 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective comparison of auditory profiles using manifold learning and intrinsic measures
Jan 07, 2026Assigning individuals with hearing impairment to auditory profiles can support a better understanding of the causes and consequences of hearing loss and facilitate profile-based hearing-aid fitting. However, the factors influencing auditory profile generation remain insufficiently understood, and existing profiling frameworks have rarely been compared systematically. This study therefore investigated the impact of two key factors - the clustering method and the number of profiles - on auditory profile generation. In addition, eight established auditory profiling frameworks were systematically reviewed and compared using intrinsic statistical measures and manifold learning techniques. Frameworks were evaluated with respect to internal consistency (i.e., grouping similar individuals) and cluster separation (i.e., clear differentiation between groups). To ensure comparability, all analyses were conducted on a common open-access dataset, the extended Oldenburg Hearing Health Record (OHHR), comprising 1,127 participants (mean age = 67.2 years, SD = 12.0). Results showed that both the clustering method and the chosen number of profiles substantially influenced the resulting auditory profiles. Among purely audiogram-based approaches, the Bisgaard auditory profiles demonstrated the strongest clustering performance, whereas audiometric phenotypes performed worst. Among frameworks incorporating supra-threshold information in addition to the audiogram, the Hearing4All auditory profiles were advantageous, combining a near-optimal number of profile classes (N = 13) with high clustering quality, as indicated by a low Davies-Bouldin index. In conclusion, manifold learning and intrinsic measures enable systematic comparison of auditory profiling frameworks and identify the Hearing4All auditory profile as a promising approach for future research.
Integrating audiological datasets via federated merging of Auditory Profiles
Jul 30, 2024Audiological datasets contain valuable knowledge about hearing loss in patients, which can be uncovered using data-driven, federated learning techniques. Our previous approach summarized patient information from one audiological dataset into distinct Auditory Profiles (APs). To cover the complete audiological patient population, however, patient patterns must be analyzed across multiple, separated datasets, and finally, be integrated into a combined set of APs. This study aimed at extending the existing profile generation pipeline with an AP merging step, enabling the combination of APs from different datasets based on their similarity across audiological measures. The 13 previously generated APs (NA=595) were merged with 31 newly generated APs from a second dataset (NB=1272) using a similarity score derived from the overlapping densities of common features across the two datasets. To ensure clinical applicability, random forest models were created for various scenarios, encompassing different combinations of audiological measures. A new set with 13 combined APs is proposed, providing well-separable profiles, which still capture detailed patient information from various test outcome combinations. The classification performance across these profiles is satisfactory. The best performance was achieved using a combination of loudness scaling, audiogram and speech test information, while single measures performed worst. The enhanced profile generation pipeline demonstrates the feasibility of combining APs across datasets, which should generalize to all datasets and could lead to an interpretable population-based profile set in the future. The classification models maintain clinical applicability. Hence, even if only smartphone-based measures are available, a given patient can be classified into an appropriate AP.
Lombard Effect for Bilingual Speakers in Cantonese and English: importance of spectro-temporal features
Apr 14, 2022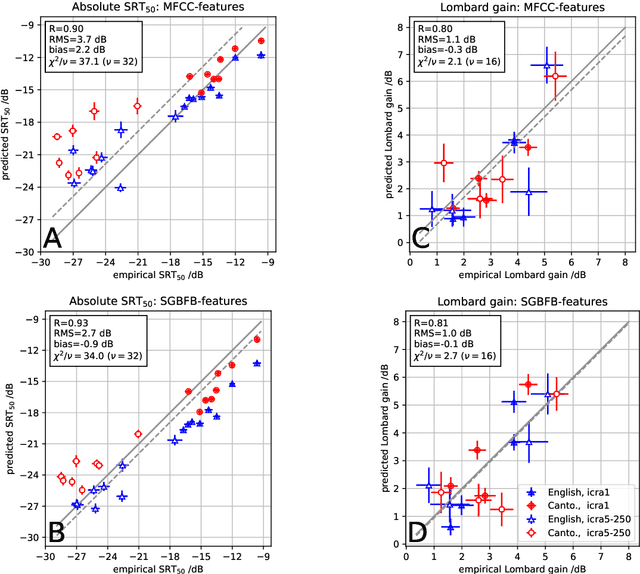
For a better understanding of the mechanisms underlying speech perception and the contribution of different signal features, computational models of speech recognition have a long tradition in hearing research. Due to the diverse range of situations in which speech needs to be recognized, these models need to be generalizable across many acoustic conditions, speakers, and languages. This contribution examines the importance of different features for speech recognition predictions of plain and Lombard speech for English in comparison to Cantonese in stationary and modulated noise. While Cantonese is a tonal language that encodes information in spectro-temporal features, the Lombard effect is known to be associated with spectral changes in the speech signal. These contrasting properties of tonal languages and the Lombard effect form an interesting basis for the assessment of speech recognition models. Here, an automatic speech recognition-based ASR model using spectral or spectro-temporal features is evaluated with empirical data. The results indicate that spectro-temporal features are crucial in order to predict the speaker-specific speech recognition threshold SRT$_{50}$ in both Cantonese and English as well as to account for the improvement of speech recognition in modulated noise, while effects due to Lombard speech can already be predicted by spectral features.
Prediction of speech intelligibility with DNN-based performance measures
Mar 17, 2022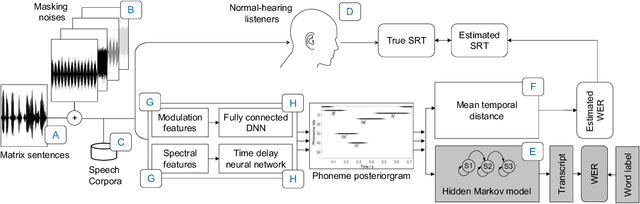


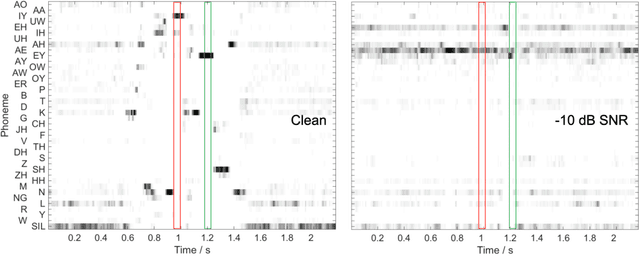
This paper presents a speech intelligibility model based on automatic speech recognition (ASR), combining phoneme probabilities from deep neural networks (DNN) and a performance measure that estimates the word error rate from these probabilities. This model does not require the clean speech reference nor the word labels during testing as the ASR decoding step, which finds the most likely sequence of words given phoneme posterior probabilities, is omitted. The model is evaluated via the root-mean-squared error between the predicted and observed speech reception thresholds from eight normal-hearing listeners. The recognition task consists of identifying noisy words from a German matrix sentence test. The speech material was mixed with eight noise maskers covering different modulation types, from speech-shaped stationary noise to a single-talker masker. The prediction performance is compared to five established models and an ASR-model using word labels. Two combinations of features and networks were tested. Both include temporal information either at the feature level (amplitude modulation filterbanks and a feed-forward network) or captured by the architecture (mel-spectrograms and a time-delay deep neural network, TDNN). The TDNN model is on par with the DNN while reducing the number of parameters by a factor of 37; this optimization allows parallel streams on dedicated hearing aid hardware as a forward-pass can be computed within the 10ms of each frame. The proposed model performs almost as well as the label-based model and produces more accurate predictions than the baseline models.
Individualized sound pressure equalization in hearing devices exploiting an electro-acoustic model
Oct 04, 2021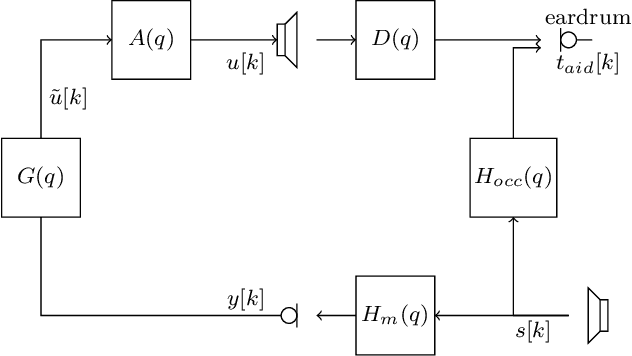
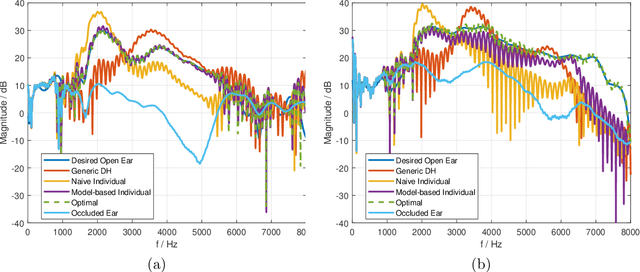
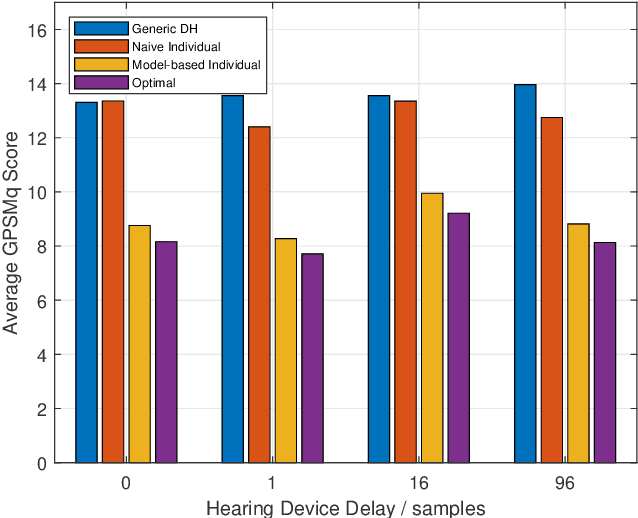
To improve sound quality in hearing devices, the hearing device output should be appropriately equalized. To achieve optimal individualized equalization typically requires knowledge of all transfer functions between the source, the hearing device, and the individual eardrum. However, in practice the measurement of all of these transfer functions is not feasible. This study investigates sound pressure equalization using different transfer function estimates. Specifically, an electro-acoustic model is used to predict the sound pressure at the individual eardrum, and average estimates are used to predict the remaining transfer functions. Experimental results show that using these assumptions a practically feasible and close-to-optimal individualized sound pressure equalization can be achieved.
Robust single- and multi-loudspeaker least-squares-based equalization for hearing devices
Sep 09, 2021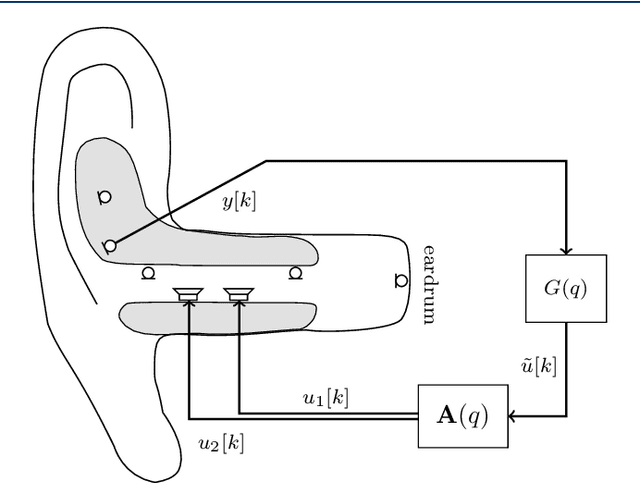
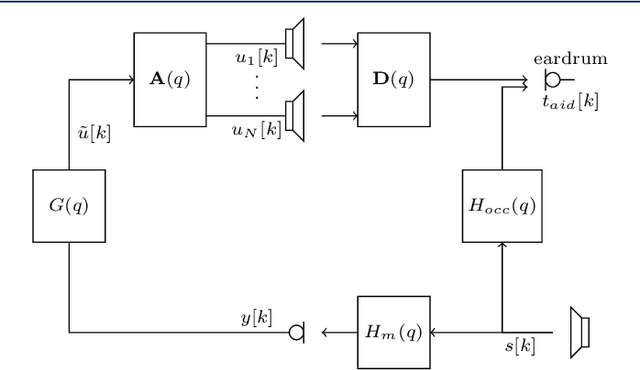
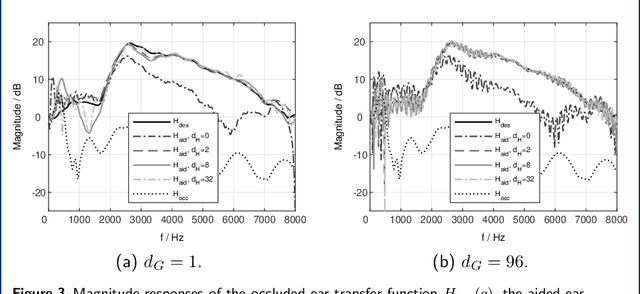
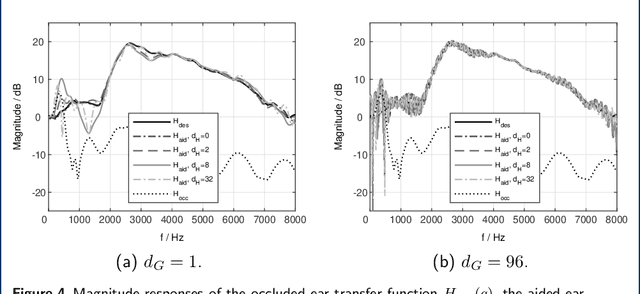
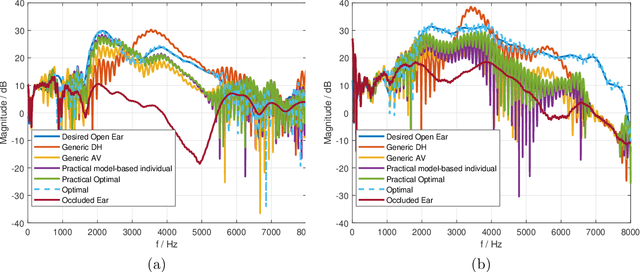
To improve the sound quality of hearing devices, equalization filters can be used that aim at achieving acoustic transparency, i.e., listening with the device in the ear is perceptually similar to the open ear. The equalization filter needs to ensure that the superposition of the equalized signal played by the device and the signal leaking through the device into the ear canal matches a processed version of the signal reaching the eardrum of the open ear. Depending on the processing delay of the hearing device, comb-filtering artifacts can occur due to this superposition, which may degrade the perceived sound quality. In this paper we propose a unified least-squares-based procedure to design single- and multi-loudspeaker equalization filters for hearing devices aiming at achieving acoustic transparency. To account for non-minimum phase components, we introduce a so-called acausality management. To reduce comb-filtering artifacts, we propose to use a frequency-dependent regularization. Experimental results using measured acoustic transfer functions from a multi-loudspeaker earpiece show that the proposed equalization filter design procedure enables to achieve robust acoustic transparency and reduces the impact of comb-filtering artifacts. A comparison between single- and multi-loudspeaker equalization shows that for both cases a robust equalization performance can be achieved for different desired open ear transfer functions.