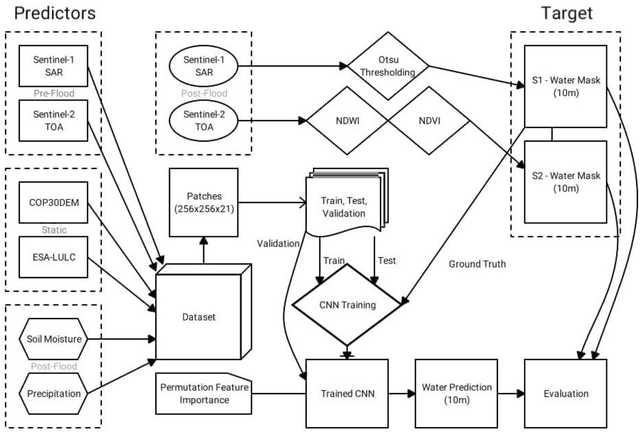
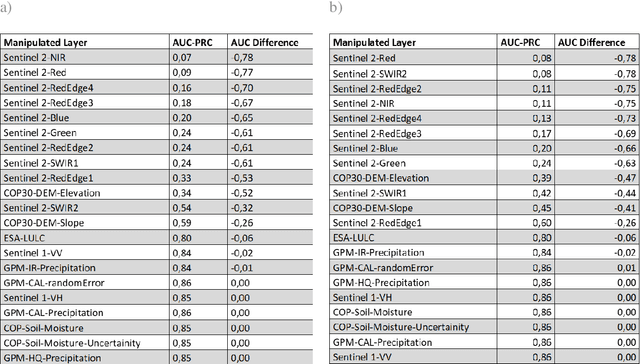
Satellite remote sensing presents a cost-effective solution for synoptic flood monitoring, and satellite-derived flood maps provide a computationally efficient alternative to numerical flood inundation models traditionally used. While satellites do offer timely inundation information when they happen to cover an ongoing flood event, they are limited by their spatiotemporal resolution in terms of their ability to dynamically monitor flood evolution at various scales. Constantly improving access to new satellite data sources as well as big data processing capabilities has unlocked an unprecedented number of possibilities in terms of data-driven solutions to this problem. Specifically, the fusion of data from satellites, such as the Copernicus Sentinels, which have high spatial and low temporal resolution, with data from NASA SMAP and GPM missions, which have low spatial but high temporal resolutions could yield high-resolution flood inundation at a daily scale. Here a Convolutional-Neural-Network is trained using flood inundation maps derived from Sentinel-1 Synthetic Aperture Radar and various hydrological, topographical, and land-use based predictors for the first time, to predict high-resolution probabilistic maps of flood inundation. The performance of UNet and SegNet model architectures for this task is evaluated, using flood masks derived from Sentinel-1 and Sentinel-2, separately with 95 percent-confidence intervals. The Area under the Curve (AUC) of the Precision Recall Curve (PR-AUC) is used as the main evaluation metric, due to the inherently imbalanced nature of classes in a binary flood mapping problem, with the best model delivering a PR-AUC of 0.85.
Tropical Land Use Land Cover Mapping in Pará using Discriminative Markov Random Fields and Multi-temporal TerraSAR-X Data
Sep 22, 2017
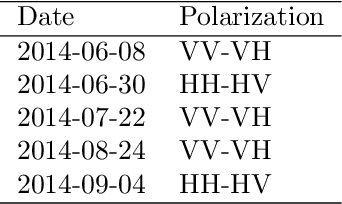

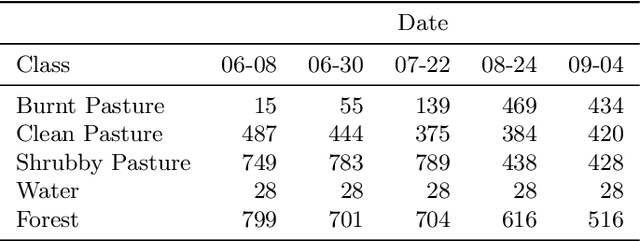
Remote sensing satellite data offer the unique possibility to map land use land cover transformations by providing spatially explicit information. However, detection of short-term processes and land use patterns of high spatial-temporal variability is a challenging task. We present a novel framework using multi-temporal TerraSAR-X data and machine learning techniques, namely Discriminative Markov Random Fields with spatio-temporal priors, and Import Vector Machines, in order to advance the mapping of land cover characterized by short-term changes. Our study region covers a current deforestation frontier in the Brazilian state Par\'{a} with land cover dominated by primary forests, different types of pasture land and secondary vegetation, and land use dominated by short-term processes such as slash-and-burn activities. The data set comprises multi-temporal TerraSAR-X imagery acquired over the course of the 2014 dry season, as well as optical data (RapidEye, Landsat) for reference. Results show that land use land cover is reliably mapped, resulting in spatially adjusted overall accuracies of up to $79\%$ in a five class setting, yet limitations for the differentiation of different pasture types remain. The proposed method is applicable on multi-temporal data sets, and constitutes a feasible approach to map land use land cover in regions that are affected by high-frequent temporal changes.
Shapelet-based Sparse Representation for Landcover Classification of Hyperspectral Images
Aug 20, 2017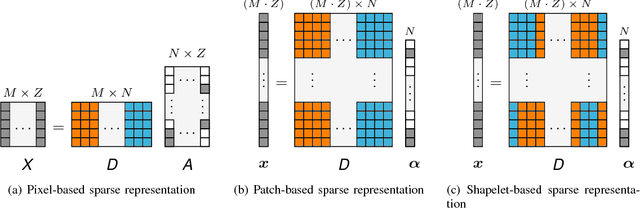
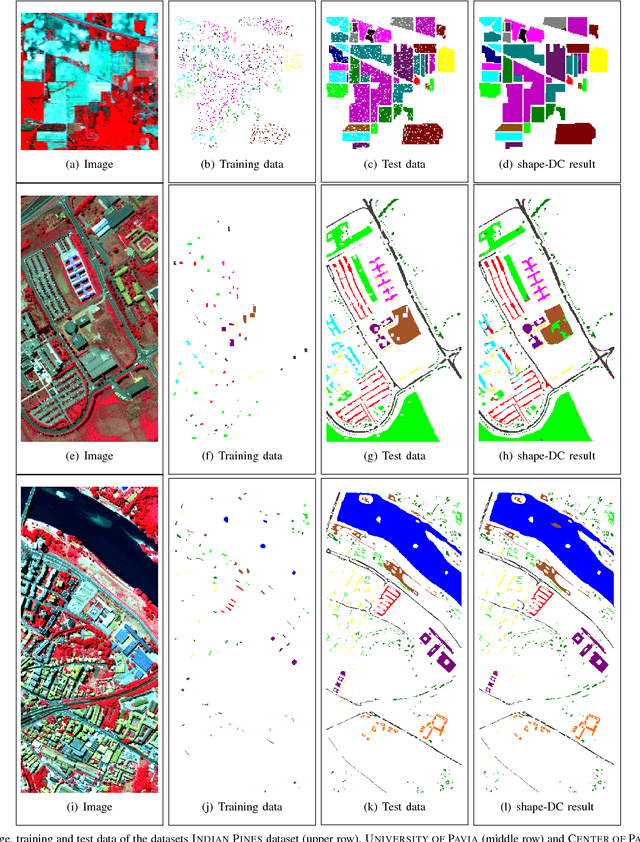
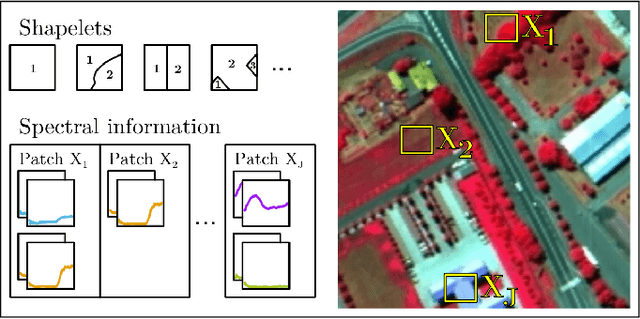
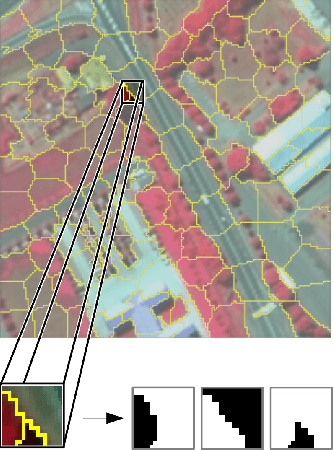
This paper presents a sparse representation-based classification approach with a novel dictionary construction procedure. By using the constructed dictionary sophisticated prior knowledge about the spatial nature of the image can be integrated. The approach is based on the assumption that each image patch can be factorized into characteristic spatial patterns, also called shapelets, and patch-specific spectral information. A set of shapelets is learned in an unsupervised way and spectral information are embodied by training samples. A combination of shapelets and spectral information are represented in an undercomplete spatial-spectral dictionary for each individual patch, where the elements of the dictionary are linearly combined to a sparse representation of the patch. The patch-based classification is obtained by means of the representation error. Experiments are conducted on three well-known hyperspectral image datasets. They illustrate that our proposed approach shows superior results in comparison to sparse representation-based classifiers that use only limited spatial information and behaves competitively with or better than state-of-the-art classifiers utilizing spatial information and kernelized sparse representation-based classifiers.
Incremental Import Vector Machines for Classifying Hyperspectral Data
Aug 20, 2017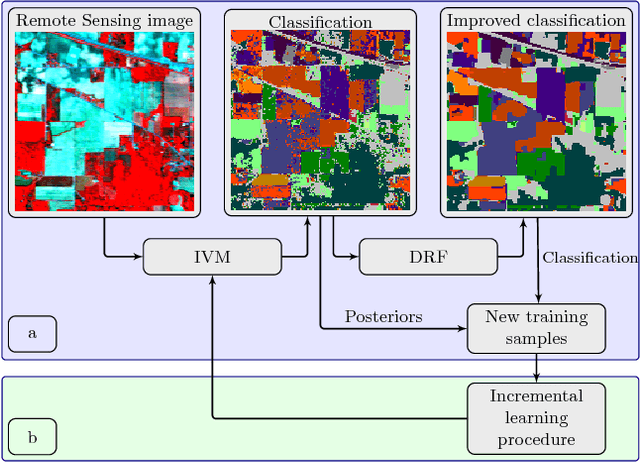
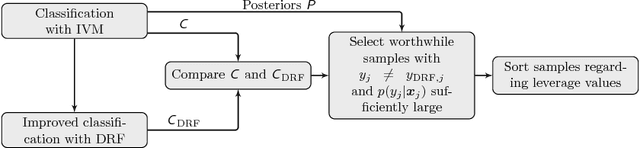


In this paper we propose an incremental learning strategy for import vector machines (IVM), which is a sparse kernel logistic regression approach. We use the procedure for the concept of self-training for sequential classification of hyperspectral data. The strategy comprises the inclusion of new training samples to increase the classification accuracy and the deletion of non-informative samples to be memory- and runtime-efficient. Moreover, we update the parameters in the incremental IVM model without re-training from scratch. Therefore, the incremental classifier is able to deal with large data sets. The performance of the IVM in comparison to support vector machines (SVM) is evaluated in terms of accuracy and experiments are conducted to assess the potential of the probabilistic outputs of the IVM. Experimental results demonstrate that the IVM and SVM perform similar in terms of classification accuracy. However, the number of import vectors is significantly lower when compared to the number of support vectors and thus, the computation time during classification can be decreased. Moreover, the probabilities provided by IVM are more reliable, when compared to the probabilistic information, derived from an SVM's output. In addition, the proposed self-training strategy can increase the classification accuracy. Overall, the IVM and the its incremental version is worthwhile for the classification of hyperspectral data.