 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetal-conscious Embedding for CBCT Projection Inpainting
Nov 29, 2022The existence of metallic implants in projection images for cone-beam computed tomography (CBCT) introduces undesired artifacts which degrade the quality of reconstructed images. In order to reduce metal artifacts, projection inpainting is an essential step in many metal artifact reduction algorithms. In this work, a hybrid network combining the shift window (Swin) vision transformer (ViT) and a convolutional neural network is proposed as a baseline network for the inpainting task. To incorporate metal information for the Swin ViT-based encoder, metal-conscious self-embedding and neighborhood-embedding methods are investigated. Both methods have improved the performance of the baseline network. Furthermore, by choosing appropriate window size, the model with neighborhood-embedding could achieve the lowest mean absolute error of 0.079 in metal regions and the highest peak signal-to-noise ratio of 42.346 in CBCT projections. At the end, the efficiency of metal-conscious embedding on both simulated and real cadaver CBCT data has been demonstrated, where the inpainting capability of the baseline network has been enhanced.
Simulation-Driven Training of Vision Transformers Enabling Metal Segmentation in X-Ray Images
Mar 17, 2022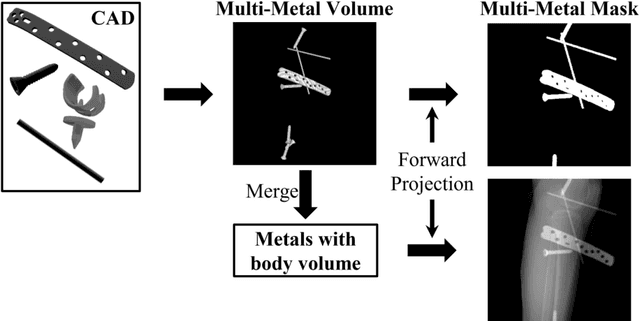
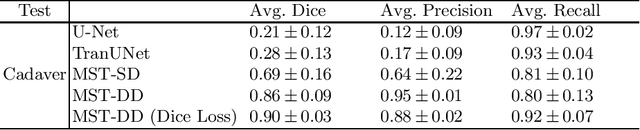
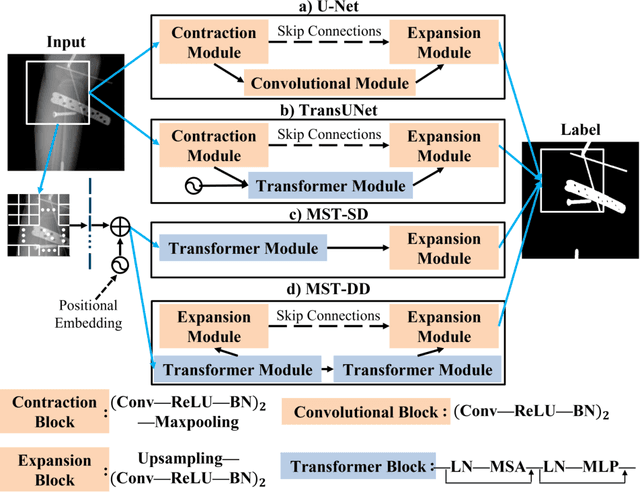
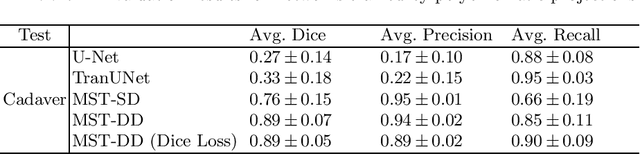
In several image acquisition and processing steps of X-ray radiography, knowledge of the existence of metal implants and their exact position is highly beneficial (e.g. dose regulation, image contrast adjustment). Another application which would benefit from an accurate metal segmentation is cone beam computed tomography (CBCT) which is based on 2D X-ray projections. Due to the high attenuation of metals, severe artifacts occur in the 3D X-ray acquisitions. The metal segmentation in CBCT projections usually serves as a prerequisite for metal artifact avoidance and reduction algorithms. Since the generation of high quality clinical training is a constant challenge, this study proposes to generate simulated X-ray images based on CT data sets combined with self-designed computer aided design (CAD) implants and make use of convolutional neural network (CNN) and vision transformer (ViT) for metal segmentation. Model test is performed on accurately labeled X-ray test datasets obtained from specimen scans. The CNN encoder-based network like U-Net has limited performance on cadaver test data with an average dice score below 0.30, while the metal segmentation transformer with dual decoder (MST-DD) shows high robustness and generalization on the segmentation task, with an average dice score of 0.90. Our study indicates that the CAD model-based data generation has high flexibility and could be a way to overcome the problem of shortage in clinical data sampling and labelling. Furthermore, the MST-DD approach generates a more reliable neural network in case of training on simulated data.
Fiducial marker recovery and detection from severely truncated data in navigation assisted spine surgery
Sep 01, 2021

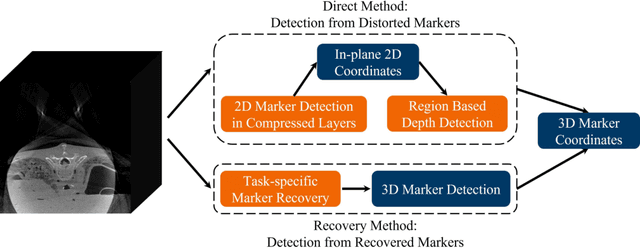

Fiducial markers are commonly used in navigation assisted minimally invasive spine surgery (MISS) and they help transfer image coordinates into real world coordinates. In practice, these markers might be located outside the field-of-view (FOV), due to the limited detector sizes of C-arm cone-beam computed tomography (CBCT) systems used in intraoperative surgeries. As a consequence, reconstructed markers in CBCT volumes suffer from artifacts and have distorted shapes, which sets an obstacle for navigation. In this work, we propose two fiducial marker detection methods: direct detection from distorted markers (direct method) and detection after marker recovery (recovery method). For direct detection from distorted markers in reconstructed volumes, an efficient automatic marker detection method using two neural networks and a conventional circle detection algorithm is proposed. For marker recovery, a task-specific learning strategy is proposed to recover markers from severely truncated data. Afterwards, a conventional marker detection algorithm is applied for position detection. The two methods are evaluated on simulated data and real data, both achieving a marker registration error smaller than 0.2 mm. Our experiments demonstrate that the direct method is capable of detecting distorted markers accurately and the recovery method with task-specific learning has high robustness and generalizability on various data sets. In addition, the task-specific learning is able to reconstruct other structures of interest accurately, e.g. ribs for image-guided needle biopsy, from severely truncated data, which empowers CBCT systems with new potential applications.