 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Data Prediction and Classification: The Use of Auto-Associative Neural Networks and Optimization Algorithms
Paper and Code
Mar 21, 2014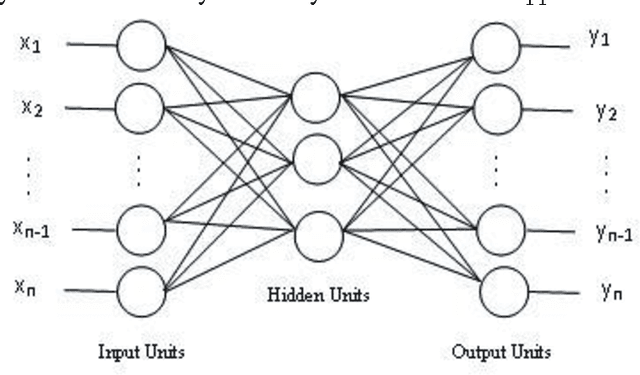
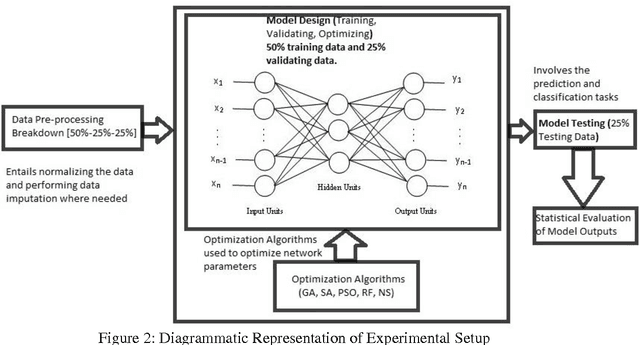
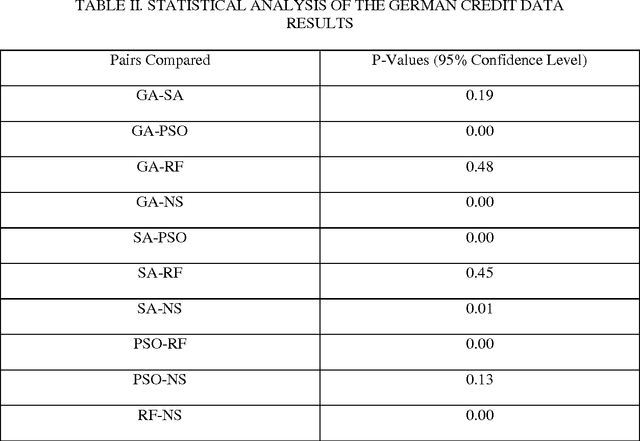
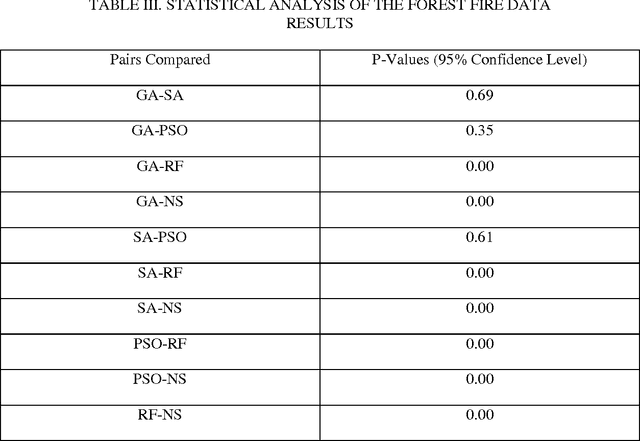
This paper presents methods which are aimed at finding approximations to missing data in a dataset by using optimization algorithms to optimize the network parameters after which prediction and classification tasks can be performed. The optimization methods that are considered are genetic algorithm (GA), simulated annealing (SA), particle swarm optimization (PSO), random forest (RF) and negative selection (NS) and these methods are individually used in combination with auto-associative neural networks (AANN) for missing data estimation and the results obtained are compared. The methods suggested use the optimization algorithms to minimize an error function derived from training the auto-associative neural network during which the interrelationships between the inputs and the outputs are obtained and stored in the weights connecting the different layers of the network. The error function is expressed as the square of the difference between the actual observations and predicted values from an auto-associative neural network. In the event of missing data, all the values of the actual observations are not known hence, the error function is decomposed to depend on the known and unknown variable values. Multi-layer perceptron (MLP) neural network is employed to train the neural networks using the scaled conjugate gradient (SCG) method. Prediction accuracy is determined by mean squared error (MSE), root mean squared error (RMSE), mean absolute error (MAE), and correlation coefficient (r) computations. Accuracy in classification is obtained by plotting ROC curves and calculating the areas under these. Analysis of results depicts that the approach using RF with AANN produces the most accurate predictions and classifications while on the other end of the scale is the approach which entails using NS with AANN.