 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSMEC - Distributed Sparse Machines for Extreme Multi-label Classification
Sep 08, 2016



Extreme multi-label classification refers to supervised multi-label learning involving hundreds of thousands or even millions of labels. Datasets in extreme classification exhibit fit to power-law distribution, i.e. a large fraction of labels have very few positive instances in the data distribution. Most state-of-the-art approaches for extreme multi-label classification attempt to capture correlation among labels by embedding the label matrix to a low-dimensional linear sub-space. However, in the presence of power-law distributed extremely large and diverse label spaces, structural assumptions such as low rank can be easily violated. In this work, we present DiSMEC, which is a large-scale distributed framework for learning one-versus-rest linear classifiers coupled with explicit capacity control to control model size. Unlike most state-of-the-art methods, DiSMEC does not make any low rank assumptions on the label matrix. Using double layer of parallelization, DiSMEC can learn classifiers for datasets consisting hundreds of thousands labels within few hours. The explicit capacity control mechanism filters out spurious parameters which keep the model compact in size, without losing prediction accuracy. We conduct extensive empirical evaluation on publicly available real-world datasets consisting upto 670,000 labels. We compare DiSMEC with recent state-of-the-art approaches, including - SLEEC which is a leading approach for learning sparse local embeddings, and FastXML which is a tree-based approach optimizing ranking based loss function. On some of the datasets, DiSMEC can significantly boost prediction accuracies - 10% better compared to SLECC and 15% better compared to FastXML, in absolute terms.
Telling cause from effect in deterministic linear dynamical systems
Mar 04, 2015


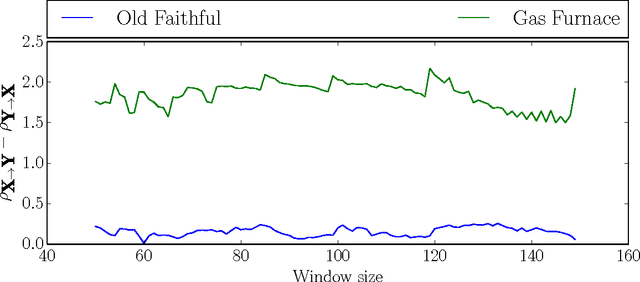
Inferring a cause from its effect using observed time series data is a major challenge in natural and social sciences. Assuming the effect is generated by the cause trough a linear system, we propose a new approach based on the hypothesis that nature chooses the "cause" and the "mechanism that generates the effect from the cause" independent of each other. We therefore postulate that the power spectrum of the time series being the cause is uncorrelated with the square of the transfer function of the linear filter generating the effect. While most causal discovery methods for time series mainly rely on the noise, our method relies on asymmetries of the power spectral density properties that can be exploited even in the context of deterministic systems. We describe mathematical assumptions in a deterministic model under which the causal direction is identifiable with this approach. We also discuss the method's performance under the additive noise model and its relationship to Granger causality. Experiments show encouraging results on synthetic as well as real-world data. Overall, this suggests that the postulate of Independence of Cause and Mechanism is a promising principle for causal inference on empirical time series.