 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailed retinal vessel segmentation without human annotations using simulated optical coherence tomography angiographs
Jun 19, 2023Optical coherence tomography angiography (OCTA) is a non-invasive imaging modality that can acquire high-resolution volumes of the retinal vasculature and aid the diagnosis of ocular, neurological and cardiac diseases. Segmentation of the visible blood vessels is a common first step when extracting quantitative biomarkers from these images. Classical segmentation algorithms based on thresholding are strongly affected by image artifacts and limited signal-to-noise ratio. The use of modern, deep learning-based segmentation methods has been inhibited by a lack of large datasets with detailed annotations of the blood vessels. To address this issue, recent work has employed transfer learning, where a segmentation network is trained on synthetic OCTA images and is then applied to real data. However, the previously proposed simulation models are incapable of faithfully modeling the retinal vasculature and do not provide effective domain adaptation. Because of this, current methods are not able to fully segment the retinal vasculature, in particular the smallest capillaries. In this work, we present a lightweight simulation of the retinal vascular network based on space colonization for faster and more realistic OCTA synthesis. Moreover, we introduce three contrast adaptation pipelines to decrease the domain gap between real and artificial images. We demonstrate the superior performance of our approach in extensive quantitative and qualitative experiments on three public datasets that compare our method to traditional computer vision algorithms and supervised training using human annotations. Finally, we make our entire pipeline publicly available, including the source code, pretrained models, and a large dataset of synthetic OCTA images.
Physiology-based simulation of the retinal vasculature enables annotation-free segmentation of OCT angiographs
Jul 22, 2022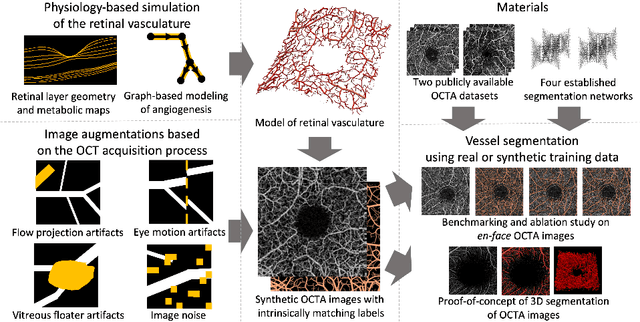
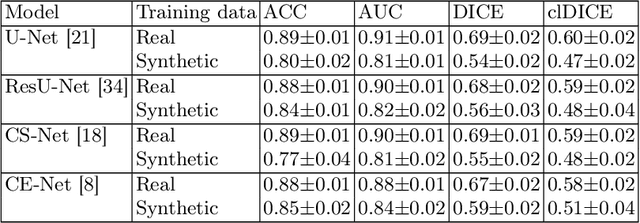
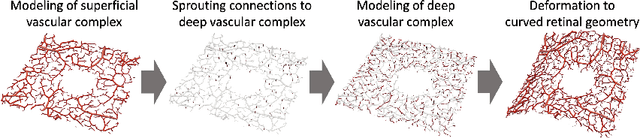
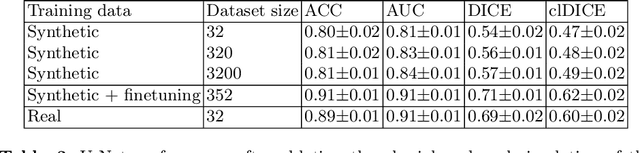
Optical coherence tomography angiography (OCTA) can non-invasively image the eye's circulatory system. In order to reliably characterize the retinal vasculature, there is a need to automatically extract quantitative metrics from these images. The calculation of such biomarkers requires a precise semantic segmentation of the blood vessels. However, deep-learning-based methods for segmentation mostly rely on supervised training with voxel-level annotations, which are costly to obtain. In this work, we present a pipeline to synthesize large amounts of realistic OCTA images with intrinsically matching ground truth labels; thereby obviating the need for manual annotation of training data. Our proposed method is based on two novel components: 1) a physiology-based simulation that models the various retinal vascular plexuses and 2) a suite of physics-based image augmentations that emulate the OCTA image acquisition process including typical artifacts. In extensive benchmarking experiments, we demonstrate the utility of our synthetic data by successfully training retinal vessel segmentation algorithms. Encouraged by our method's competitive quantitative and superior qualitative performance, we believe that it constitutes a versatile tool to advance the quantitative analysis of OCTA images.