 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning
Sep 11, 2023



The Mixture of Experts (MoE) is a widely known neural architecture where an ensemble of specialized sub-models optimizes overall performance with a constant computational cost. However, conventional MoEs pose challenges at scale due to the need to store all experts in memory. In this paper, we push MoE to the limit. We propose extremely parameter-efficient MoE by uniquely combining MoE architecture with lightweight experts.Our MoE architecture outperforms standard parameter-efficient fine-tuning (PEFT) methods and is on par with full fine-tuning by only updating the lightweight experts -- less than 1% of an 11B parameters model. Furthermore, our method generalizes to unseen tasks as it does not depend on any prior task knowledge. Our research underscores the versatility of the mixture of experts architecture, showcasing its ability to deliver robust performance even when subjected to rigorous parameter constraints. Our code used in all the experiments is publicly available here: https://github.com/for-ai/parameter-efficient-moe.
Link Prediction via Generalized Coupled Tensor Factorisation
Aug 30, 2012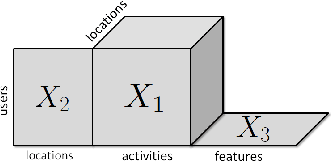
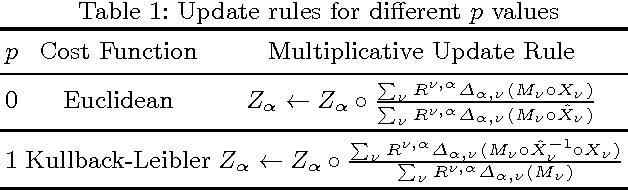
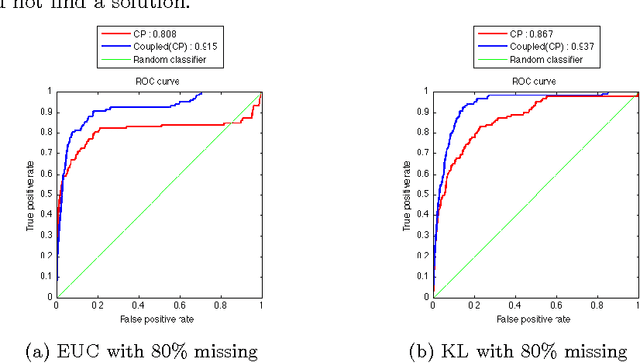
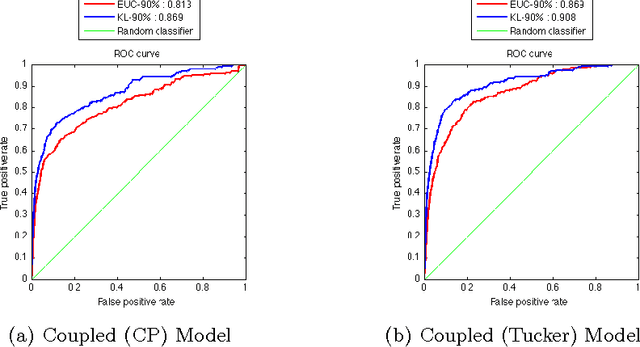
This study deals with the missing link prediction problem: the problem of predicting the existence of missing connections between entities of interest. We address link prediction using coupled analysis of relational datasets represented as heterogeneous data, i.e., datasets in the form of matrices and higher-order tensors. We propose to use an approach based on probabilistic interpretation of tensor factorisation models, i.e., Generalised Coupled Tensor Factorisation, which can simultaneously fit a large class of tensor models to higher-order tensors/matrices with com- mon latent factors using different loss functions. Numerical experiments demonstrate that joint analysis of data from multiple sources via coupled factorisation improves the link prediction performance and the selection of right loss function and tensor model is crucial for accurately predicting missing links.