 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASANet: Asymmetric Semantic Aligning Network for RGB and SAR image land cover classification
Dec 03, 2024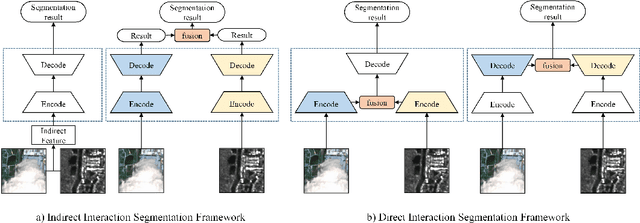

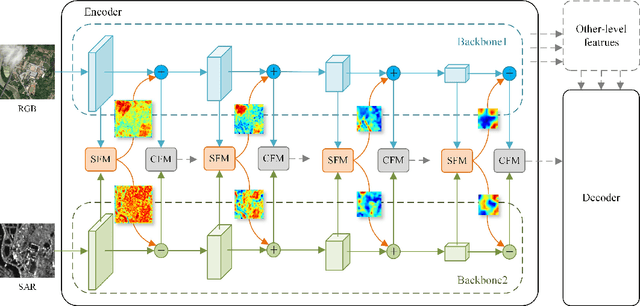

Synthetic Aperture Radar (SAR) images have proven to be a valuable cue for multimodal Land Cover Classification (LCC) when combined with RGB images. Most existing studies on cross-modal fusion assume that consistent feature information is necessary between the two modalities, and as a result, they construct networks without adequately addressing the unique characteristics of each modality. In this paper, we propose a novel architecture, named the Asymmetric Semantic Aligning Network (ASANet), which introduces asymmetry at the feature level to address the issue that multi-modal architectures frequently fail to fully utilize complementary features. The core of this network is the Semantic Focusing Module (SFM), which explicitly calculates differential weights for each modality to account for the modality-specific features. Furthermore, ASANet incorporates a Cascade Fusion Module (CFM), which delves deeper into channel and spatial representations to efficiently select features from the two modalities for fusion. Through the collaborative effort of these two modules, the proposed ASANet effectively learns feature correlations between the two modalities and eliminates noise caused by feature differences. Comprehensive experiments demonstrate that ASANet achieves excellent performance on three multimodal datasets. Additionally, we have established a new RGB-SAR multimodal dataset, on which our ASANet outperforms other mainstream methods with improvements ranging from 1.21% to 17.69%. The ASANet runs at 48.7 frames per second (FPS) when the input image is 256x256 pixels. The source code are available at https://github.com/whu-pzhang/ASANet
HGDNet: A Height-Hierarchy Guided Dual-Decoder Network for Single View Building Extraction and Height Estimation
Aug 10, 2023


Unifying the correlative single-view satellite image building extraction and height estimation tasks indicates a promising way to share representations and acquire generalist model for large-scale urban 3D reconstruction. However, the common spatial misalignment between building footprints and stereo-reconstructed nDSM height labels incurs degraded performance on both tasks. To address this issue, we propose a Height-hierarchy Guided Dual-decoder Network (HGDNet) to estimate building height. Under the guidance of synthesized discrete height-hierarchy nDSM, auxiliary height-hierarchical building extraction branch enhance the height estimation branch with implicit constraints, yielding an accuracy improvement of more than 6% on the DFC 2023 track2 dataset. Additional two-stage cascade architecture is adopted to achieve more accurate building extraction. Experiments on the DFC 2023 Track 2 dataset shows the superiority of the proposed method in building height estimation ({\delta}1:0.8012), instance extraction (AP50:0.7730), and the final average score 0.7871 ranks in the first place in test phase.
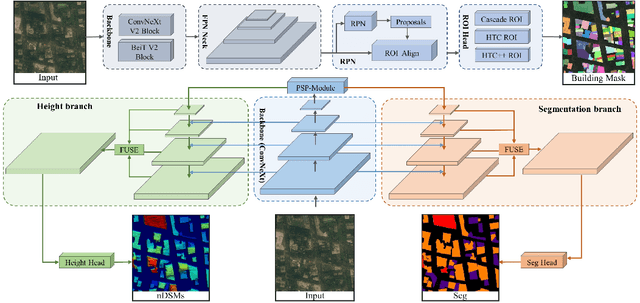
Fine-grained building roof instance segmentation based on domain adapted pretraining and composite dual-backbone
Aug 10, 2023The diversity of building architecture styles of global cities situated on various landforms, the degraded optical imagery affected by clouds and shadows, and the significant inter-class imbalance of roof types pose challenges for designing a robust and accurate building roof instance segmentor. To address these issues, we propose an effective framework to fulfill semantic interpretation of individual buildings with high-resolution optical satellite imagery. Specifically, the leveraged domain adapted pretraining strategy and composite dual-backbone greatly facilitates the discriminative feature learning. Moreover, new data augmentation pipeline, stochastic weight averaging (SWA) training and instance segmentation based model ensemble in testing are utilized to acquire additional performance boost. Experiment results show that our approach ranks in the first place of the 2023 IEEE GRSS Data Fusion Contest (DFC) Track 1 test phase ($mAP_{50}$:50.6\%). Note-worthily, we have also explored the potential of multimodal data fusion with both optical satellite imagery and SAR data.