 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the performance of the ripper in insurance risk classification : A comparitive study using feature selection
Aug 23, 2011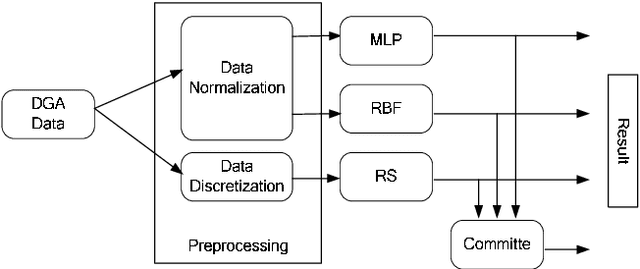
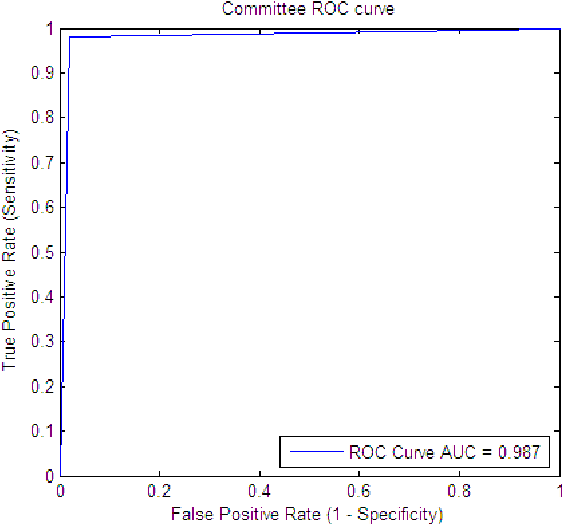
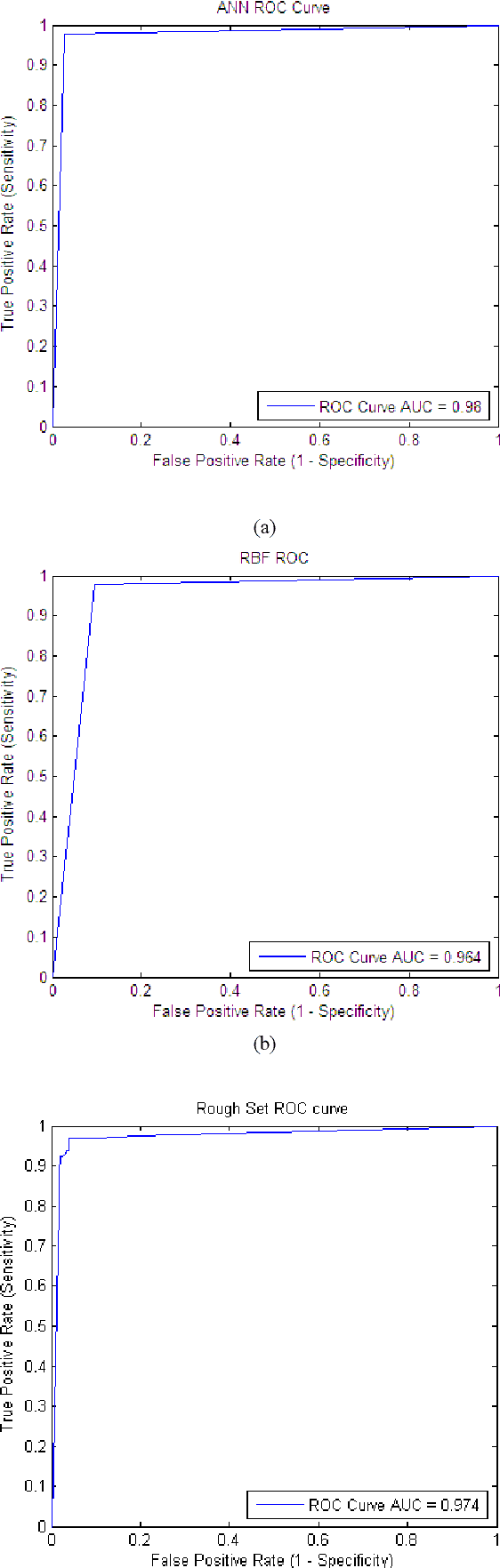
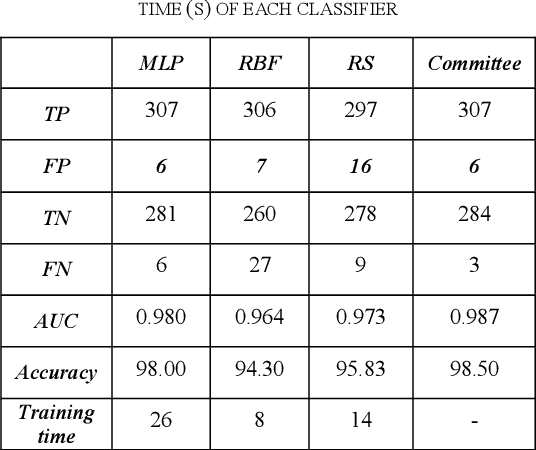
The Ripper algorithm is designed to generate rule sets for large datasets with many features. However, it was shown that the algorithm struggles with classification performance in the presence of missing data. The algorithm struggles to classify instances when the quality of the data deteriorates as a result of increasing missing data. In this paper, a feature selection technique is used to help improve the classification performance of the Ripper model. Principal component analysis and evidence automatic relevance determination techniques are used to improve the performance. A comparison is done to see which technique helps the algorithm improve the most. Training datasets with completely observable data were used to construct the model and testing datasets with missing values were used for measuring accuracy. The results showed that principal component analysis is a better feature selection for the Ripper in improving the classification performance.