 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDueling Deep Q-Network for Unsupervised Inter-frame Eye Movement Correction in Optical Coherence Tomography Volumes
Jul 03, 2020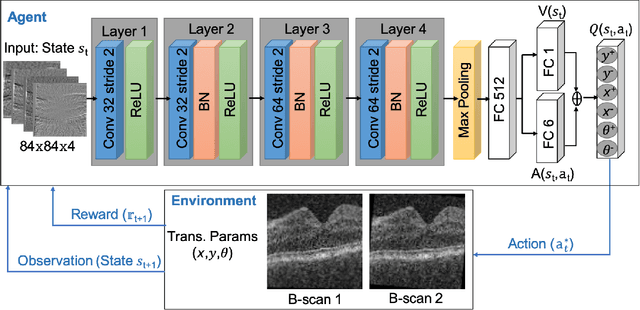
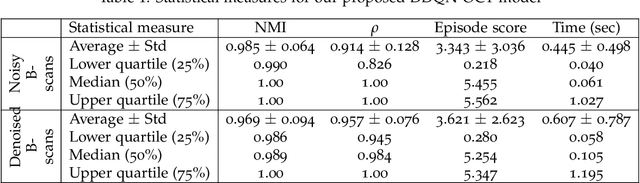
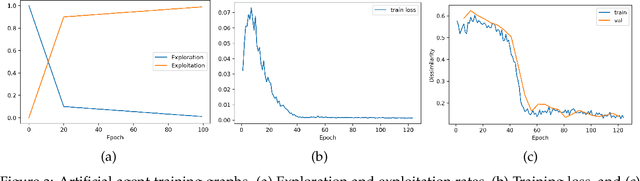
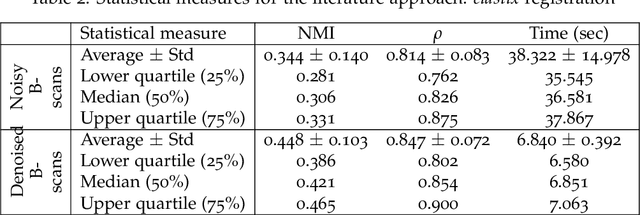
In optical coherence tomography (OCT) volumes of retina, the sequential acquisition of the individual slices makes this modality prone to motion artifacts, misalignments between adjacent slices being the most noticeable. Any distortion in OCT volumes can bias structural analysis and influence the outcome of longitudinal studies. On the other hand, presence of speckle noise that is characteristic of this imaging modality, leads to inaccuracies when traditional registration techniques are employed. Also, the lack of a well-defined ground truth makes supervised deep-learning techniques ill-posed to tackle the problem. In this paper, we tackle these issues by using deep reinforcement learning to correct inter-frame movements in an unsupervised manner. Specifically, we use dueling deep Q-network to train an artificial agent to find the optimal policy, i.e. a sequence of actions, that best improves the alignment by maximizing the sum of reward signals. Instead of relying on the ground-truth of transformation parameters to guide the rewarding system, for the first time, we use a combination of intensity based image similarity metrics. Further, to avoid the agent bias towards speckle noise, we ensure the agent can see retinal layers as part of the interacting environment. For quantitative evaluation, we simulate the eye movement artifacts by applying 2D rigid transformations on individual B-scans. The proposed model achieves an average of 0.985 and 0.914 for normalized mutual information and correlation coefficient, respectively. We also compare our model with elastix intensity based medical image registration approach, where significant improvement is achieved by our model for both noisy and denoised volumes.