 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Implementation of Computing Mean Average Precision
Jun 19, 2022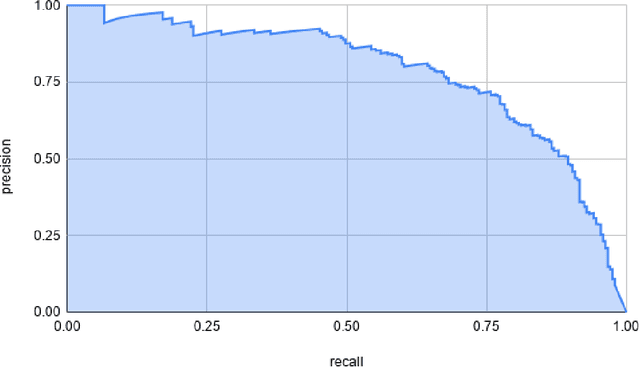


Mean Average Precision (mAP) has been widely used for evaluating the quality of object detectors, but an efficient implementation is still absent. Current implementations can only count true positives (TP's) and false positives (FP's) for one class at a time by looping through every detection of that class sequentially. Not only are these approaches inefficient, but they are also inconvenient for reporting validation mAP during training. We propose a parallelized alternative that can process mini-batches of detected bounding boxes (DTBB's) and ground truth bounding boxes (GTBB's) as inference goes such that mAP can be instantly calculated after inference is finished. Loops and control statements in sequential implementations are replaced with extensive uses of broadcasting, masking, and indexing. All operators involved are supported by popular machine learning frameworks such as PyTorch and TensorFlow. As a result, our implementation is much faster and can easily fit into typical training routines. A PyTorch version of our implementation is available at https://github.com/bwangca/fast-map.
Forecasting SQL Query Cost at Twitter
Apr 12, 2022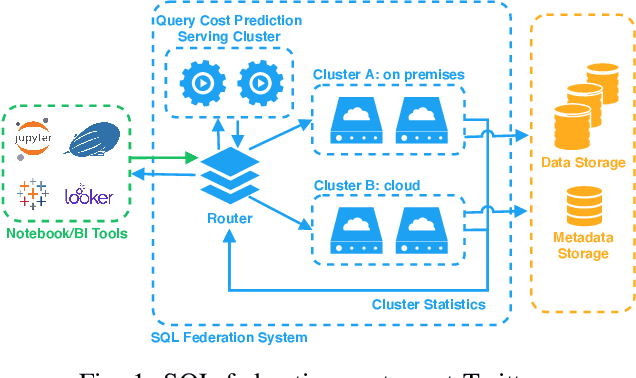
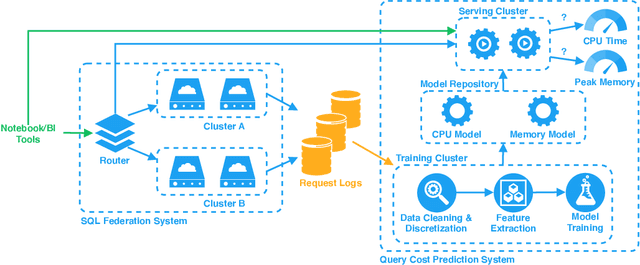
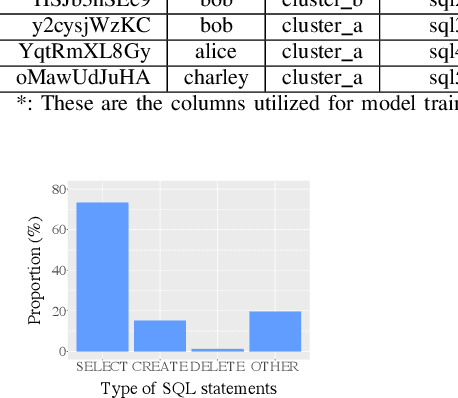
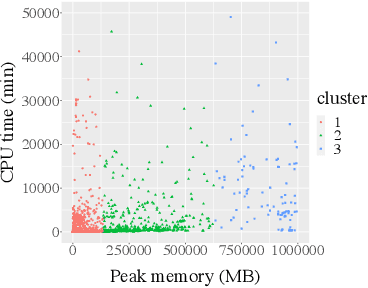
With the advent of the Big Data era, it is usually computationally expensive to calculate the resource usages of a SQL query with traditional DBMS approaches. Can we estimate the cost of each query more efficiently without any computation in a SQL engine kernel? Can machine learning techniques help to estimate SQL query resource utilization? The answers are yes. We propose a SQL query cost predictor service, which employs machine learning techniques to train models from historical query request logs and rapidly forecasts the CPU and memory resource usages of online queries without any computation in a SQL engine. At Twitter, infrastructure engineers are maintaining a large-scale SQL federation system across on-premises and cloud data centers for serving ad-hoc queries. The proposed service can help to improve query scheduling by relieving the issue of imbalanced online analytical processing (OLAP) workloads in the SQL engine clusters. It can also assist in enabling preemptive scaling. Additionally, the proposed approach uses plain SQL statements for the model training and online prediction, indicating it is both hardware and software-agnostic. The method can be generalized to broader SQL systems and heterogeneous environments. The models can achieve 97.9\% accuracy for CPU usage prediction and 97\% accuracy for memory usage prediction.
Feedbackward Decoding for Semantic Segmentation
Aug 22, 2019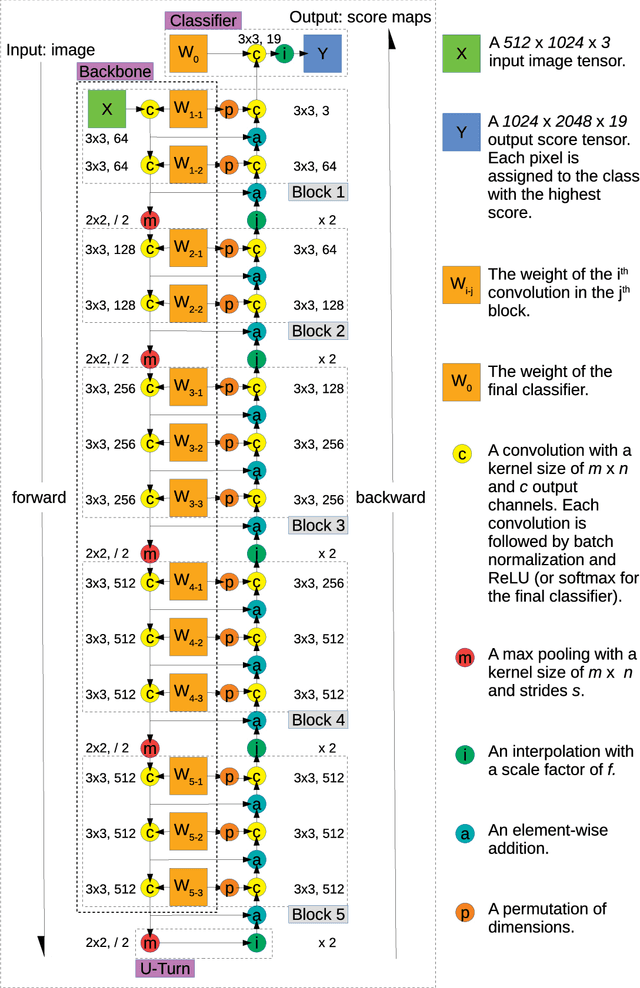
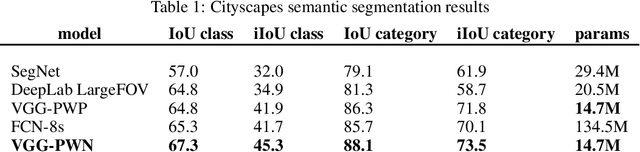
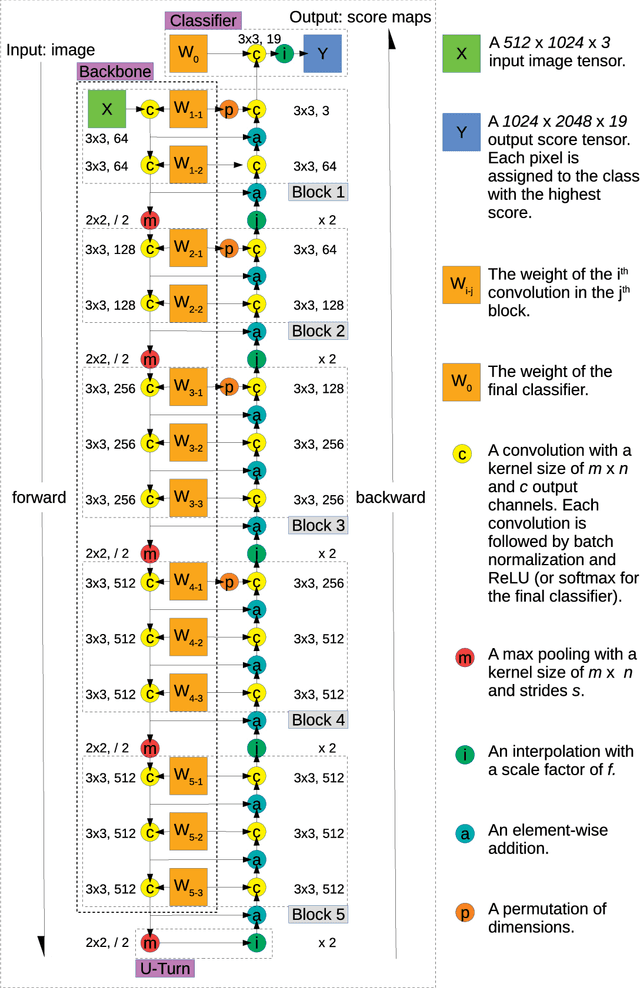
We propose a novel approach for semantic segmentation that uses an encoder in the reverse direction to decode. Many semantic segmentation networks adopt a feedforward encoder-decoder architecture. Typically, an input is first downsampled by the encoder to extract high-level semantic features and continues to be fed forward through the decoder module to recover low-level spatial clues. Our method works in an alternative direction that lets information flow backward from the last layer of the encoder towards the first. The encoder performs encoding in the forward pass and the same network performs decoding in the backward pass. Therefore, the encoder itself is also the decoder. Compared to conventional encoder-decoder architectures, ours doesn't require additional layers for decoding and further reuses the encoder weights thereby reducing the total number of parameters required for processing. We show by using only the 13 convolutional layers from VGG-16 plus one tiny classification layer, our model significantly outperforms other frequently cited models that are also adapted from VGG-16. On the Cityscapes semantic segmentation benchmark, our model uses 50.0% less parameters than SegNet and achieves an 18.1% higher "IoU class" score; it uses 28.3% less parameters than DeepLab LargeFOV and the achieved "IoU class" score is 3.9% higher; it uses 89.1% fewer parameters than FCN-8s and the achieved "IoU class" score is 3.1% higher. Our code will be publicly available on Github later.