 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Effectively Predicting Autism Spectrum Disorder Using an Ensemble of Classifiers
Sep 02, 2022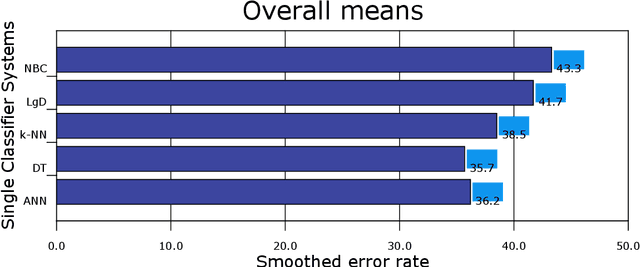
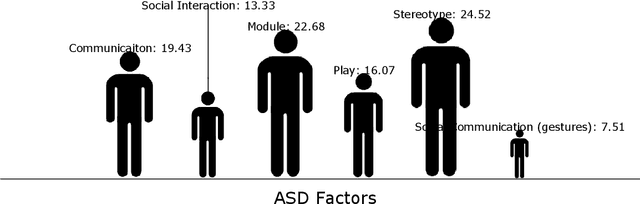
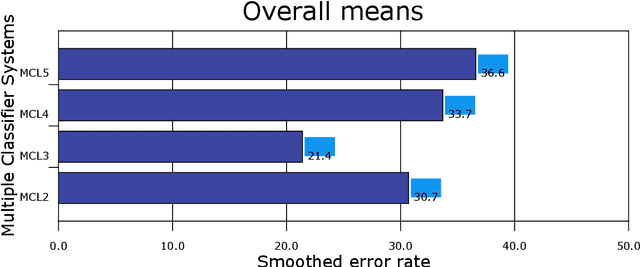
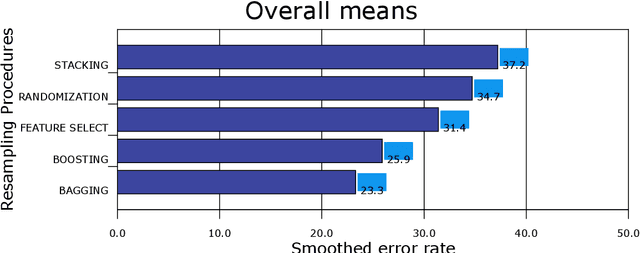
An ensemble of classifiers combines several single classifiers to deliver a final prediction or classification decision. An increasingly provoking question is whether such systems can outperform the single best classifier. If so, what form of an ensemble of classifiers (also known as multiple classifier learning systems or multiple classifiers) yields the most significant benefits in the size or diversity of the ensemble itself? Given that the tests used to detect autism traits are time-consuming and costly, developing a system that will provide the best outcome and measurement of autism spectrum disorder (ASD) has never been critical. In this paper, several single and later multiple classifiers learning systems are evaluated in terms of their ability to predict and identify factors that influence or contribute to ASD for early screening purposes. A dataset of behavioural data and robot-enhanced therapy of 3,000 sessions and 300 hours, recorded from 61 children are utilised for this task. Simulation results show the superior predictive performance of multiple classifier learning systems (especially those with three classifiers per ensemble) compared to individual classifiers, with bagging and boosting achieving excellent results. It also appears that social communication gestures remain the critical contributing factor to the ASD problem among children.
Missing Data Prediction and Classification: The Use of Auto-Associative Neural Networks and Optimization Algorithms
Mar 21, 2014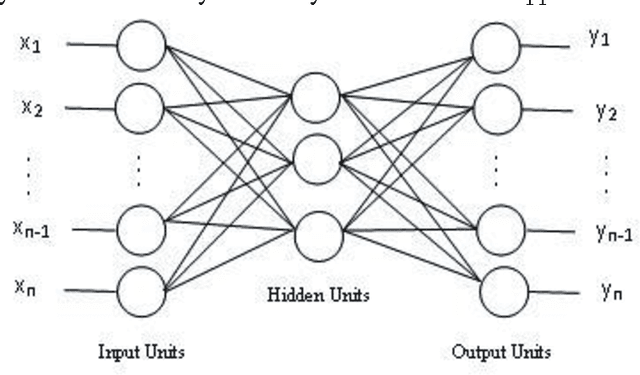
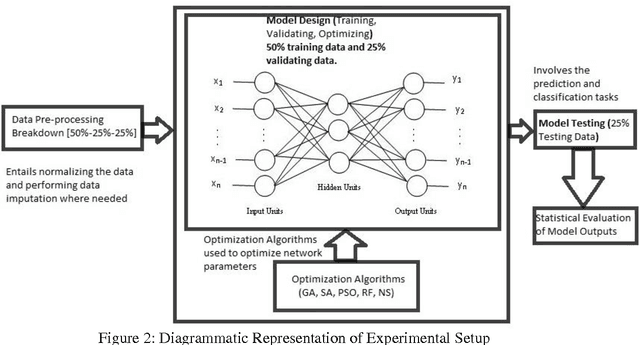
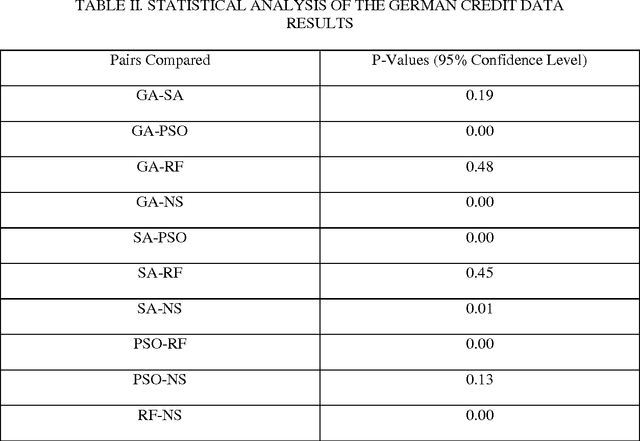
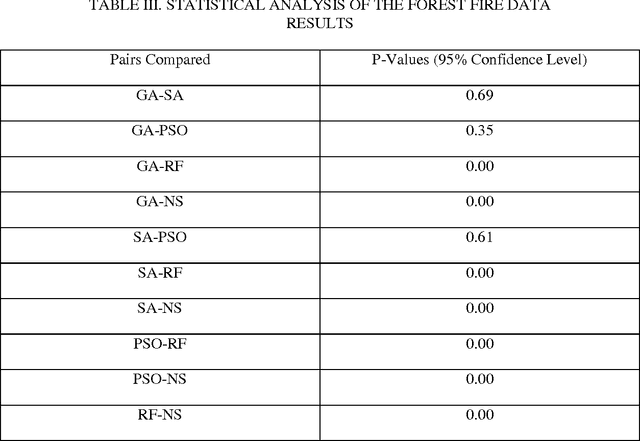
This paper presents methods which are aimed at finding approximations to missing data in a dataset by using optimization algorithms to optimize the network parameters after which prediction and classification tasks can be performed. The optimization methods that are considered are genetic algorithm (GA), simulated annealing (SA), particle swarm optimization (PSO), random forest (RF) and negative selection (NS) and these methods are individually used in combination with auto-associative neural networks (AANN) for missing data estimation and the results obtained are compared. The methods suggested use the optimization algorithms to minimize an error function derived from training the auto-associative neural network during which the interrelationships between the inputs and the outputs are obtained and stored in the weights connecting the different layers of the network. The error function is expressed as the square of the difference between the actual observations and predicted values from an auto-associative neural network. In the event of missing data, all the values of the actual observations are not known hence, the error function is decomposed to depend on the known and unknown variable values. Multi-layer perceptron (MLP) neural network is employed to train the neural networks using the scaled conjugate gradient (SCG) method. Prediction accuracy is determined by mean squared error (MSE), root mean squared error (RMSE), mean absolute error (MAE), and correlation coefficient (r) computations. Accuracy in classification is obtained by plotting ROC curves and calculating the areas under these. Analysis of results depicts that the approach using RF with AANN produces the most accurate predictions and classifications while on the other end of the scale is the approach which entails using NS with AANN.
Improving the performance of the ripper in insurance risk classification : A comparitive study using feature selection
Aug 23, 2011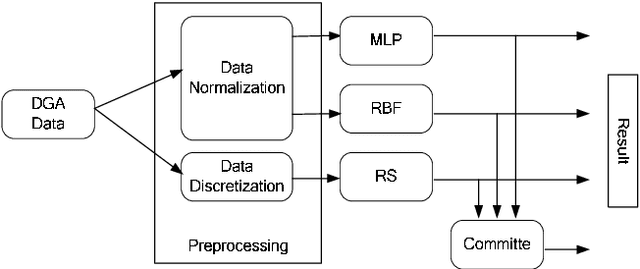
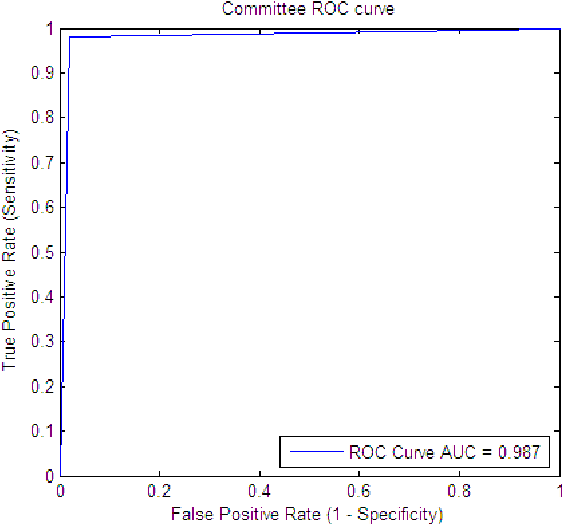
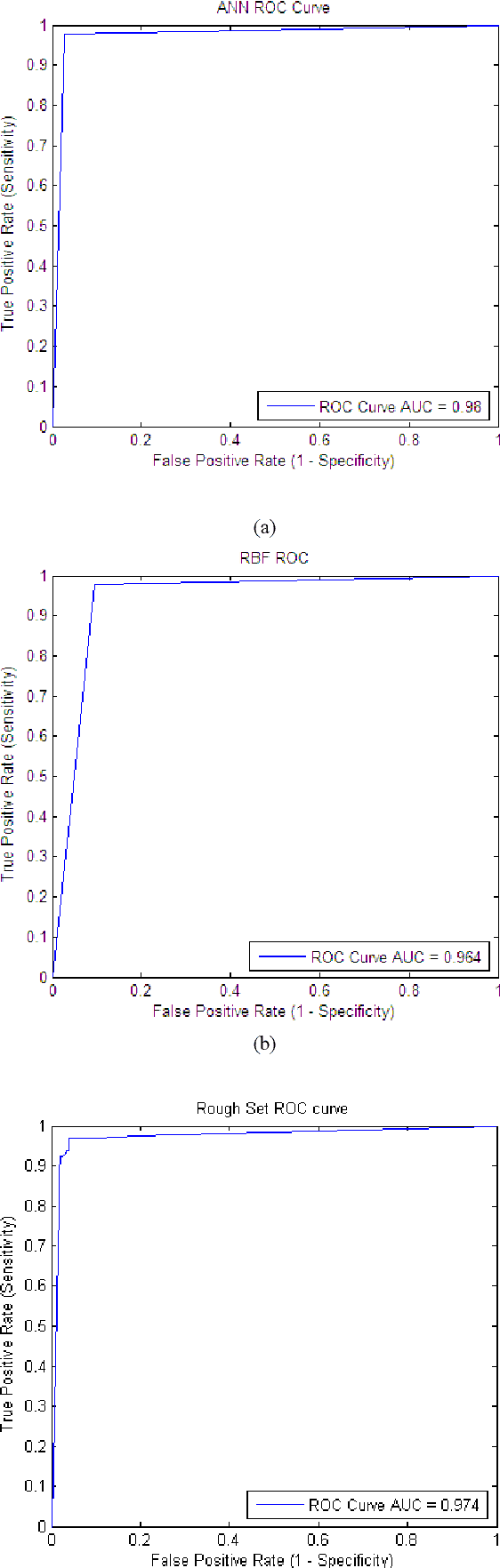
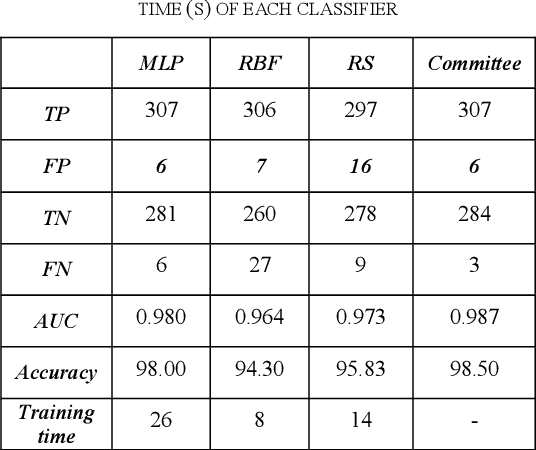
The Ripper algorithm is designed to generate rule sets for large datasets with many features. However, it was shown that the algorithm struggles with classification performance in the presence of missing data. The algorithm struggles to classify instances when the quality of the data deteriorates as a result of increasing missing data. In this paper, a feature selection technique is used to help improve the classification performance of the Ripper model. Principal component analysis and evidence automatic relevance determination techniques are used to improve the performance. A comparison is done to see which technique helps the algorithm improve the most. Training datasets with completely observable data were used to construct the model and testing datasets with missing values were used for measuring accuracy. The results showed that principal component analysis is a better feature selection for the Ripper in improving the classification performance.