 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Import Vector Machines for Classifying Hyperspectral Data
Paper and Code
Aug 20, 2017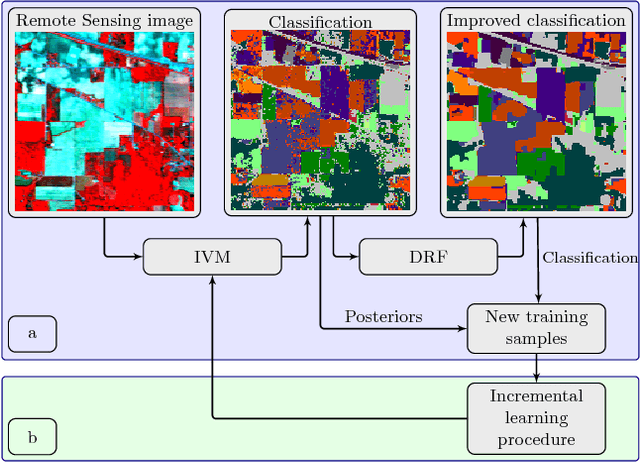
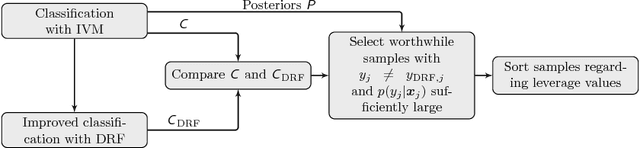


In this paper we propose an incremental learning strategy for import vector machines (IVM), which is a sparse kernel logistic regression approach. We use the procedure for the concept of self-training for sequential classification of hyperspectral data. The strategy comprises the inclusion of new training samples to increase the classification accuracy and the deletion of non-informative samples to be memory- and runtime-efficient. Moreover, we update the parameters in the incremental IVM model without re-training from scratch. Therefore, the incremental classifier is able to deal with large data sets. The performance of the IVM in comparison to support vector machines (SVM) is evaluated in terms of accuracy and experiments are conducted to assess the potential of the probabilistic outputs of the IVM. Experimental results demonstrate that the IVM and SVM perform similar in terms of classification accuracy. However, the number of import vectors is significantly lower when compared to the number of support vectors and thus, the computation time during classification can be decreased. Moreover, the probabilities provided by IVM are more reliable, when compared to the probabilistic information, derived from an SVM's output. In addition, the proposed self-training strategy can increase the classification accuracy. Overall, the IVM and the its incremental version is worthwhile for the classification of hyperspectral data.