 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Appropriate Facial Reaction Generation in Dyadic Interaction Settings: What, Why and How?
Feb 14, 2023

According to the Stimulus Organism Response (SOR) theory, all human behavioral reactions are stimulated by context, where people will process the received stimulus and produce an appropriate reaction. This implies that in a specific context for a given input stimulus, a person can react differently according to their internal state and other contextual factors. Analogously, in dyadic interactions, humans communicate using verbal and nonverbal cues, where a broad spectrum of listeners' non-verbal reactions might be appropriate for responding to a specific speaker behaviour. There already exists a body of work that investigated the problem of automatically generating an appropriate reaction for a given input. However, none attempted to automatically generate multiple appropriate reactions in the context of dyadic interactions and evaluate the appropriateness of those reactions using objective measures. This paper starts by defining the facial Multiple Appropriate Reaction Generation (fMARG) task for the first time in the literature and proposes a new set of objective evaluation metrics to evaluate the appropriateness of the generated reactions. The paper subsequently introduces a framework to predict, generate, and evaluate multiple appropriate facial reactions.
AssembleRL: Learning to Assemble Furniture from Their Point Clouds
Sep 15, 2022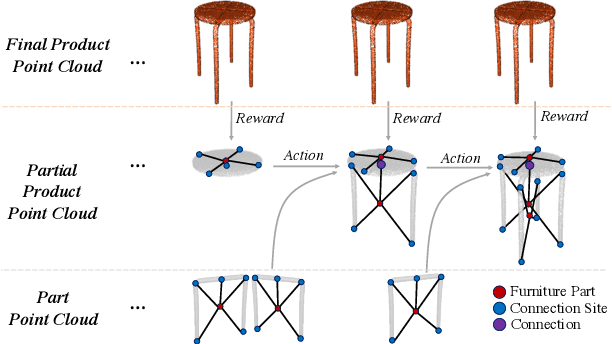
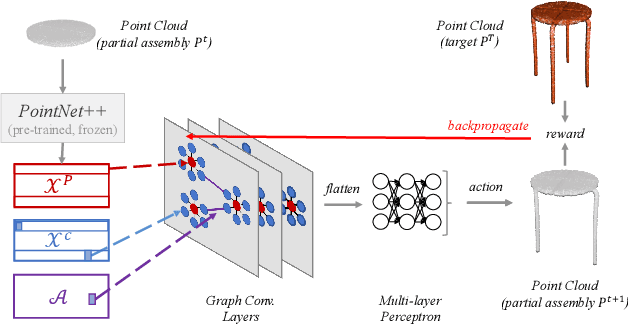
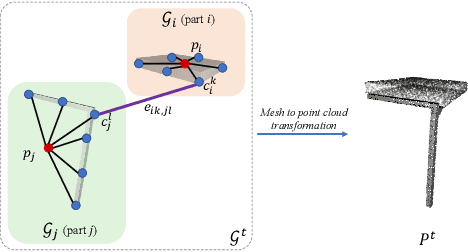
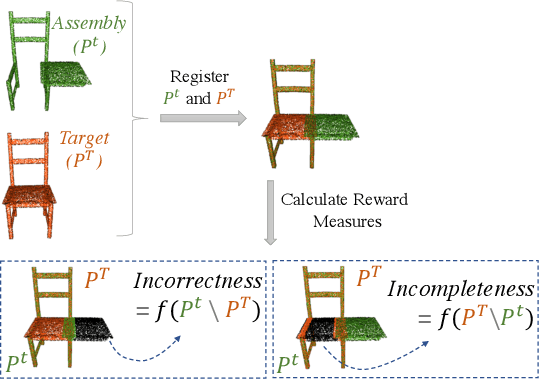
The rise of simulation environments has enabled learning-based approaches for assembly planning, which is otherwise a labor-intensive and daunting task. Assembling furniture is especially interesting since furniture are intricate and pose challenges for learning-based approaches. Surprisingly, humans can solve furniture assembly mostly given a 2D snapshot of the assembled product. Although recent years have witnessed promising learning-based approaches for furniture assembly, they assume the availability of correct connection labels for each assembly step, which are expensive to obtain in practice. In this paper, we alleviate this assumption and aim to solve furniture assembly with as little human expertise and supervision as possible. To be specific, we assume the availability of the assembled point cloud, and comparing the point cloud of the current assembly and the point cloud of the target product, obtain a novel reward signal based on two measures: Incorrectness and incompleteness. We show that our novel reward signal can train a deep network to successfully assemble different types of furniture. Code and networks available here: https://github.com/METU-KALFA/AssembleRL