 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Enhanced Semantic Communication Receiver
Feb 13, 2023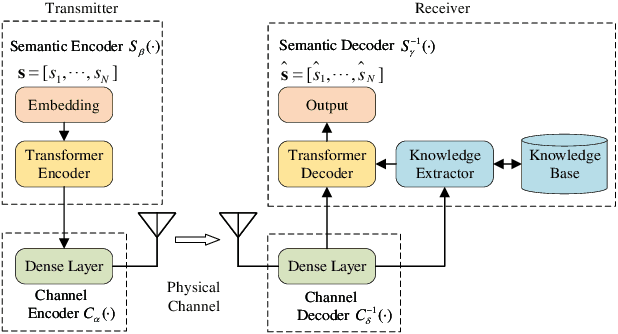
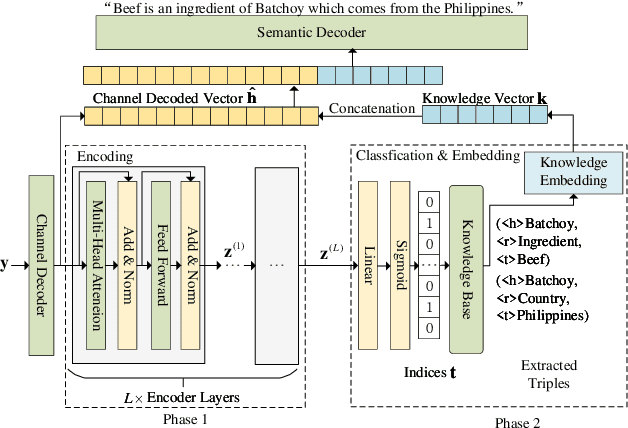
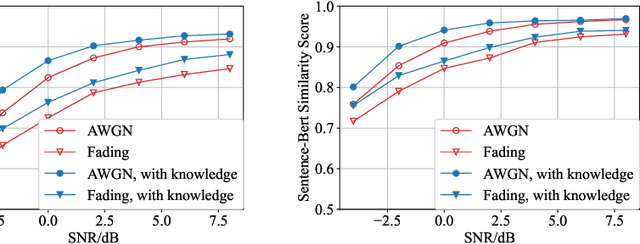
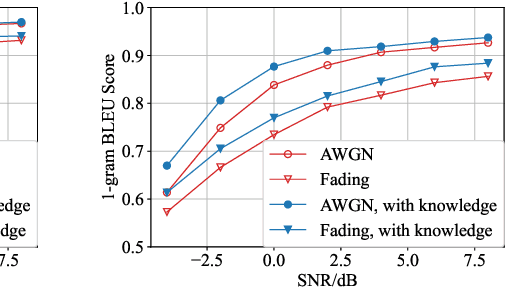
In recent years, with the rapid development of deep learning and natural language processing technologies, semantic communication has become a topic of great interest in the field of communication. Although existing deep learning based semantic communication approaches have shown many advantages, they still do not make sufficient use of prior knowledge. Moreover, most existing semantic communication methods focus on the semantic encoding at the transmitter side, while we believe that the semantic decoding capability of the receiver side should also be concerned. In this paper, we propose a knowledge enhanced semantic communication framework in which the receiver can more actively utilize the prior knowledge in the knowledge base for semantic reasoning and decoding, without extra modifications to the neural network structure of the transmitter. Specifically, we design a transformer-based knowledge extractor to find relevant factual triples for the received noisy signal. Extensive simulation results on the WebNLG dataset demonstrate that the proposed receiver yields superior performance on top of the knowledge graph enhanced decoding.
Robust Matrix Completion with Heavy-tailed Noise
Jun 09, 2022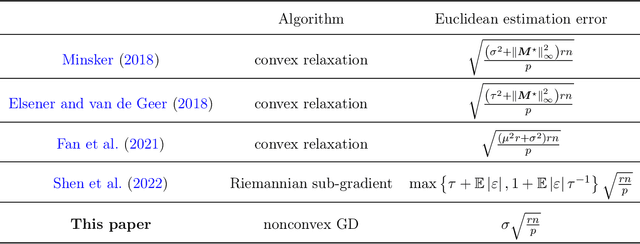
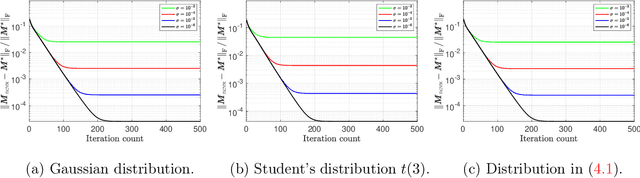
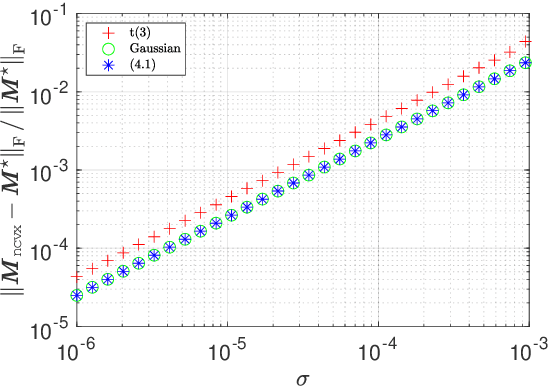
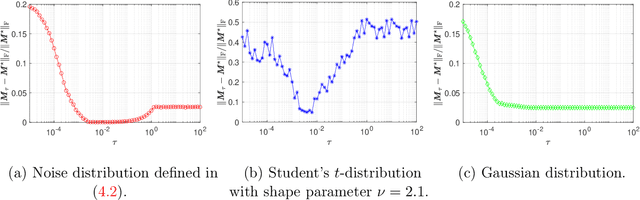
This paper studies low-rank matrix completion in the presence of heavy-tailed and possibly asymmetric noise, where we aim to estimate an underlying low-rank matrix given a set of highly incomplete noisy entries. Though the matrix completion problem has attracted much attention in the past decade, there is still lack of theoretical understanding when the observations are contaminated by heavy-tailed noises. Prior theory falls short of explaining the empirical results and is unable to capture the optimal dependence of the estimation error on the noise level. In this paper, we adopt an adaptive Huber loss to accommodate heavy-tailed noise, which is robust against large and possibly asymmetric errors when the parameter in the loss function is carefully designed to balance the Huberization biases and robustness to outliers. Then, we propose an efficient nonconvex algorithm via a balanced low-rank Burer-Monteiro matrix factorization and gradient decent with robust spectral initialization. We prove that under merely bounded second moment condition on the error distributions, rather than the sub-Gaussian assumption, the Euclidean error of the iterates generated by the proposed algorithm decrease geometrically fast until achieving a minimax-optimal statistical estimation error, which has the same order as that in the sub-Gaussian case. The key technique behind this significant advancement is a powerful leave-one-out analysis framework. The theoretical results are corroborated by our simulation studies.
Sample-Efficient Reinforcement Learning for Linearly-Parameterized MDPs with a Generative Model
May 28, 2021The curse of dimensionality is a widely known issue in reinforcement learning (RL). In the tabular setting where the state space $\mathcal{S}$ and the action space $\mathcal{A}$ are both finite, to obtain a nearly optimal policy with sampling access to a generative model, the minimax optimal sample complexity scales linearly with $|\mathcal{S}|\times|\mathcal{A}|$, which can be prohibitively large when $\mathcal{S}$ or $\mathcal{A}$ is large. This paper considers a Markov decision process (MDP) that admits a set of state-action features, which can linearly express (or approximate) its probability transition kernel. We show that a model-based approach (resp.$~$Q-learning) provably learns an $\varepsilon$-optimal policy (resp.$~$Q-function) with high probability as soon as the sample size exceeds the order of $\frac{K}{(1-\gamma)^{3}\varepsilon^{2}}$ (resp.$~$$\frac{K}{(1-\gamma)^{4}\varepsilon^{2}}$), up to some logarithmic factor. Here $K$ is the feature dimension and $\gamma\in(0,1)$ is the discount factor of the MDP. Both sample complexity bounds are provably tight, and our result for the model-based approach matches the minimax lower bound. Our results show that for arbitrarily large-scale MDP, both the model-based approach and Q-learning are sample-efficient when $K$ is relatively small, and hence the title of this paper.
Convex and Nonconvex Optimization Are Both Minimax-Optimal for Noisy Blind Deconvolution
Aug 04, 2020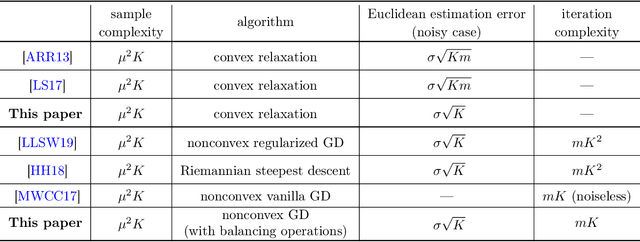
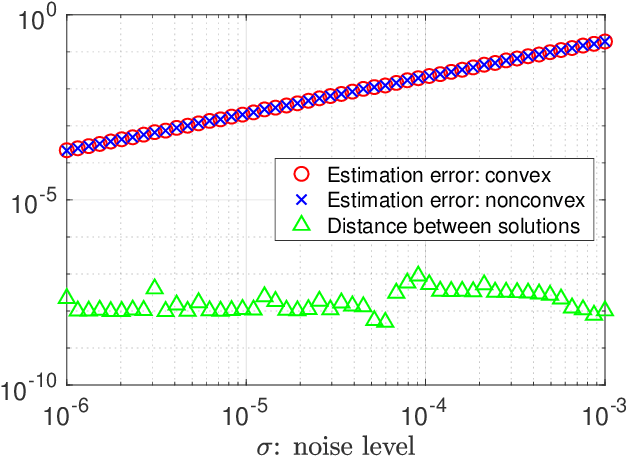
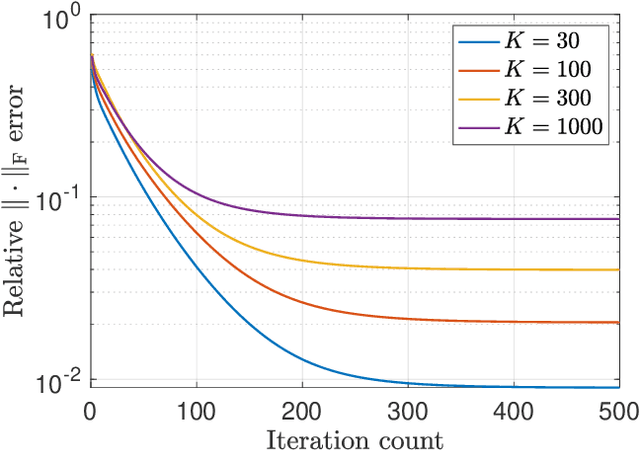
We investigate the effectiveness of convex relaxation and nonconvex optimization in solving bilinear systems of equations (a.k.a. blind deconvolution under a subspace model). Despite the wide applicability, the theoretical understanding about these two paradigms remains largely inadequate in the presence of noise. The current paper makes two contributions by demonstrating that: (1) convex relaxation achieves minimax-optimal statistical accuracy vis-\`a-vis random noise, and (2) a two-stage nonconvex algorithm attains minimax-optimal accuracy within a logarithmic number of iterations. Both results improve upon the state-of-the-art results by some factors that scale polynomially in the problem dimension.