 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-aggregated spatiotemporal spine surface estimation for wearable patch ultrasound volumetric imaging
Nov 11, 2022Clear identification of bone structures is crucial for ultrasound-guided lumbar interventions, but it can be challenging due to the complex shapes of the self-shadowing vertebra anatomy and the extensive background speckle noise from the surrounding soft tissue structures. Therefore, we propose to use a patch-like wearable ultrasound solution to capture the reflective bone surfaces from multiple imaging angles and create 3D bone representations for interventional guidance. In this work, we will present our method for estimating the vertebra bone surfaces by using a spatiotemporal U-Net architecture learning from the B-Mode image and aggregated feature maps of hand-crafted filters. The methods are evaluated on spine phantom image data collected by our proposed miniaturized wearable "patch" ultrasound device, and the results show that a significant improvement on baseline method can be achieved with promising accuracy. Equipped with this surface estimation framework, our wearable ultrasound system can potentially provide intuitive and accurate interventional guidance for clinicians in augmented reality setting.
Automatic ultrasound vessel segmentation with deep spatiotemporal context learning
Nov 03, 2021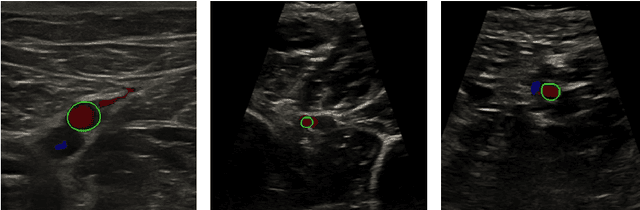
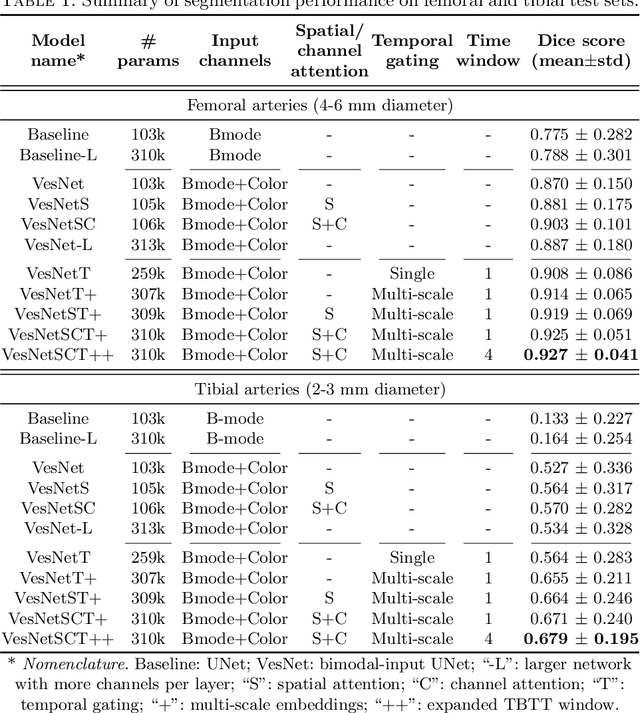
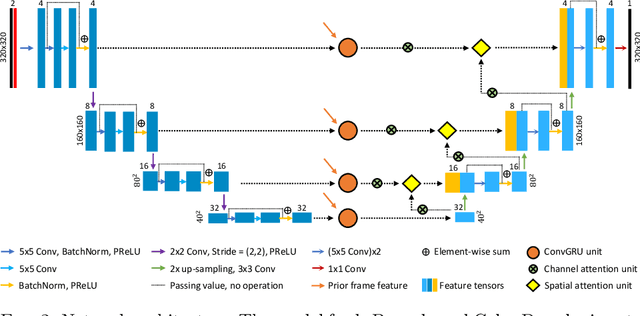
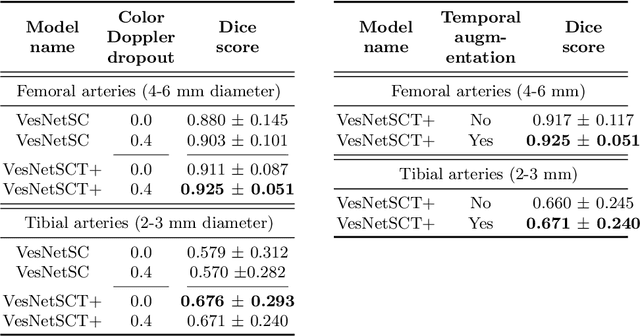
Accurate, real-time segmentation of vessel structures in ultrasound image sequences can aid in the measurement of lumen diameters and assessment of vascular diseases. This, however, remains a challenging task, particularly for extremely small vessels that are difficult to visualize. We propose to leverage the rich spatiotemporal context available in ultrasound to improve segmentation of small-scale lower-extremity arterial vasculature. We describe efficient deep learning methods that incorporate temporal, spatial, and feature-aware contextual embeddings at multiple resolution scales while jointly utilizing information from B-mode and Color Doppler signals. Evaluating on femoral and tibial artery scans performed on healthy subjects by an expert ultrasonographer, and comparing to consensus expert ground-truth annotations of inner lumen boundaries, we demonstrate real-time segmentation using the context-aware models and show that they significantly outperform comparable baseline approaches.