 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopula-ResLogit: A Deep-Copula Framework for Unobserved Confounding Effects
Mar 11, 2026A key challenge in travel demand analysis is the presence of unobserved factors that may generate non-causal dependencies, obscuring the true causal effects. To address the issue, the study introduces a novel deep learning based fully interpretable joint modelling framework, Copula-ResLogit, which integrates the flexibility of Residual Neural Network (ResNet) architectures with the dependence capturing capabilities of copula models. This hybrid structure enables us to first detect unobserved confounding through traditional copula function based joint modelling and then mitigate these hidden associations by incorporating deep learning components. The study applies this framework to two case studies, including the relationship between stress levels and wait time of pedestrians when crossing mid block in VR and the dependencies between travel mode choice and travel distance in London travel behaviour data. Results show that Copula-ResLogit substantially reduces or eliminates the dependencies, demonstrating the ability of residual layers to account for hidden confounding effects.
From GEV to ResLogit: Spatially Correlated Discrete Choice Models for Pedestrian Movement Prediction
Mar 01, 2026High frequency pedestrian motion forecasting when interacting with autonomous vehicles (AVs) can be enhanced through the use of behavioural frameworks, such as discrete choice models, that can explicitly account for correlation among similar movement alternatives. We formulate the pedestrian next step choice as a spatial discrete choice defined by a grid of speed adjustment and heading change. Using naturalistic pedestrian-AV encounters from nuScenes and Argoverse 2 (1 sec decision interval), we estimate a multinomial logit baseline and four spatial generalized extreme value (GEV) specifications (SCL, GSCL, SCNL, and GSCNL). We then compare them to a residual neural network logit (ResLogit) model that learns cross alternative effects while retaining an interpretable linear utility component. Across the evaluated data, spatial GEV structures yield only marginal improvements over multinomial logit, whereas ResLogit achieves a substantially better fit and produces behaviourally coherent errors concentrated among neighbouring grid cells. The results suggest that in dense, high frequency spatial choice sets, learning based residual corrections can capture proximity induced correlation more effectively than analyst specified GEV nesting structures, while maintaining interpretability.
Enhancing Diversity and Feasibility: Joint Population Synthesis from Multi-source Data Using Generative Models
Feb 17, 2026Generating realistic synthetic populations is essential for agent-based models (ABM) in transportation and urban planning. Current methods face two major limitations. First, many rely on a single dataset or follow a sequential data fusion and generation process, which means they fail to capture the complex interplay between features. Second, these approaches struggle with sampling zeros (valid but unobserved attribute combinations) and structural zeros (infeasible combinations due to logical constraints), which reduce the diversity and feasibility of the generated data. This study proposes a novel method to simultaneously integrate and synthesize multi-source datasets using a Wasserstein Generative Adversarial Network (WGAN) with gradient penalty. This joint learning method improves both the diversity and feasibility of synthetic data by defining a regularization term (inverse gradient penalty) for the generator loss function. For the evaluation, we implement a unified evaluation metric for similarity, and place special emphasis on measuring diversity and feasibility through recall, precision, and the F1 score. Results show that the proposed joint approach outperforms the sequential baseline, with recall increasing by 7\% and precision by 15\%. Additionally, the regularization term further improves diversity and feasibility, reflected in a 10\% increase in recall and 1\% in precision. We assess similarity distributions using a five-metric score. The joint approach performs better overall, and reaches a score of 88.1 compared to 84.6 for the sequential method. Since synthetic populations serve as a key input for ABM, this multi-source generative approach has the potential to significantly enhance the accuracy and reliability of ABM.
Modelling Pedestrian Behaviour in Autonomous Vehicle Encounters Using Naturalistic Dataset
Feb 04, 2026Understanding how pedestrians adjust their movement when interacting with autonomous vehicles (AVs) is essential for improving safety in mixed traffic. This study examines micro-level pedestrian behaviour during midblock encounters in the NuScenes dataset using a hybrid discrete choice-machine learning framework based on the Residual Logit (ResLogit) model. The model incorporates temporal, spatial, kinematic, and perceptual indicators. These include relative speed, visual looming, remaining distance, and directional collision risk proximity (CRP) measures. Results suggest that some of these variables may meaningfully influence movement adjustments, although predictive performance remains moderate. Marginal effects and elasticities indicate strong directional asymmetries in risk perception, with frontal and rear CRP showing opposite influences. The remaining distance exhibits a possible mid-crossing threshold. Relative speed cues appear to have a comparatively less effect. These patterns may reflect multiple behavioural tendencies driven by both risk perception and movement efficiency.
Quantum Machine Learning in Transportation: A Case Study of Pedestrian Stress Modelling
Jul 01, 2025Quantum computing has opened new opportunities to tackle complex machine learning tasks, for instance, high-dimensional data representations commonly required in intelligent transportation systems. We explore quantum machine learning to model complex skin conductance response (SCR) events that reflect pedestrian stress in a virtual reality road crossing experiment. For this purpose, Quantum Support Vector Machine (QSVM) with an eight-qubit ZZ feature map and a Quantum Neural Network (QNN) using a Tree Tensor Network ansatz and an eight-qubit ZZ feature map, were developed on Pennylane. The dataset consists of SCR measurements along with features such as the response amplitude and elapsed time, which have been categorized into amplitude-based classes. The QSVM achieved good training accuracy, but had an overfitting problem, showing a low test accuracy of 45% and therefore impacting the reliability of the classification model. The QNN model reached a higher test accuracy of 55%, making it a better classification model than the QSVM and the classic versions.
A Coalition Game for On-demand Multi-modal 3D Automated Delivery System
Dec 23, 2024We introduce a multi-modal autonomous delivery optimization framework as a coalition game for a fleet of UAVs and ADRs operating in two overlaying networks to address last-mile delivery in urban environments, including high-density areas, road-based routing, and real-world operational challenges. The problem is defined as multiple depot pickup and delivery with time windows constrained over operational restrictions, such as vehicle battery limitation, precedence time window, and building obstruction. Subsequently, the coalition game theory is applied to investigate cooperation structures among the modes to capture how strategic collaboration among vehicles can improve overall routing efficiency. To do so, a generalized reinforcement learning model is designed to evaluate the cost-sharing and allocation to different coalitions for which sub-additive property and non-empty core exist. Our methodology leverages an end-to-end deep multi-agent policy gradient method augmented by a novel spatio-temporal adjacency neighbourhood graph attention network and transformer architecture using a heterogeneous edge-enhanced attention model. Conducting several numerical experiments on last-mile delivery applications, the result from the case study in the city of Mississauga shows that despite the incorporation of an extensive network in the graph for two modes and a complex training structure, the model addresses realistic operational constraints and achieves high-quality solutions compared with the existing transformer-based and heuristics methods and can perform well on non-homogeneous data distribution, generalizes well on the different scale and configuration, and demonstrate a robust performance under stochastic scenarios subject to wind speed and direction.
A deep causal inference model for fully-interpretable travel behaviour analysis
May 02, 2024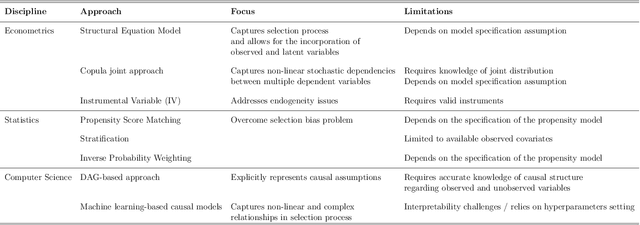
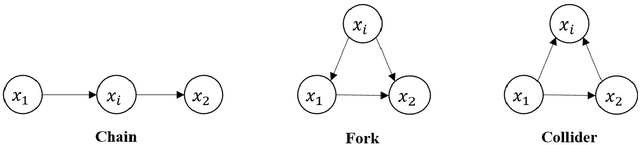
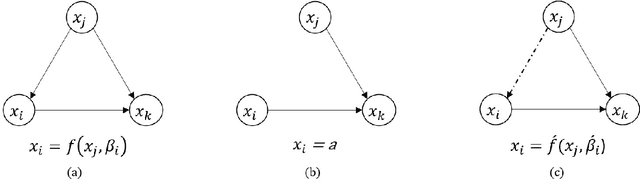
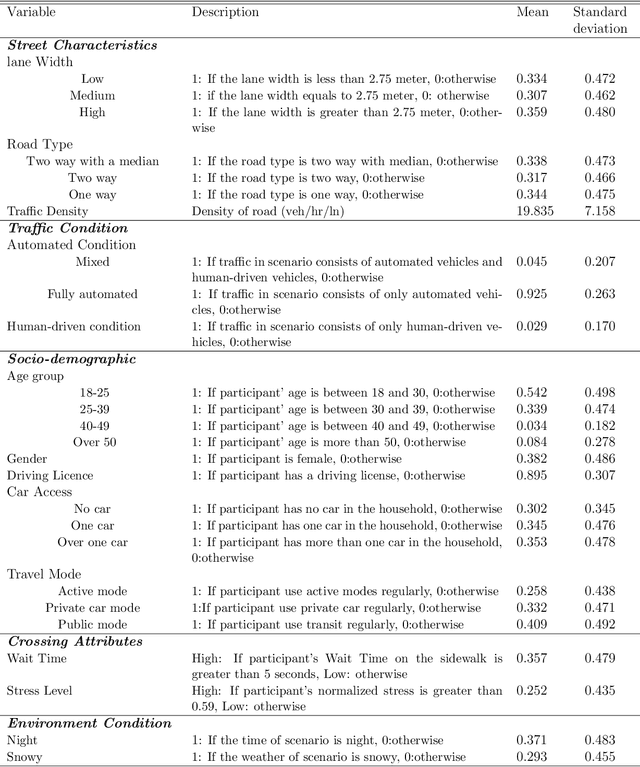
Transport policy assessment often involves causal questions, yet the causal inference capabilities of traditional travel behavioural models are at best limited. We present the deep CAusal infeRence mOdel for traveL behavIour aNAlysis (CAROLINA), a framework that explicitly models causality in travel behaviour, enhances predictive accuracy, and maintains interpretability by leveraging causal inference, deep learning, and traditional discrete choice modelling. Within this framework, we introduce a Generative Counterfactual model for forecasting human behaviour by adapting the Normalizing Flow method. Through the case studies of virtual reality-based pedestrian crossing behaviour, revealed preference travel behaviour from London, and synthetic data, we demonstrate the effectiveness of our proposed models in uncovering causal relationships, prediction accuracy, and assessing policy interventions. Our results show that intervention mechanisms that can reduce pedestrian stress levels lead to a 38.5% increase in individuals experiencing shorter waiting times. Reducing the travel distances in London results in a 47% increase in sustainable travel modes.
Attention-LSTM for Multivariate Traffic State Prediction on Rural Roads
Jan 06, 2023



Accurate traffic volume and speed prediction have a wide range of applications in transportation. It can result in useful and timely information for both travellers and transportation decision-makers. In this study, an Attention based Long Sort-Term Memory model (A-LSTM) is proposed to simultaneously predict traffic volume and speed in a critical rural road segmentation which connects Tehran to Chalus, the most tourist destination city in Iran. Moreover, this study compares the results of the A-LSTM model with the Long Short-Term Memory (LSTM) model. Both models show acceptable performance in predicting speed and flow. However, the A-LSTM model outperforms the LSTM in 5 and 15-minute intervals. In contrast, there is no meaningful difference between the two models for the 30-minute time interval. By comparing the performance of the models based on different time horizons, the 15-minute horizon model outperforms the others by reaching the lowest Mean Square Error (MSE) loss of 0.0032, followed by the 30 and 5-minutes horizons with 0.004 and 0.0051, respectively. In addition, this study compares the results of the models based on two transformations of temporal categorical input variables, one-hot or cyclic, for the 15-minute time interval. The results demonstrate that both LSTM and A-LSTM with cyclic feature encoding outperform those with one-hot feature encoding.
Debiased machine learning for estimating the causal effect of urban traffic on pedestrian crossing behaviour
Dec 21, 2022Before the transition of AVs to urban roads and subsequently unprecedented changes in traffic conditions, evaluation of transportation policies and futuristic road design related to pedestrian crossing behavior is of vital importance. Recent studies analyzed the non-causal impact of various variables on pedestrian waiting time in the presence of AVs. However, we mainly investigate the causal effect of traffic density on pedestrian waiting time. We develop a Double/Debiased Machine Learning (DML) model in which the impact of confounders variable influencing both a policy and an outcome of interest is addressed, resulting in unbiased policy evaluation. Furthermore, we try to analyze the effect of traffic density by developing a copula-based joint model of two main components of pedestrian crossing behavior, pedestrian stress level and waiting time. The copula approach has been widely used in the literature, for addressing self-selection problems, which can be classified as a causality analysis in travel behavior modeling. The results obtained from copula approach and DML are compared based on the effect of traffic density. In DML model structure, the standard error term of density parameter is lower than copula approach and the confidence interval is considerably more reliable. In addition, despite the similar sign of effect, the copula approach estimates the effect of traffic density lower than DML, due to the spurious effect of confounders. In short, the DML model structure can flexibly adjust the impact of confounders by using machine learning algorithms and is more reliable for planning future policies.
Robustness Analysis of Deep Learning Models for Population Synthesis
Nov 23, 2022



Deep generative models have become useful for synthetic data generation, particularly population synthesis. The models implicitly learn the probability distribution of a dataset and can draw samples from a distribution. Several models have been proposed, but their performance is only tested on a single cross-sectional sample. The implementation of population synthesis on single datasets is seen as a drawback that needs further studies to explore the robustness of the models on multiple datasets. While comparing with the real data can increase trust and interpretability of the models, techniques to evaluate deep generative models' robustness for population synthesis remain underexplored. In this study, we present bootstrap confidence interval for the deep generative models, an approach that computes efficient confidence intervals for mean errors predictions to evaluate the robustness of the models to multiple datasets. Specifically, we adopt the tabular-based Composite Travel Generative Adversarial Network (CTGAN) and Variational Autoencoder (VAE), to estimate the distribution of the population, by generating agents that have tabular data using several samples over time from the same study area. The models are implemented on multiple travel diaries of Montreal Origin- Destination Survey of 2008, 2013, and 2018 and compare the predictive performance under varying sample sizes from multiple surveys. Results show that the predictive errors of CTGAN have narrower confidence intervals indicating its robustness to multiple datasets of the varying sample sizes when compared to VAE. Again, the evaluation of model robustness against varying sample size shows a minimal decrease in model performance with decrease in sample size. This study directly supports agent-based modelling by enabling finer synthetic generation of populations in a reliable environment.